The Taming of Collection Scans
Explore several collection layouts for efficient scanning, including a split-list structure that avoids extra memory
Here’s a puzzle that I came across when trying to make tasks wake up in Seastar be a no-exception-throwing operation (related issue): come up with a collection of objects optimized for “scanning” usage. That is, when iterating over all elements of the collection, maximize the hardware utilization to process a single element as fast as possible. And, as always, we’re expected to minimize the amount of memory needed to maintain it. This seemingly simple puzzle will demonstrate some hidden effects of a CPU’s data processing.
Looking ahead, such a collection can be used, for example, as a queue of running tasks. New tasks are added at the back of the queue; when processed, the queue is scanned in front-to-back order, and all tasks are usually processed. Throughout this article, we’ll refer to this use case of a collection being the queue of tasks to execute. There will be occasional side notes using this scenario to demonstrate various concerns.
We will explore different ways to solve this puzzle of organizing collections for efficient scanning. First, we compare three collections: array, intrusive list, and array of pointers. You will see that the scanning performance of those collections differs greatly, and heavily depends on the way adjacent elements are referenced by the collection. After analyzing the way the processor executes the scanning code instructions, we suggest a new collection called a “split list.” Although this new collection seems awkward and bulky, it ultimately provides excellent scanning performance and memory efficiency.
Classical solutions
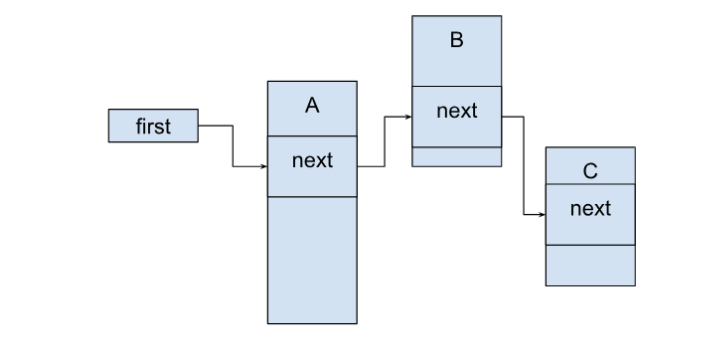
First consider two collections that usually come to mind: a plain sequential array of elements and a linked list of elements. The latter collection is sometimes unavoidable, particularly when the elements need to be created and destroyed independently and cannot be freely moved across memory.
As a test, we’ll use elements that contain random, pre-populated integers and a loop that walks all elements in the collection and calculates the sum of those integers.
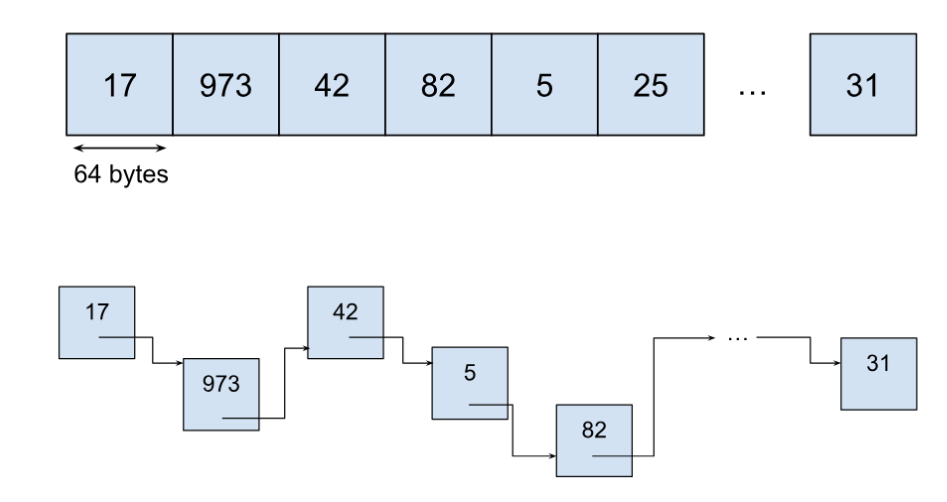
Every programmer knows that in this case, an array of integers will win because of cache efficiency. To exclude the obvious advantage of one collection over another, we’ll penalize the array and prioritize the list. First, each element will occupy a 64-byte slot even when placed in an array, so walking a plain array doesn’t benefit from caching several adjacent elements. Second, we will use an intrusive list, which means that the “next” pointer will be stored next to the element value itself. The processor can then read both the pointer and the value with a single fetch from memory to cache.
