How ShareChat Cut Recommendation Engine Costs 90%, Step by Step
From managed Google Cloud services to ScyllaDB, Redpanda, Flink, and beyond
The engineering team at ShareChat, India’s largest social media platform, decided it was time to take a hard look at the mounting costs of running their recommendation system.
The content deduplication service at its core was built on Google Cloud’s managed stack: Bigtable, Dataflow, Pub/Sub. That foundation helped ShareChat get up and running rapidly. However, costs spiked as they scaled to 300 million users generating billions of daily interactions. And the 40 ms P99 latency was not ideal for customer-facing apps.
If you’ve followed ScyllaDB for a while, you probably know that the ShareChat engineers never shy away from monster scale engineering challenges. For example:
- Pulling off a zero-downtime migration of massive clusters (65+ TB, over 1M ops.sec)
- Using Kafka Streams for real-time, windowed aggregation of massive engagement events while keeping ScyllaDB writes minimal and reads sub-millisecond
- Scaling their ScyllaDB-based feature store 1000X without scaling the database – and then making it 10X cheaper
Spoiler: They pulled off yet another masterful optimization with their deduplication service (90% cost reduction while lowering P99 latency from 40 ms to 8 ms). And again, they generously shared their strategies and lessons learned with the community – this time at Monster Scale Summit 2025.
Watch Andrei Manakov (Senior Staff Software Engineer at ShareChat) detail the step-by-step optimizations, or read the highlights below.
Note: Monster Scale Summit is a free + virtual conference on extreme scale engineering, with a focus on data-intensive applications. Learn from leaders like antirez, creator of Redis; Camille Fournier, author of “The Manager’s Path” and “Platform Engineering”; Martin Kleppmann, author of “Designing Data-Intensive Applications” and more than 50 others, including engineers from Discord, Disney, Pinterest, Rivian, LinkedIn, and Freshworks. ShareChat will be delivering two talks this year.
Register and join us March 11-12 for some lively chats.
Background
ShareChat is India’s largest social media platform, with more than 180 million monthly active users and 2.5 billion interactions per month. Its sister product, Moj, is a short-video app similar to TikTok. Moj has over 160 million monthly active users and 6 billion video plays daily.
Both apps rely on a smart feed of personalized recommendations. Effective deduplication within that feed is critical for engagement. If users keep seeing the same items over and over again, they’re less likely to return.
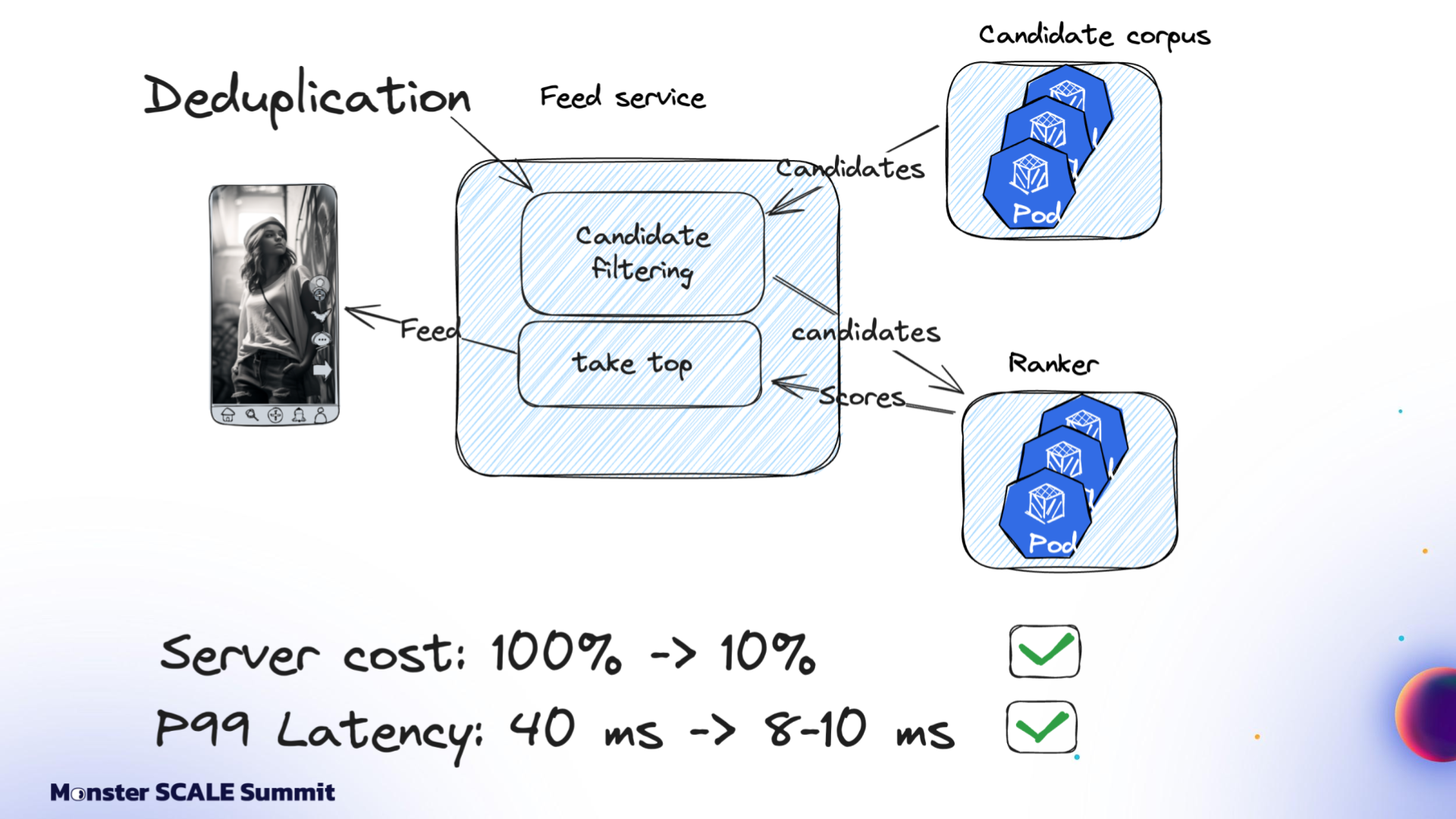
The deduplication service filters out content users have already seen before the ranking models ever score it. It’s a standard part of the feed pipeline: fetch candidates from vector databases, filter them, score and rank using ML models, then return the top results.
The system tracks two distinct concepts: Sent posts and Viewed posts. Sent posts are delivered to the user’s device. They may or may not have been seen. Viewed posts are items that the user has actually seen.
