Zillow: Optimistic Concurrency with Write-Time Timestamps

Dan Podhola is a Principal Software Engineer at Zillow, the most-visited real estate website in the U.S. He specializes in performance tuning of high-throughput backend database services. We were fortunate to have him speak at our Scylla Summit on Optimistic Concurrency with Write-Time Timestamps. If you wish, you can watch the full presentation on-demand:
WATCH THE ZILLOW PRESENTATION NOW
Dan began by describing his team’s role at Zillow. They are responsible for processing property and listing records — what is for sale or rent — and mapping those to a common Zillow property IDs, then translating different message types into a common interchange format so their teams can talk to each other using the same type of data.
They are also responsible for deciding what’s best to display. He showed a high-level diagram of what happens when they receive a message from one of their data providers. It needs to be translated into a common output format.

“We fetch other data that we know about that property that’s also in that same format. We bundle that data together and choose a winner — I use the term ‘winner’ lightly here — and we send that bundle data out to our consumers.”
The Problem: Out-of-Order Data
The biggest problem that Zillow faced, and the reason for Dan’s talk, was that they have a highly threaded application. They receive message queues from two different data producers, and the messages can be received out of order. They cannot go backwards in time to look into the data, or, as Dan put it, “it would cause bad things to happen.” It would throw off analytics and many other systems that consume the data.
As an example, they might get a for-sale listing message that says a certain property has changed price. If they processed that sold message first, but then processed a price change which showed it was still for sale, it would create confusion.
It might require manual intervention to identify and fix, such as from a consumer complaining. “That’s not a great experience for anybody.” Especially not their analytics team.

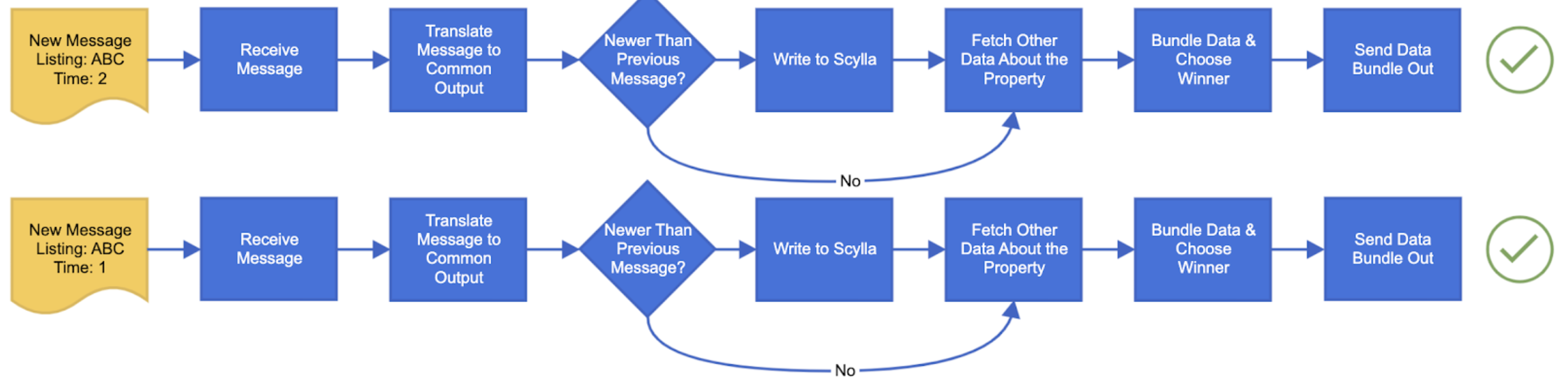
This is the visual representation Dan showed to depict the problem. The message that was generated at time 2 has a later timestamp and should be accepted and processed. “It goes all the way through the system. At that point, we publish it. It’s golden. That’s what we want.” However an earlier message from Time 1 might be received from a backfilled queue. If it goes through the whole system and gets published, it’s already out-of-date.
“What’s the solution? You may already be thinking, ‘Well, just don’t write the older message.’ That’s a good solution and I agree with you. So I drew a diagram here that shows a decision tree that I added in the middle. It says ‘if the message is newer than the previous message then write it, otherwise don’t — just skip to the fetch.’”
Problems with Other Methods
“Now you might be wondering, ‘Well, why fetch it all? Just stop there.” If you’re grabbing a transaction lock and doing this in a SQL server type of way, that’s a good solution.