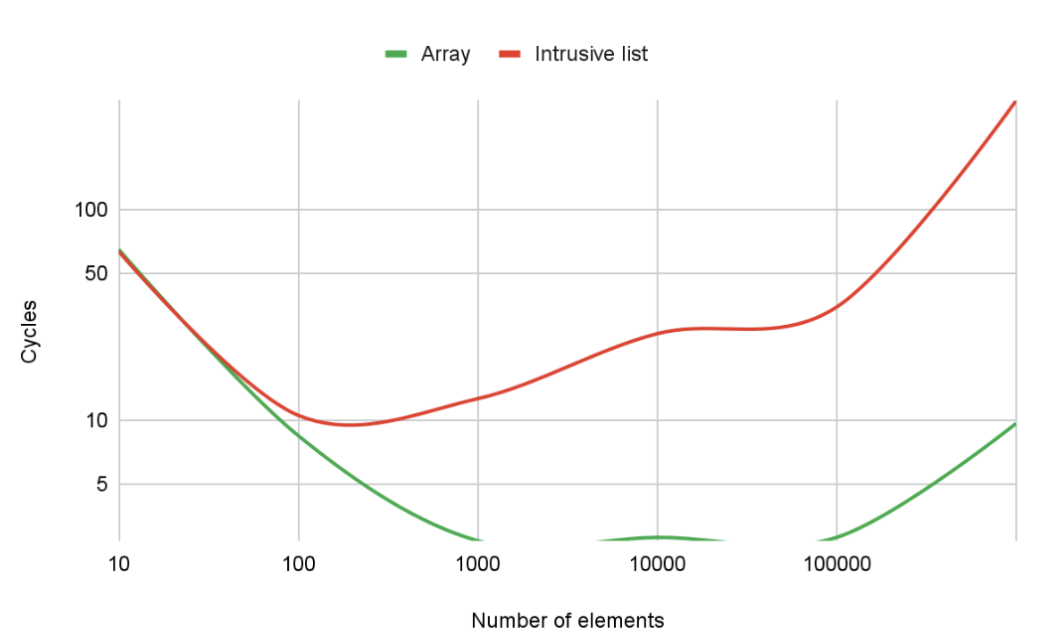
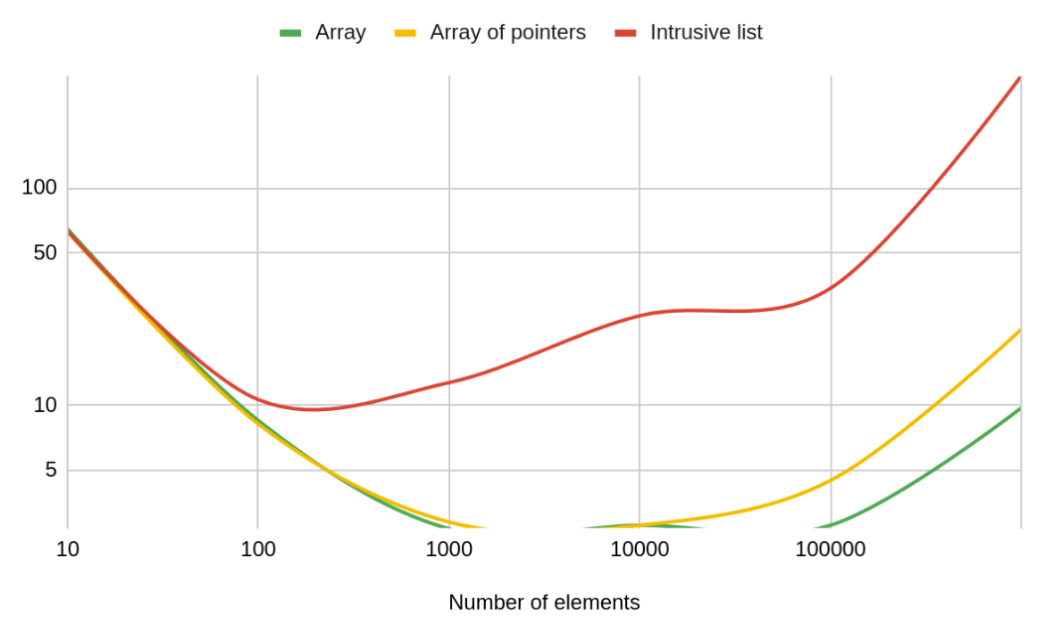
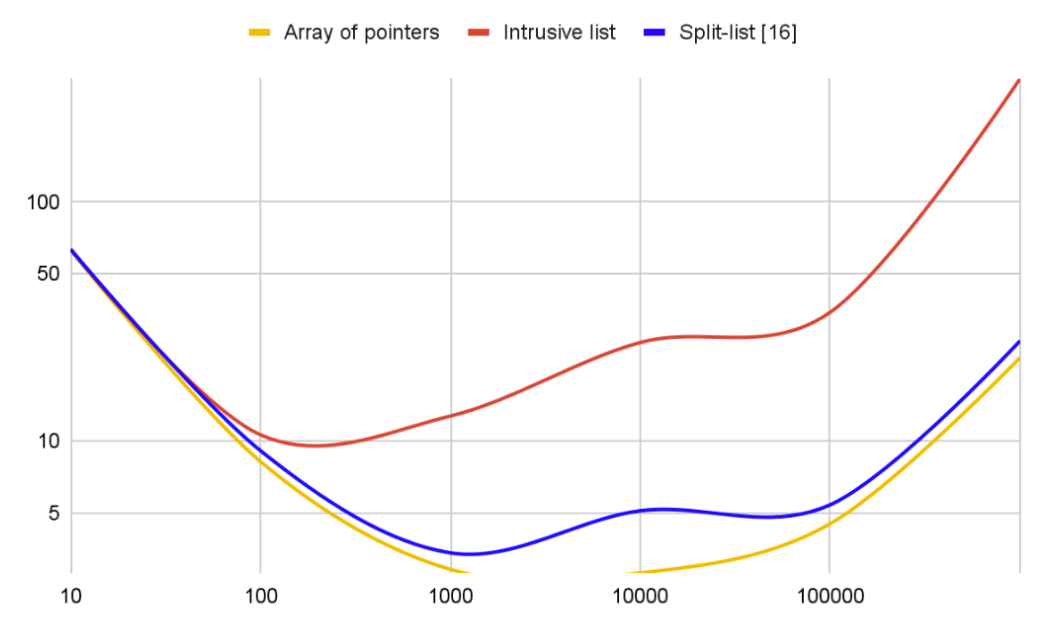
The expectation here is that both collections will behave the same. However, a scanning test shows that’s not true, especially on a large scale.
The plot above shows the time to process a single entry (vertical axis) versus the number of elements in the list (horizontal axis). Both axes use a logarithmic scale because the collection size was increased ten times at each new test step. Plus, the vertical axis just looks better this way.
So now we have two collections – an array and a list – and the list’s performance is worse than the array’s. However, as mentioned above, the list has an undeniable advantage: elements in the list are independent of each other (in the sense that they can be allocated and destroyed independently). A less obvious advantage is that the data type stored in a