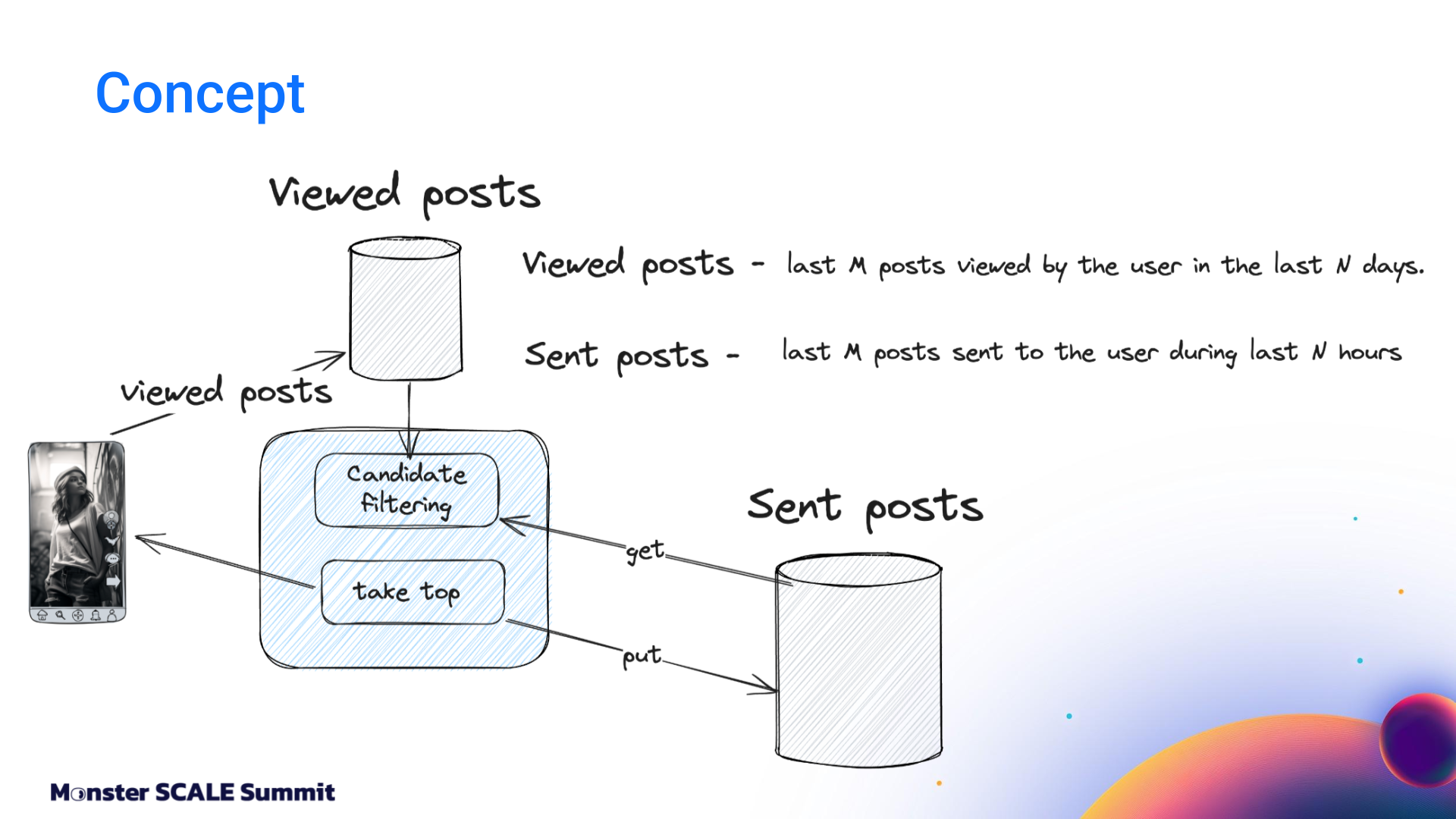
Why both? Viewed posts are tracked on user devices and sent to the backend periodically, passing through queues before being persisted in the database. This creates a delay between the time the event occurs and when it’s stored. That delay makes it possible to send duplicate posts in sequential feed requests.
Sent posts solve this by being stored immediately before the response goes to the client. That prevents duplicates from sneaking into subsequent feed refreshes. So why not just use Sent posts? That would create a different problem: “In a feed response, we send multiple posts at once, but there’s no guarantee that the user will actually see all of them,” Andrei explained. “If we rely only on Sent posts, we might deduplicate relevant content that the user never saw…and that can negatively affect feed quality.”
The Initial Architecture: Google Cloud, Bigtable, Dataflow, Pub/Sub + Redis
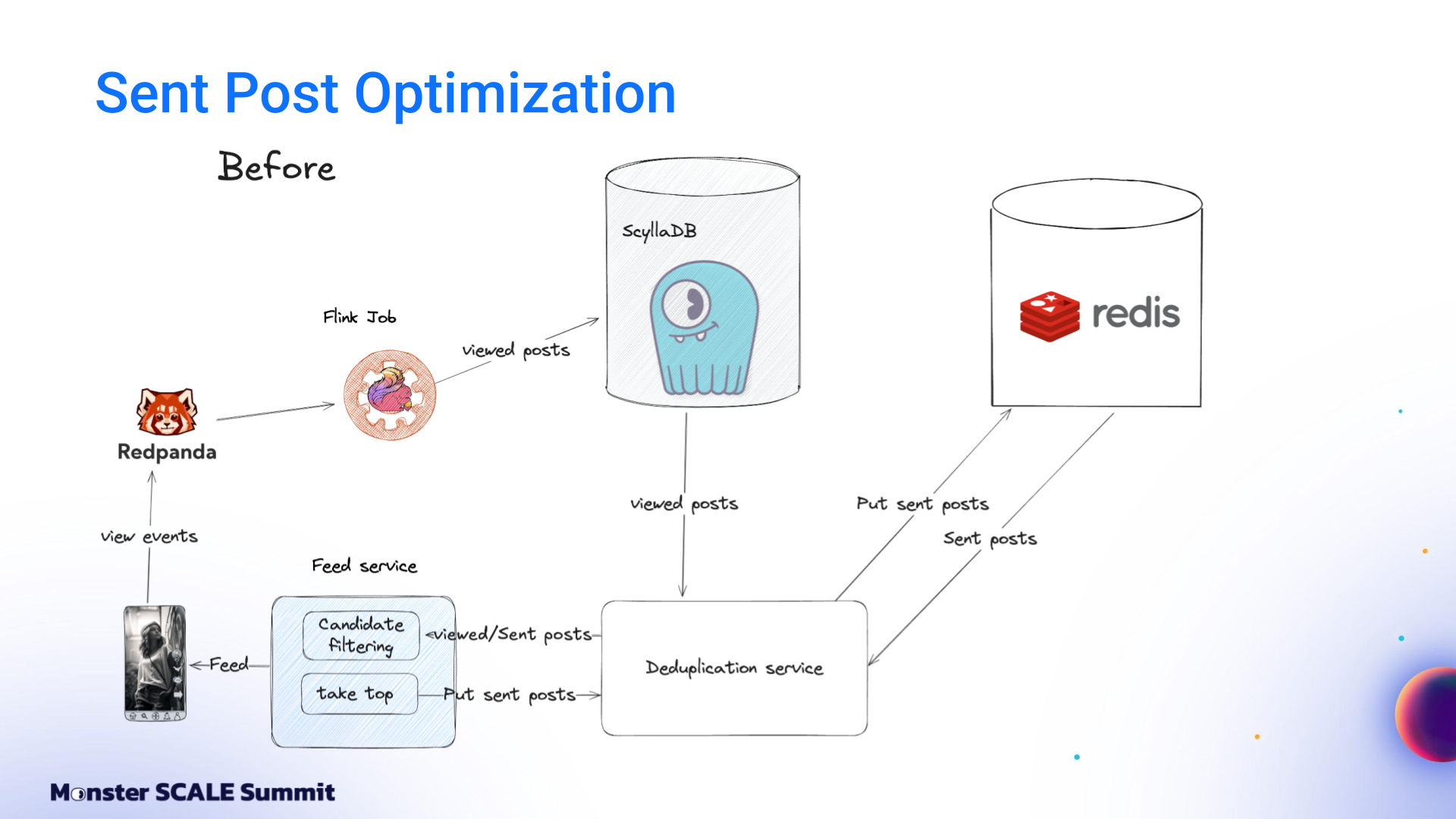
The initial architecture was built entirely on Google Cloud. View events flowed into Google Pub/Sub. A Dataflow job aggregated these events per user over time windows and wrote batches into Bigtable. Sent posts lived in Redis as linked-list queues. A deduplication service (written in Go and running on Kubernetes) combined both data sources with feed logic and returned results to the client.