However, Dan then differentiated why you wouldn’t just implement this in the traditional SQL manner of doing things. That is, spinning up a SQL server instance, grabbing a lock and running a stored procedure that returns a result code. “Was this written? Was this not written? Then act on that information.”
The problem with the traditional SQL method, Dan pointed out, is the locking, “you don’t have the scalability of something like Scylla.” He also pointed out that one could also implement this with Scylla’s Lightweight Transactions (LWT), but those require three round-trip times of a normal transaction, and Zillow wanted to avoid them for performance reasons.
“So the second method is ‘store everything.’ That means we get every record and we store it, no matter when it was given to us. Then we have the application layer pull all the data at once. It does the filtering and then does action on it.”
However, this does lead to data bloat, “The problem with that is we have to trim data because we don’t need it all. We just didn’t want to have to deal with running a trim job or paying to store all that data we just didn’t need. Our system just needs to store the latest, most current state.”
Insert Using Timestamp
“Then finally there’s the ‘overwrite only-if-newer, but without a lock method.’”
The downside with this, Dan pointed out, is if you don’t know yet if your write has written to the database, actually committed the write, then you have to republish the results every single time.
Dan then showed the following CQL statement:
INSERT … USING TIMESTAMP = ?“‘USING TIMESTAMP’ allows you to replace the timestamp that Scylla uses [by default] to decide which record to write, or not write, as it were. This is normally a great thing that you would want. You have a couple of nodes. Two messages come in. Those messages have different timestamps — though only the latest one will survive [based on] the consistency.”
“You can use USING TIMESTAMP to supply your own timestamp, and that’s what we’re doing here. This allows us to pick a timestamp that we decided as the best arbiter for what is written and what is not. The upside is that it solves our problem without having to use LWT or an application lock, [or a cache] like Redis.”
“The downside is that we don’t know if the record was actually written to the database. So the workaround for that is to pretend that the record always has been written.”

“We have to ensure that we get the latest documents back when we ask for all the documents. For us to do that we have to write it QUORUM and we have to read it QUORUM — for at least just these two statements. This allows us to avoid conditions where you might write just to a single node and then you fetch — and that should even be in QUORUM. If you don’t write a QUORUM you might pull from the other two nodes and get an older result set, which would mean that we could flicker and send an old result that we don’t want. QUORUM here solves that problem. We didn’t use ALL because if one of the nodes goes down we wouldn’t be able to process at all.”
Putting It All Together