list collection can be an abstract class, while the actual elements stored in the list can be specific classes that inherit from that base class.
The ability to collect objects of different types can be crucial in the task processing scenario described above, where a task is described as an abstract base class and specific task implementations inherit from it and implement their own execution methods.
Is it possible to build a collection that can maintain its elements independently, as a list of elements does, yet still provide scanning performance that’s the same (or close to) that of the array?
Not so classical solution
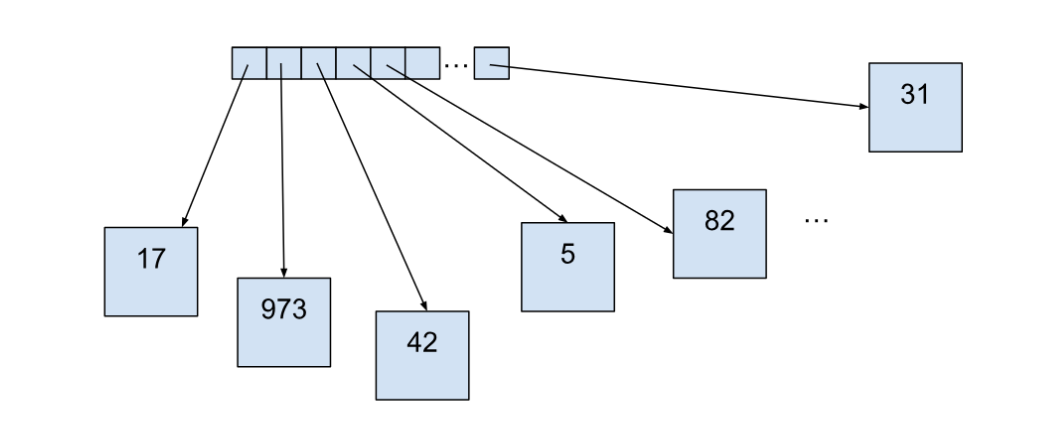
Let’s make an array of elements be “dispersed,” like a list, in a straightforward manner by turning each array element into a pointer to that element, and allocating the element itself elsewhere, as if it were prepared to be inserted into a list.