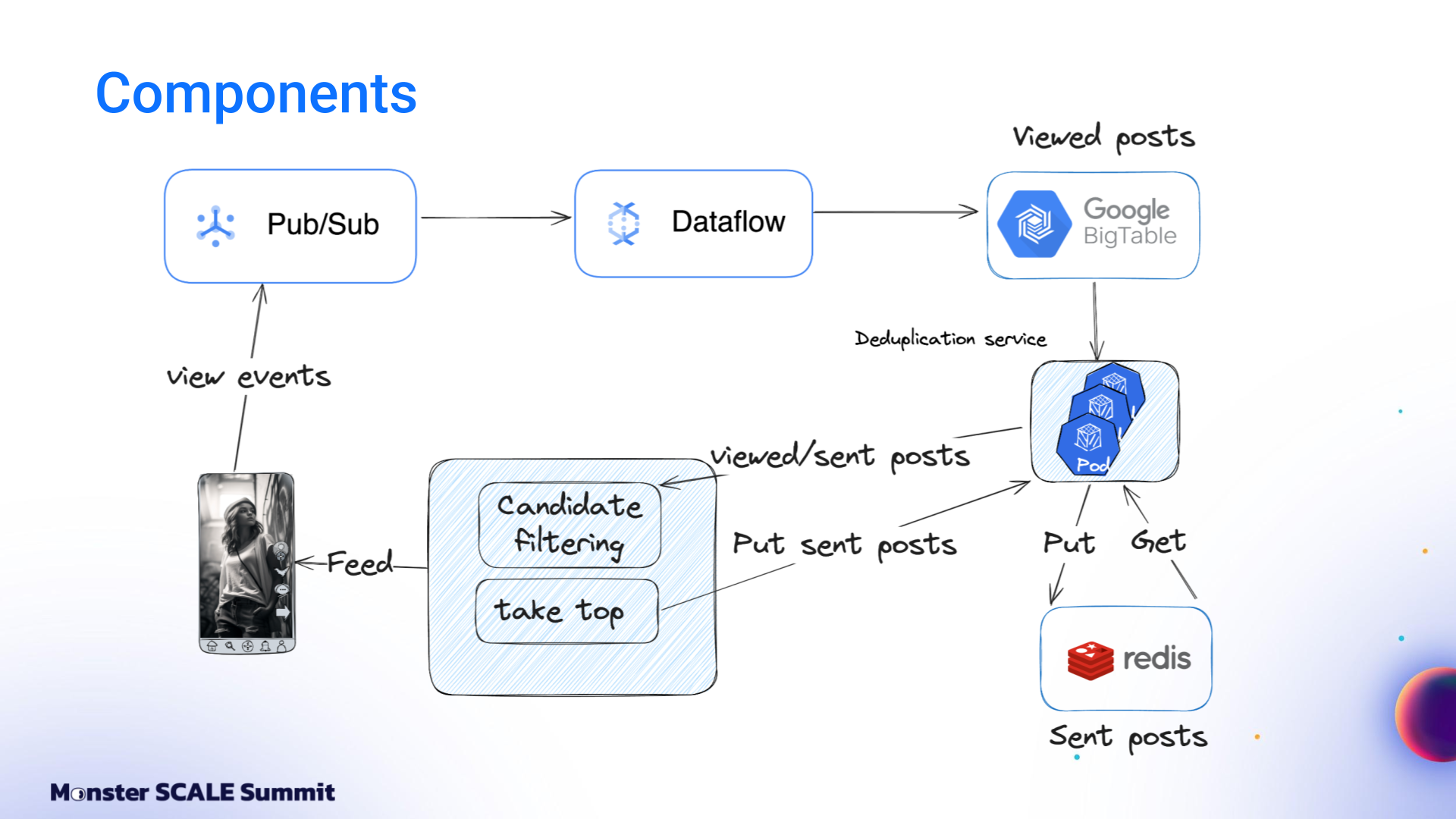
It worked. But it was expensive, and latency was a suboptimal 40 milliseconds.
Moving to Flink, ScyllaDB, and Redpanda
The first optimization step was replacing Google’s managed services with specialized, efficiency-oriented alternatives. Andrei shared, “We replaced Google Pub/Sub with Redpanda, which is Kafka-compatible and more efficient. We replaced Google Bigtable with ScyllaDB, and Google Dataflow with Apache Flink. These changes alone brought costs down to about 60% of the original level.”