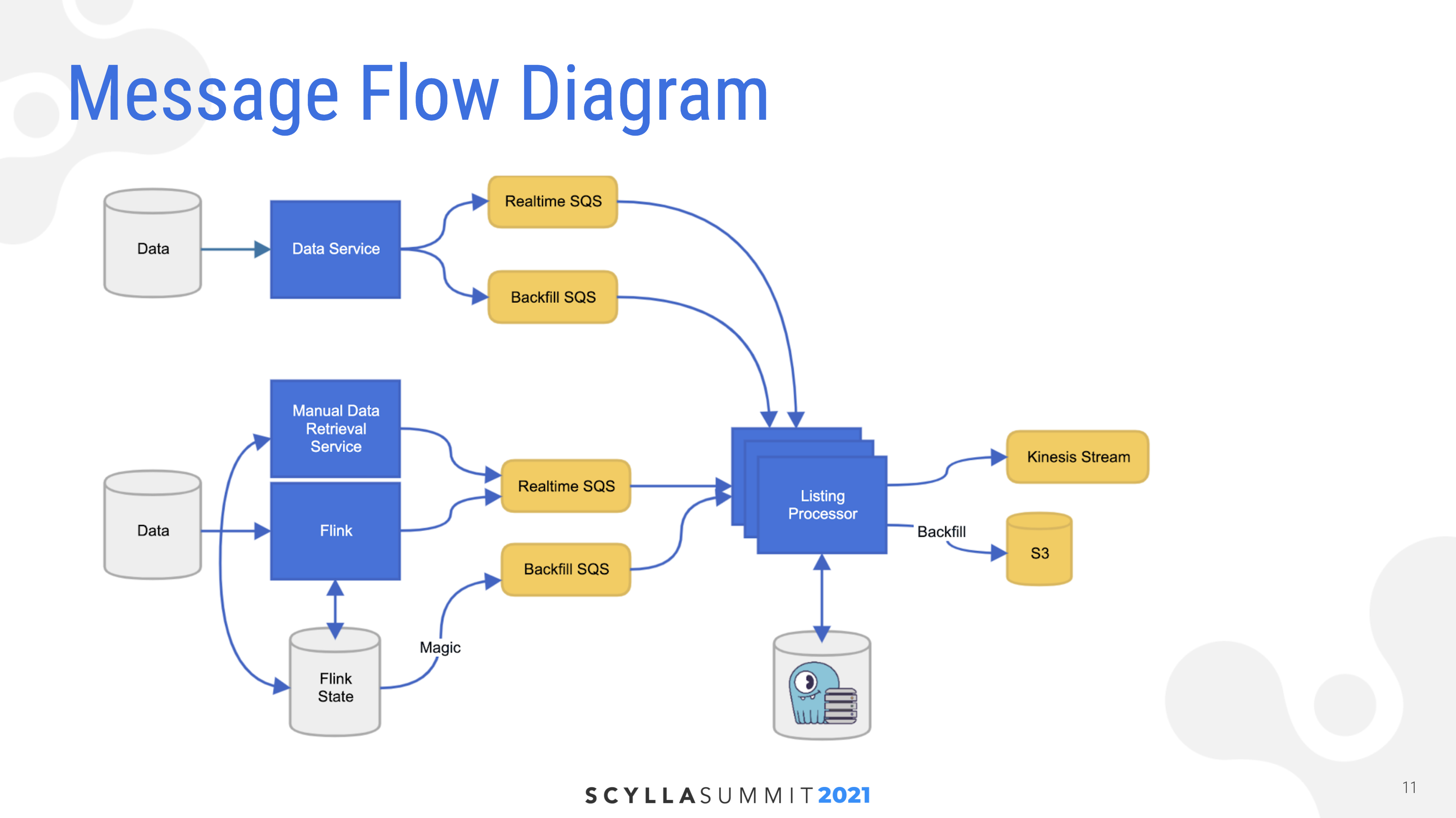
“This is my message flow diagram. You can see at the top there’s a Data Service that has its own data set. It publishes to its own real time, its own backfill queue. There’s a more complicated service down at the bottom that mostly streams data in from Flink but has a manual data retrieval service that allows people to correct issues or manually request individual messages or properties. And then there’s a Flink state on the bottom that uses some magic to fill a backfill queue.”
“Another interesting thing here is that the listing processor — which is the service that my team has written — takes messages from those queues. It actually publishes them differently. It’ll publish real-time messages to a Kinesis stream and it’ll publish backfill messages to an s3 bucket.”
“We have some additional required producer actions here. These different systems operate in different ways and might theoretically have older timestamps. Backfill would be a great example. You generate a message. It goes into your backfill bucket and then you publish a real time change. Well, if we happen to be processing the real time change, and then the backfill later, that message would have an older timestamp.”
“Now if they were produced at roughly the same time and their system had different ways internally of how it generated that message then the message generation time could be wrong.
So we’ve required our producers to give us the timestamp in their messages that is the time that they fetch the data from their database. Because their database is their arbiter of what’s the most recent record that was in there that they send to us.”
“This also solves our DELETE scenario. If we were to manually DELETE a record from Scylla using one of Scylla’s timestamps, in order for us to get a fresher message on the DELETE we have to ask for a fresh message timestamp. Going to that service that requests the individual messages we would get a fresh timestamp that’s newer than the one that Scylla has for its DELETE.
Performance
“Our performance has been great,” Dan said. For Zillow’s normal real-time workloads Scylla has been ample. “We run on three i3.4xlarge’s for Scylla. Our service actually runs on a single c5.xlarge. It has 25 consumer threads. It autoscales on EBS, so if we happen to have a small spike in real time we’ll scale up to three c5.xlarge’s, turn through that data and we’ll be done. The real beauty of this is even just on three nodes [for Scylla] we can scale up to 35 of the c5.xlarge instances and we’ll process over 6,500 records per second plus the real-time workload.”
“No one will even notice that we’re processing the entirety of Zillow’s property and listings data in order to correct some data issue or change a business rule. The beauty of that is we can process the entirety of the data at Zillow that we care about in less than a business day and, again, no performance hit to real-time data.”
If you want to check out Scylla for yourself, you can download it now, or if you want to discuss your needs, feel free to contact us privately, or join our community on Slack.