In this array, pointers will no longer be aligned to a cache-line, thus letting the processor benefit from reading several pointers from memory at once. Elements are still 64-bytes in size, to be consistent with previous tests.
The memory for pointers is allocated contiguously, with a single large allocation. This is not ideal for dynamic collection, where the number of elements is not known beforehand: the larger the collection grows, the more re-allocations are needed. It’s possible to overcome this by maintaining a list of sub-arrays. Looking ahead, just note that this chunked array of pointers will indeed behave slightly worse than a contiguous one. All further measurements and analysis refer to the contiguous collection.
This approach actually looks worse than the linked list because it occupies more memory than the list. Also, when walking the list, the code touches one cache line per element – but when walking this collection, it additionally populates the cache with the contents of that array of pointers.
Running the same scanning test shows that this cost is imaginary and the collection beats the list several times, approaching the plain array in its per-element efficiency.
The processor’s inner parallelism
To get an idea of why an array of pointers works better than the intrusive list, let’s drill down to the assembly level and analyze how the instructions are executed by the processor.
Here’s what the array scanning main loop looks like in assembly:
x: mov (%rdi,%rax,8),%rax
mov 0x10(%rax),%eax
add %rax,%rcx
lea 0x1(%rdx),%eax
mov %rax,%rdx
cmp %rsi,%rax
jb x
We can see two memory accesses – the first moves the pointer to the array element to the ‘rax’ register, and the second fetches the value from the element into its ‘eax’ 32-bit sub-part. Then there comes in-register math and conditional jumping back to the start of the loop to process the next element.
The main loop of the list scanning code looks much shorter:
x: mov 0x10(%rdi),%edx
mov (%rdi),%rdi
add %rdx,%rax
test %rdi,%rdi
jne x
Again, there are two memory accesses – the first fetches the value pointer into the ‘edx’ register and the next one fetches the pointer to the next element to the ‘rdi’ register.
Instructions that involve fetching data from memory can be split into four stages:
i-fetch – The processor fetches the instruction itself from memory. In our case, the instruction is likely in the instruction cache, so the fetch goes very fast.
decode – The processor decides what the instruction should do and what operands are needed for this.
m-fetch – The processor reads the data it needs from memory. In our case, elements are always read from memory because they are “large enough” not to be fetched into cache with anything else, while array pointers are likely to sit in cache.
exec – The processor executes the instruction.
Let’s illustrate this sequence with a color bar:
Also, we know that modern processors can run multiple instructions in parallel, by executing parts of different instructions at the same time in different parts of the conveyor, as well as running instructions fully in parallel.
One example of this parallel execution can be seen in the array-scanning example above, namely the
add %rax,%rcx
lea 0x1(%rdx),%eax
part. Here, the second instruction is the increment of the index that’s used to scan through the array of pointers. The compiler rendered this as lea instruction instead of the inc (or add) one because inc and lea are executed in different parts of the pipeline. When placed back-to-back, they will truly run in parallel. If the inc was used, the second instruction would have to spend some time in the same pipeline stage as the add.
Here’s what executing the above array scan can look like:
Here, fetching the element pointer from the array is short because it likely happens from cache. Fetching the element’s value is long (and painted darker) because the element is most certainly not in cache (and thus requires a memory read). Also, fetching the value from the element happens after the element pointer is fetched into the register. Similarly, the instruction that adds value to the result cannot execute before the value itself is fetched from memory, so it waits after being decoded.
And here’s what scanning the list can look like:
At first glance, almost nothing changed. The difference is that the next pointer is fetched from memory and takes a long time, but the value is fetched from cache (and is faster). Also, fetching the value can start before the next pointer is saved into the register. Considering that during an array scan, the “read element pointer from array” is long at times (e.g., when it needs to read the next cache line from memory), it’s still not clear why list scanning doesn’t win at all.
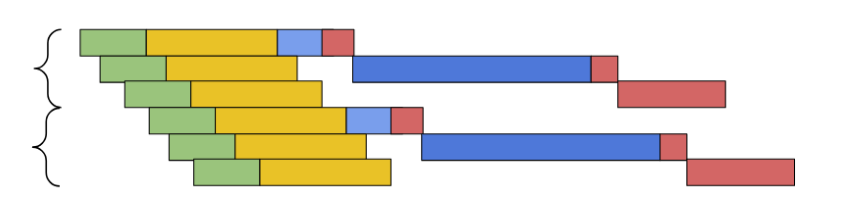
In order to see why the array of pointers wins, we need to combine two consecutive loop iterations. First comes the array scan:
It’s not obvious, but two loop iterations can run like that. Fetching the pointer for the next element is pretty much independent from fetching the pointer of the previous element; it’s just the next element of an array that’s already in the cache. Just like predicting the next branches, processors can “predict” that the next memory fetch will come from the pointer sitting next to the one being processed and start loading it ahead of time.