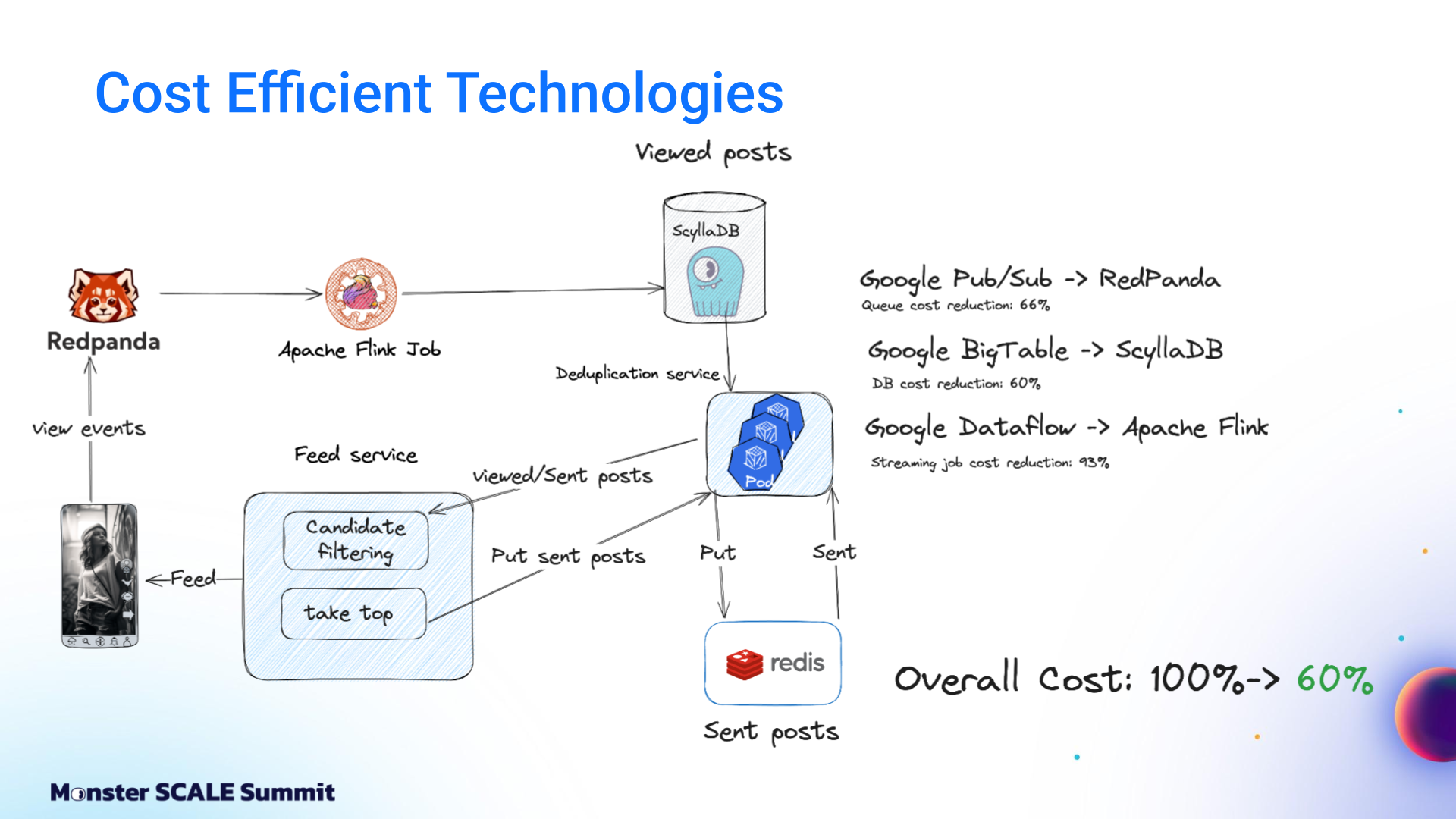
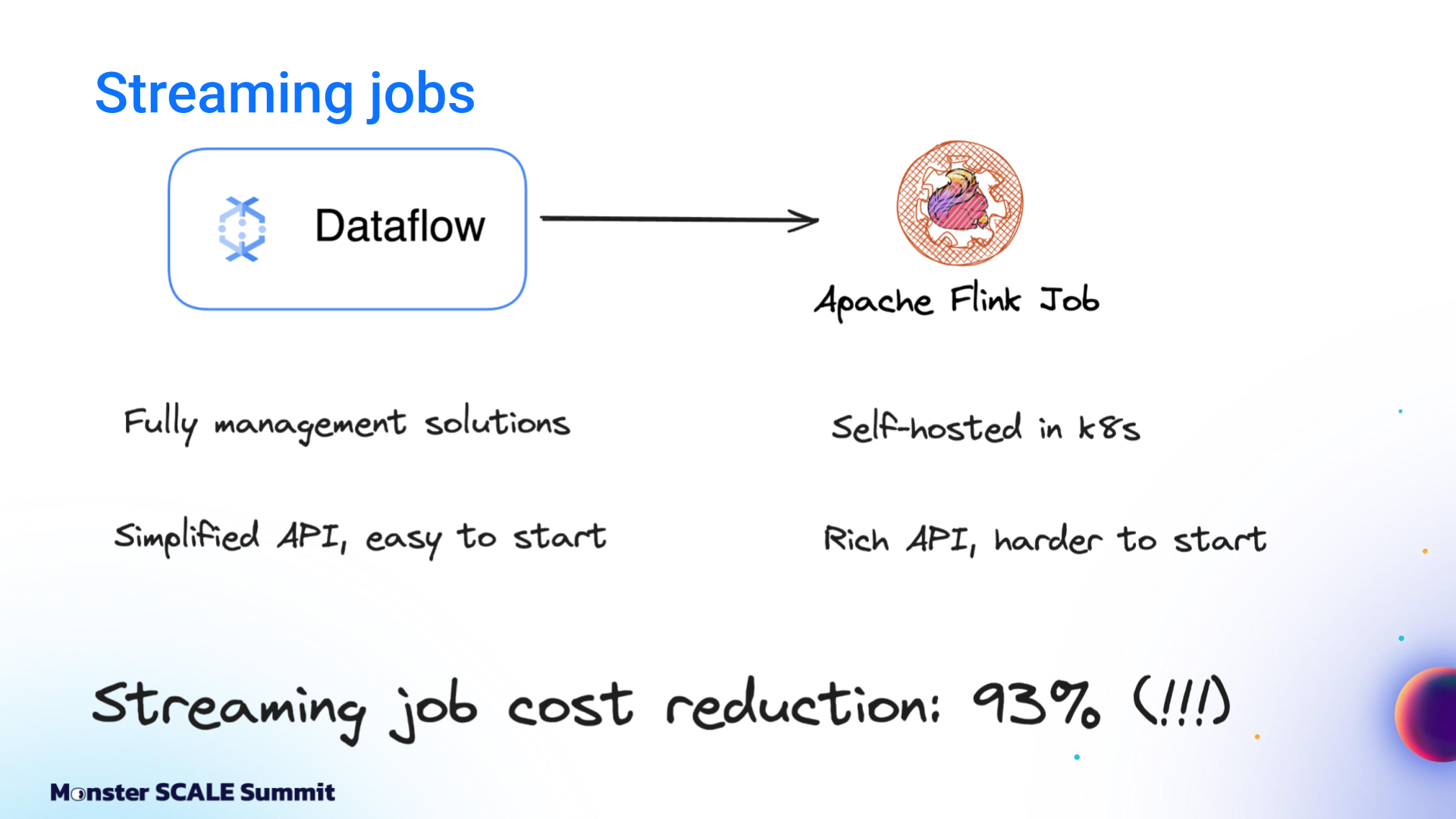
Dataflow to Flink
Dataflow was used for streaming jobs and aggregation events. The team enjoyed having a fully managed service with a simplified API that was nice for prototyping. But at scale, it grew costly. Moving to Apache Flink meant they had to run and maintain their own cluster. Still, it was worth it. They cut the cost of streaming jobs 93%.
Bigtable to ScyllaDB
On the database front, the team moved from Bigtable to ScyllaDB after comparing their tradeoffs, similarities, and differences. Andrei explained, “First of all, both databases are optimized for heavy write workload. Also, we are able to use a quite similar schema: partition by user ID, store all posts in a single column.”
But there were key differences. Bigtable’s autoscaling was valuable given ShareChat’s traffic variability (nighttime traffic drops to less than 10% of peak). At that time, ScyllaDB did not support autoscaling, so ShareChat had to provision clusters for peak load and keep additional buffers for spikes. Bigtable also has advanced garbage collection rules that allow limits on rows per partition and TTL definitions. ScyllaDB supports this via TTL, and it’s possible to encounter large partitions if a single user generates many events.
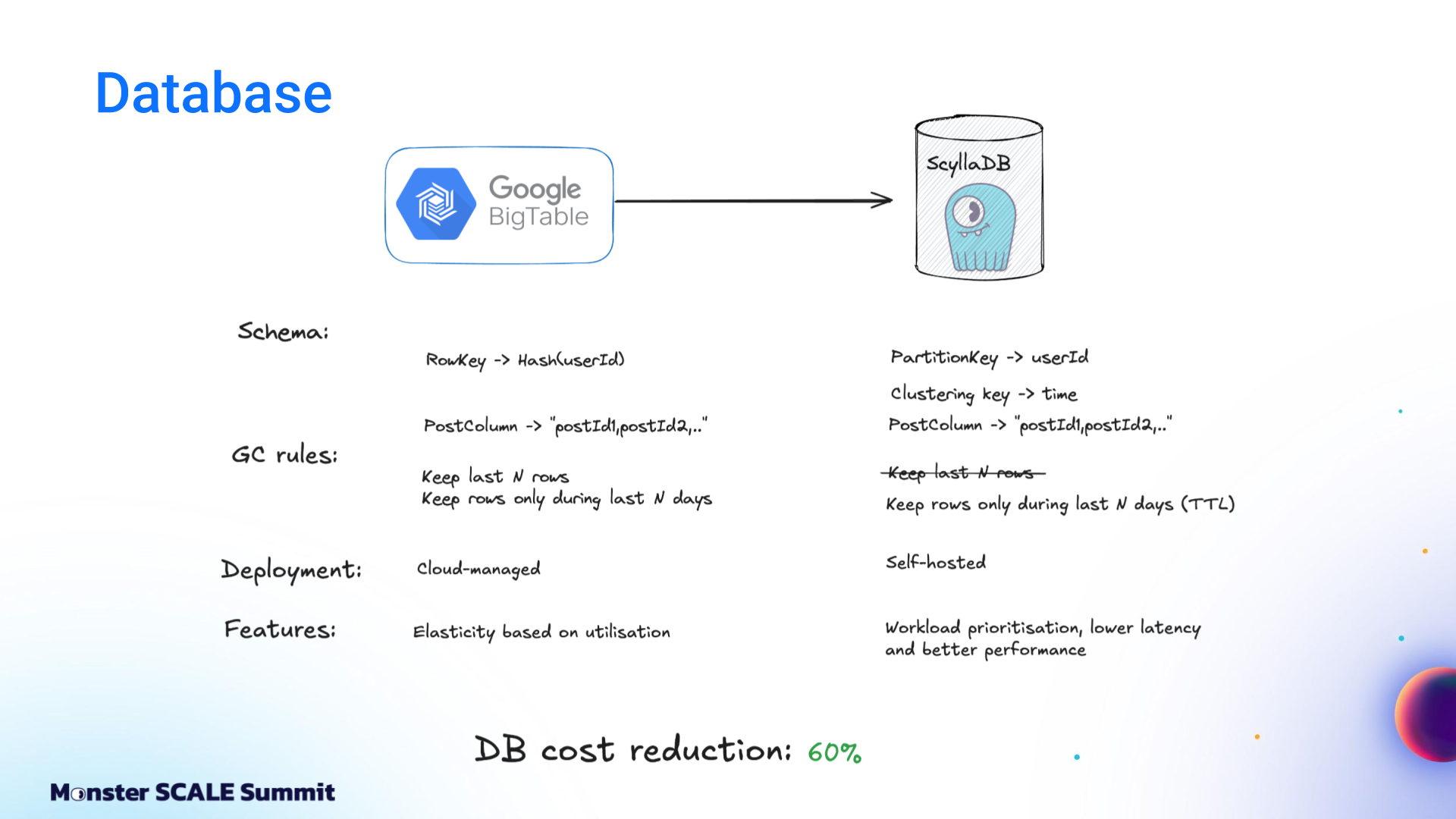
For ShareChat’s needs, ScyllaDB was ultimately the best fit. Andrei explained, “ScyllaDB uses a shard-per-core architecture and is highly optimized. It delivers better performance and lower latency than Bigtable. Even a fully provisioned ScyllaDB cluster is significantly cheaper than Bigtable with autoscaling.”
One feature proved particularly valuable: workload prioritization. Per Andrei, “ScyllaDB also supports workload prioritization, which is unique to ScyllaDB. It allows resource-based isolation between different workloads. That’s quite critical in our case. The read path directly affects user experience, so we can’t allow any latency spikes there.” If there’s ever any resource contention, workload prioritization can prioritize their reads over writes.
PubSub to Redpanda
For the event queue, the team also moved from PubSub to Redpanda, which they found to be reliable as well as cost-efficient. It’s a fully Kafka-compatible product, so it was easy to integrate. Like ScyllaDB, it’s written in C++ with a thread-per-core architecture (both are built on Seastar), Redpanda is highly efficient. In ShareChat’s use case, queue costs were reduced by ~66%.
Resource Allocation and Database Efficiency
With the new foundational infrastructure in place, the team turned to resource optimization.
First came Kubernetes resource tuning. Andrei detailed, “We focused on three areas, starting with Kubernetes resources. We adjusted HPA settings and increased target CPU utilization, which resulted in higher CPU usage per pod.” That change had a useful side effect: it exposed inefficiencies that had been lurking at lower utilization levels, including garbage collection pressure and mutex contention. The team fixed those issues before moving on.
Apache Flink required its own autoscaling adjustments. A Flink job consists of tasks in an execution pipeline, and the autoscaler monitors task busy time and adjusts parallelism accordingly. But scaling events recreate the job and temporarily halt processing. “With large pipelines, this can lead to instability,” Andrei shared. “For some systems, we had to fork the autoscaler, but for this application, it worked smoothly.”
They also discovered they could squeeze even more from their ScyllaDB cluster, so they rightsized it: “We provisioned ScyllaDB clusters targeting around 60% CPU utilization for ScyllaDB. But after learning more, we realized that ScyllaDB is built to utilize all available resources and prioritizes critical tasks over non-critical ones. That means it’s easy to reach 100% CPU without any system degradation by allocating the remaining CPU resources to maintenance tasks. We started targeting 60% CPU utilization only for critical tasks and we could reduce the cluster size even more without any latency degradations.” The details on how they managed this are explained in Andrei’s blog post, ScyllaDB: How To Analyse Cluster Capacity.
The combination of those steps brought them down to 45% of the initial cost.
Questioning Assumptions: Retention Windows Example
Next up: domain-specific engineering improvements. “In theory, every system should have a clear problem statement, defined metrics, and well-understood use cases,” Andrei said. “In reality, systems often contain unclear logic, unexplained parameters, and legacy decisions. We decided to question these assumptions.”
One example that’s easy to explain without too much context is how they chose the right window size parameters for their sliding window queries
The team focused on the retention window parameters (M and N) that defined how much history to keep per user. Their posts are partitioned by user ID and ordered by time. That creates a sliding window. Andrei explained, “The question is how to choose the right values. The answer is A/B testing.”
So, they split users into groups with different parameter configurations and measured the impact.
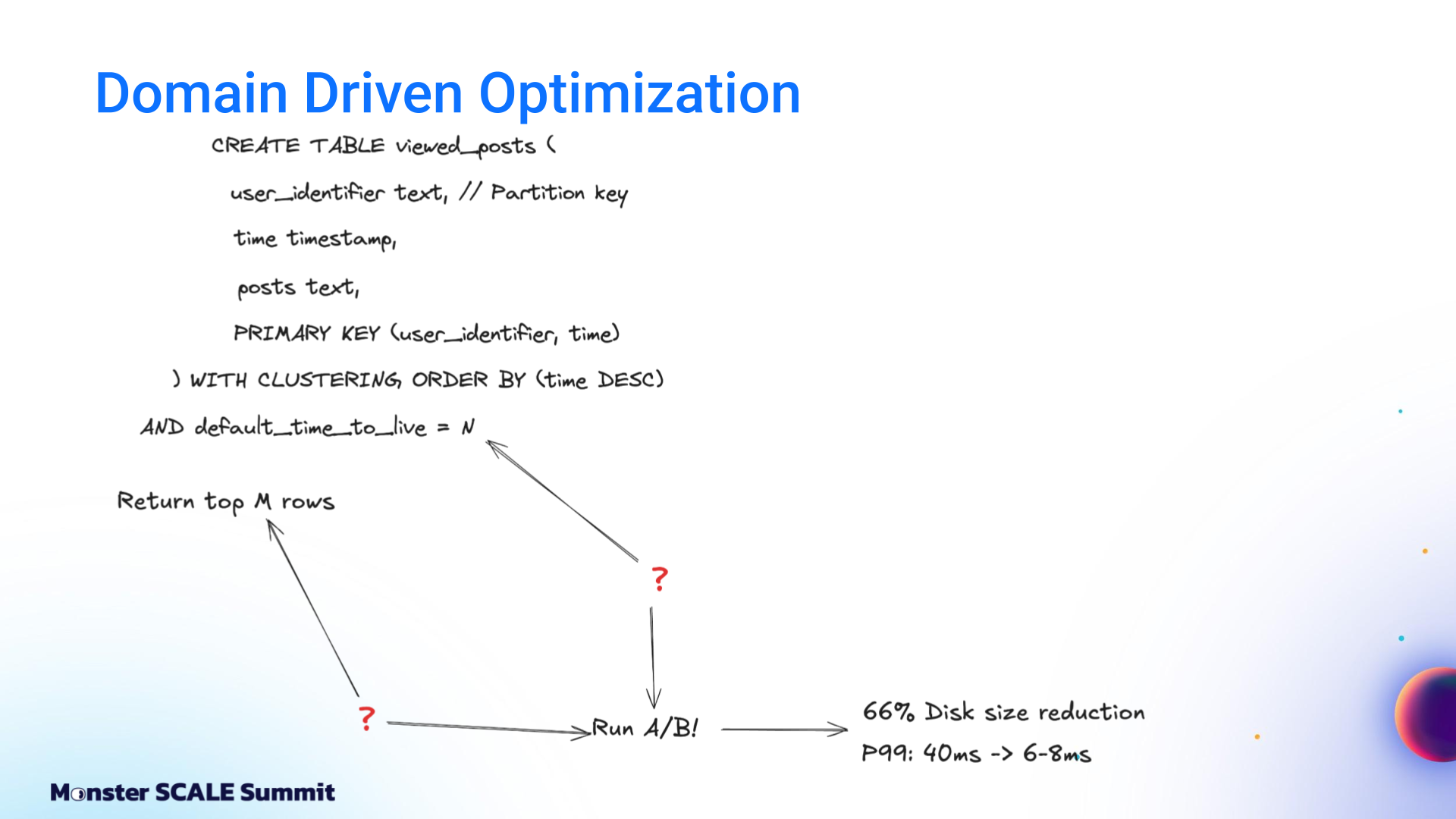
It turned out that their previous windows were too large, so they tightened them. The results per Andrei: “After running more than 10 A/B tests, we reduced latency from 40 milliseconds to 8 milliseconds, were able to reduce the database size, and reduced costs to 30% of the initial level.”

Storage Size Optimization through Delta Based Compression
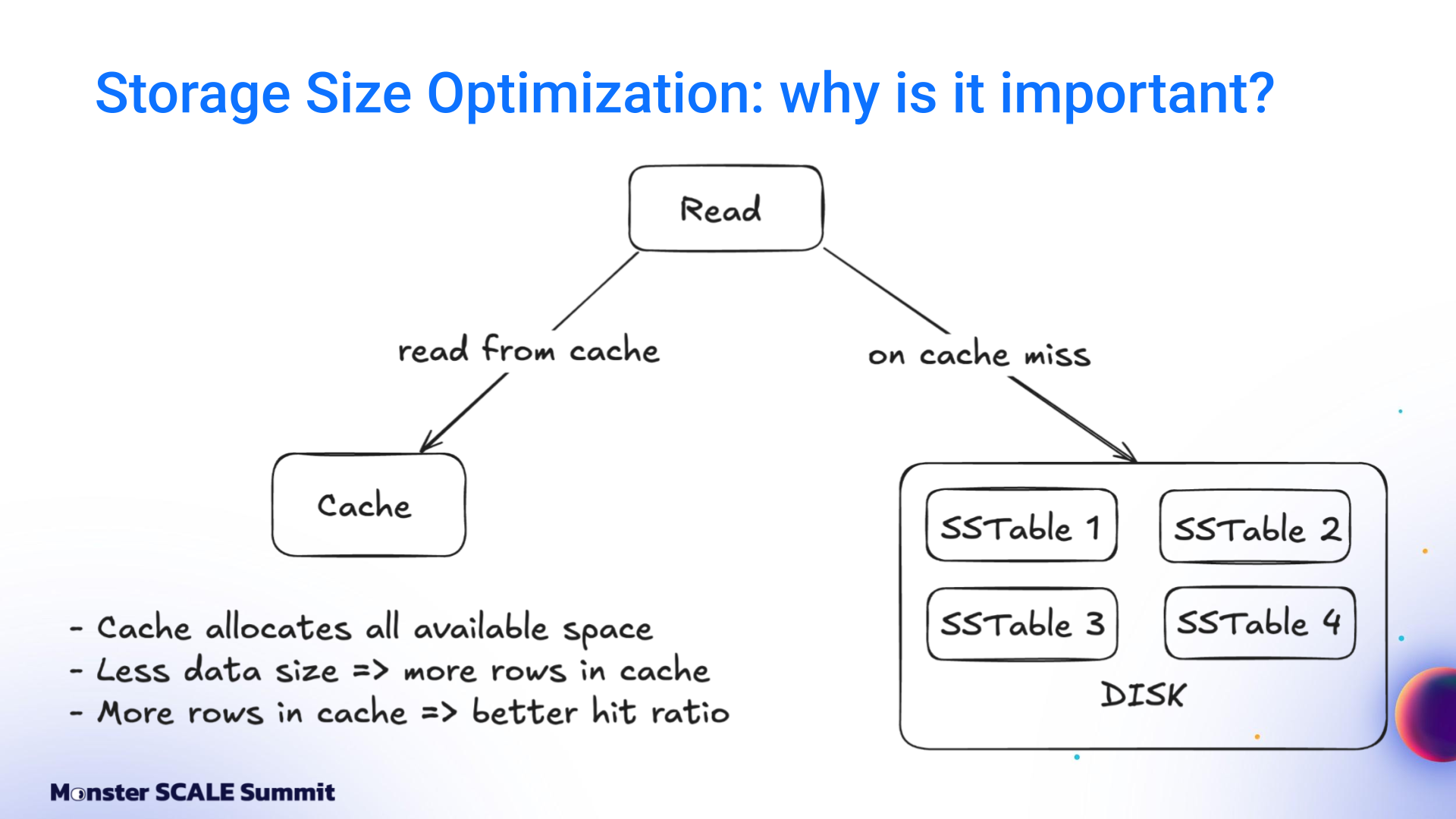
The next optimization targeted storage size directly. ScyllaDB read performance depends heavily on cache behavior. Smaller data size means more rows fit into cache, leading to higher cache hit rates, fewer disk reads, and lower CPU usage.
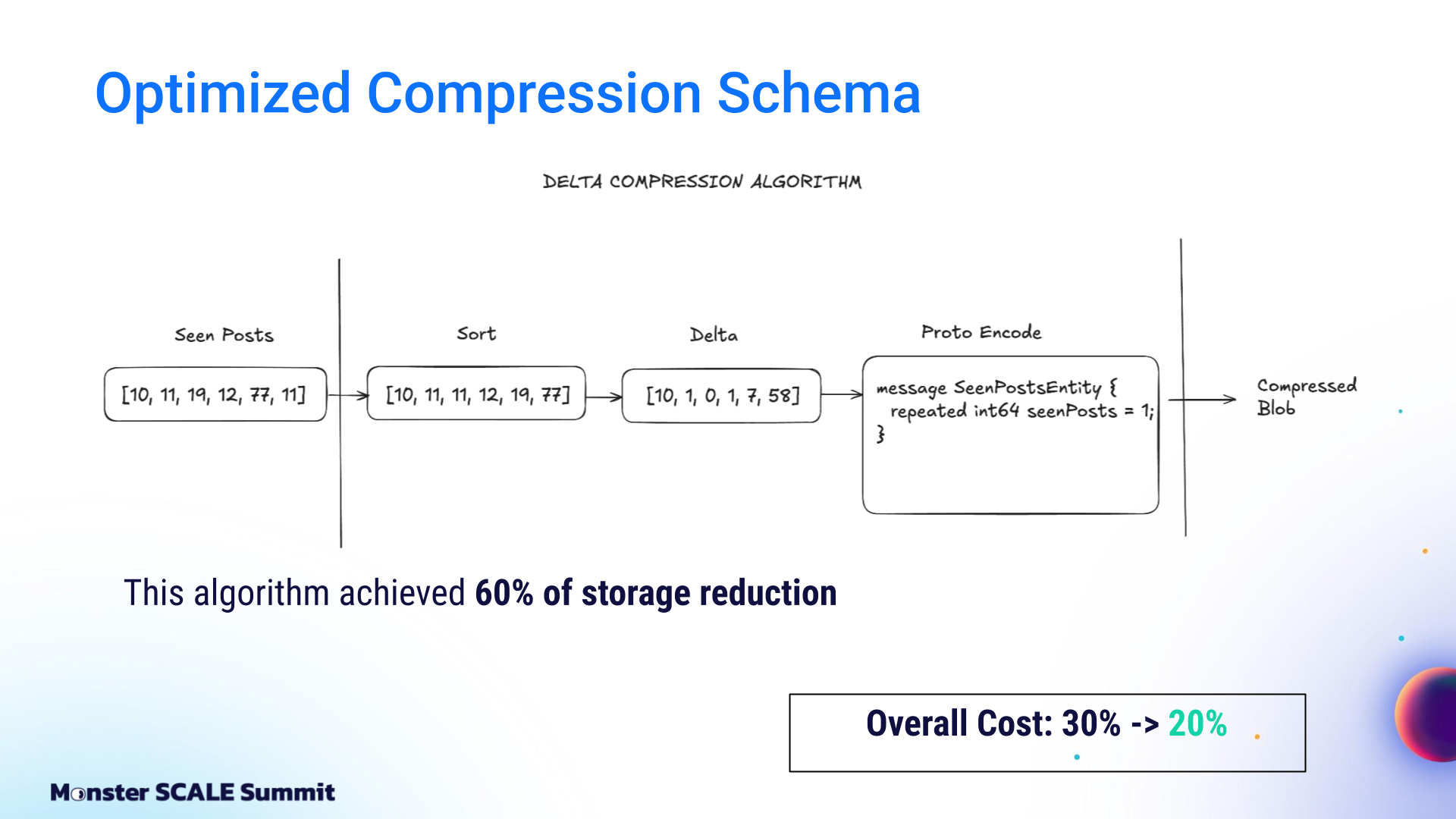
The team stores post IDs as integers and evaluated several compression approaches: Bloom filters, Roaring Bitmaps, and delta-based compression. Andrei’s rundown: “Bloom filters are probabilistic and can produce false positives, which would cause duplicates in the feed. Roaring Bitmaps performed poorly for our data distribution. We chose delta-based compression.”

With that approach, they sort post IDs, compute deltas between adjacent values, and encode them using Protocol Buffers, which store only meaningful bits for integers. As a result, they reduced storage by 60%, CPU usage by 25%, and overall cost to 20% of the original.
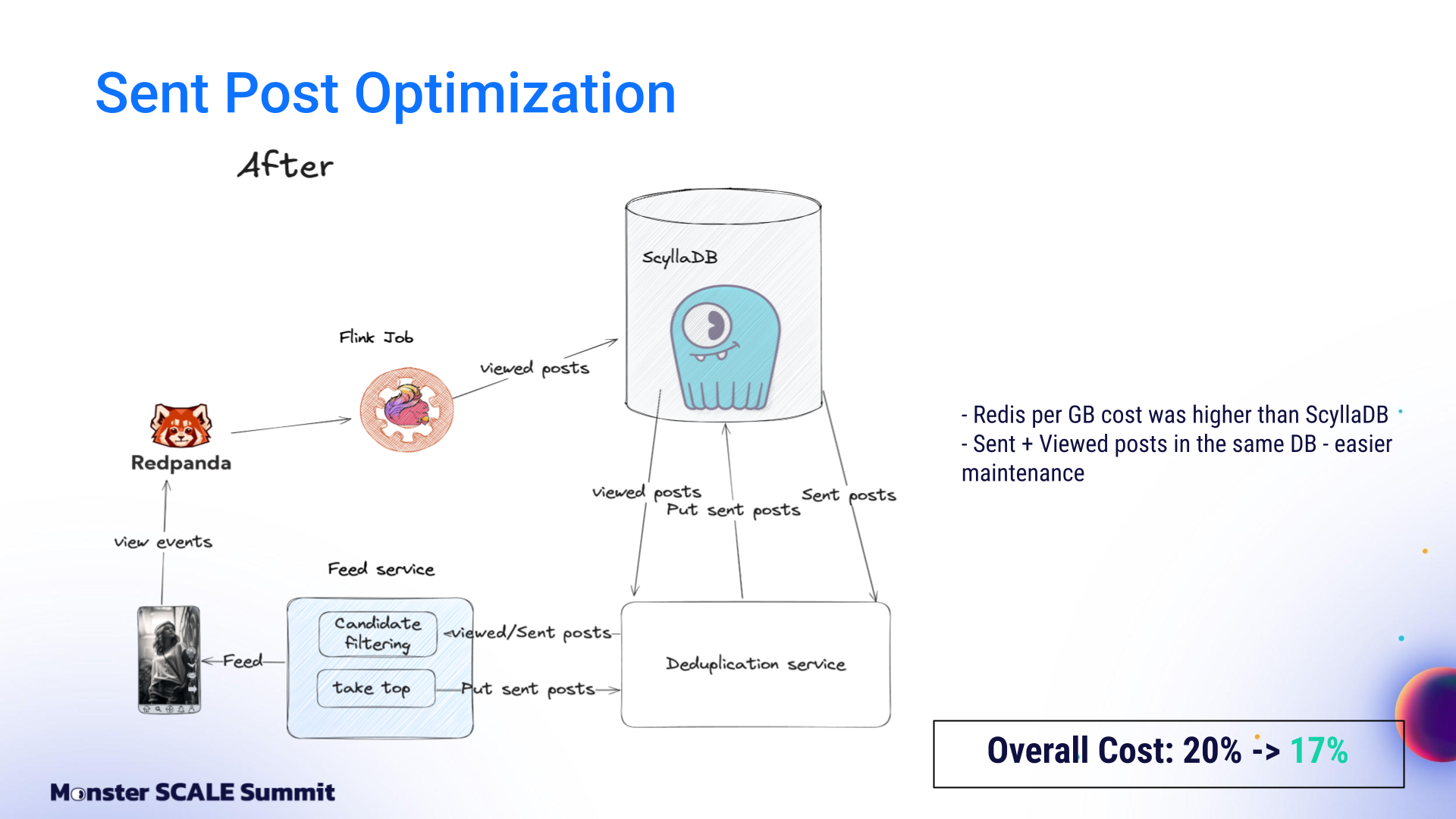
Sent Post Optimization: Replacing Redis with ScyllaDB
The next optimization involved Sent posts. Previously, Viewed posts were stored in ScyllaDB, while Sent posts were stored in Redis. But then another a-ha moment. Andrei shared, “After compression and cluster resizing, we realized that ScyllaDB was cheaper per gigabyte than Redis. Since Viewed posts and Sent posts are conceptually similar and differ mainly in retention limits, we moved Sent posts to ScyllaDB. This reduced costs to 17% and also improved system maintainability by eliminating one database.”
Cloud-Specific Cost Optimizations
The final phase focused on cloud provider-specific optimizations – more specifically, systematically eliminating waste in resource allocation and network traffic.
The first target was compute provisioning. Every cloud provider has different provision models for virtual machines. Spot instances can be evicted at any time, but they are ideal for stateless workloads. ShareChat used spot instances with on-demand nodes as backup. Tools like Cast AI helped them manage this setup and significantly reduced costs across the organization.
Next was inter-zone traffic. Zones are separate data centers within a region, and traffic between them is usually charged. The team cut cross-zone traffic for microservices using follower fetching for Kafka, token-aware and rack-aware routing for ScyllaDB, and topology-aware routing in Kubernetes:
- For Kafka consumers, enabling the follower fetching feature ensures the consumer connects to a broker in the same zone. That eliminates inter-zone traffic between the consumer and the queue.
- For ScyllaDB, combining token-aware and rack-aware policies in the driver ensures the application connects to a coordinator in the same zone. Since the coordinator will actually have the data, there is less traffic inside the cluster.
- For Kubernetes, topology-aware routing uses a best-effort approach, so approximately 5–15% of inter-zone traffic remains. The team built their own service mesh on Envoy proxy to eliminate that remaining traffic entirely.

The path to 90% cost savings
Over the course of a year, ShareChat’s team reduced infrastructure costs to 10% of the original level while cutting latency from 40 milliseconds to 8 milliseconds. To recap how they got here:
| Phase | Action taken | Remaining cost |
|---|---|---|
| Optimize stack | Migrated from GCP managed services to ScyllaDB, Flink & Redpanda | 60% |
| Resource tuning | Tuned Kubernetes HPA, optimized Flink’s native autoscaling, and rightsized the ScyllaDB cluster | 45% |
| Domain Logic | A/B testing (e.g., tightening retention sliding windows) | 30% |
| Data Efficiency | Implemented delta-based compression for Post IDs | 20% |
| Database consolidation | Migrated Sent posts from Redis to ScyllaDB | 17% |
| Cloud Ops | Leveraged Spot instances and eliminated inter-zone traffic | 10% |
What’s next on the ShareChat optimization agenda? Stop by Monster Scale Summit 2026 (free + virtual) to hear directly from Andrei.