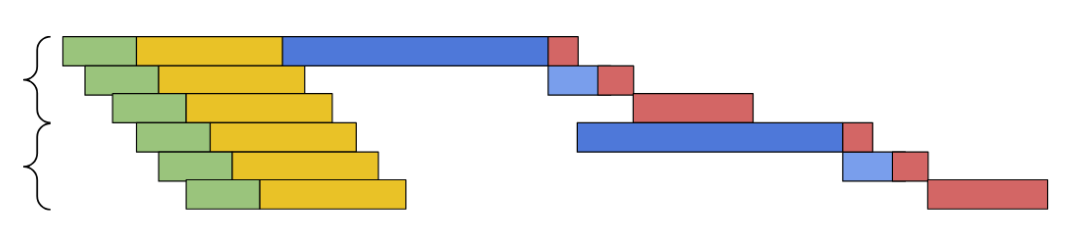
List scanning cannot afford that parallelism even if the processor “foresees” that the fetched pointer will be dereferenced. As a consequence, its two loop iterations end up being serialized:
Note that the processor can only start fetching the next element after it finishes fetching the next pointer itself, so the parallelism of accessing elements is greatly penalized here. Also note that despite how it seems in the above images, scanning the list can be many times slower than scanning the array, because blue bars (memory fetches) are in reality many times longer than the others (e.g., those fetching the instruction, decoding it, and storing the result in the register).
A compromise solution
The array of pointers turned out to be a much better solution than the list of elements, but it still has an inefficiency: extra memory that can grow large. Here we can say that this algorithm has O(N) memory complexity, meaning that it requires extra memory that’s proportional to the number of elements in the collection. Allocating it can be troublesome for many reasons – for example, because of memory fragmentation and because, at large scale, growing the array would require copying all the pointers from one place to another. There are ways to mitigate the problem of maintaining this extra memory, but is it possible to eliminate it completely? Or at least make it “constant complexity” (i.e., independent from the number of elements in it)?
The requirement to not allocate extra memory can be crucial in task processing scenarios. In it, the auxiliary memory is allocated when an element is appended to the existing collection. And a new task is appended to the run-queue when it’s being woken up. If the allocation fails, the appending also fails as well as the wake-up call. And having non-failing wake-ups can be critical.
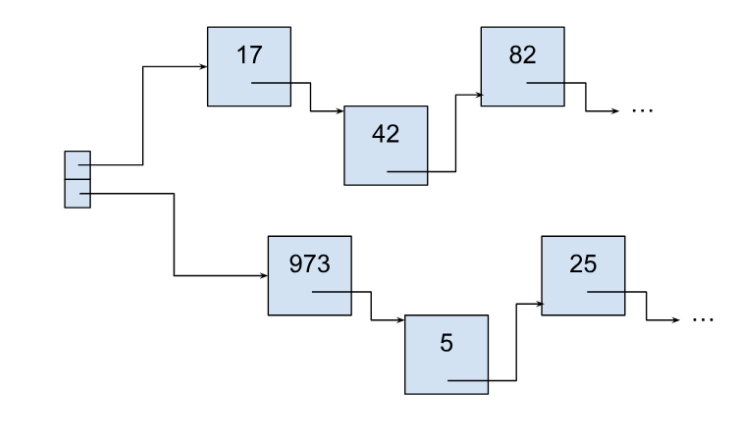
It looks like letting the processor fetch independent data in different consecutive loop iterations is beneficial. With a list, it would be good if adjacent elements were accessed independently. That can be achieved by splitting the list into several sub-lists, and – when iterating the whole collection – processing it in a round-robin manner. Specifically, take an element from the first list, then from the second, … then from the Nth, then advancing on the first, then advancing on the second, and so on.
The scanning code is made with the assumption that the collection only grows by appending elements to one of its ends – the front or the back end. This perfectly suits the task-processing usage scenario and allows making the scanning code break condition to be very simple: once a null element is met in either of the lists, all lists after it are empty as well, so scanning can stop. Below is the simplistic implementation of the scanning loop. A full implementation that handles appends is a bit more hairy and is based on the C++ “iterator” concept. But overall, it has the same efficiency and resulting assembly code.
First, checking this list with N=2
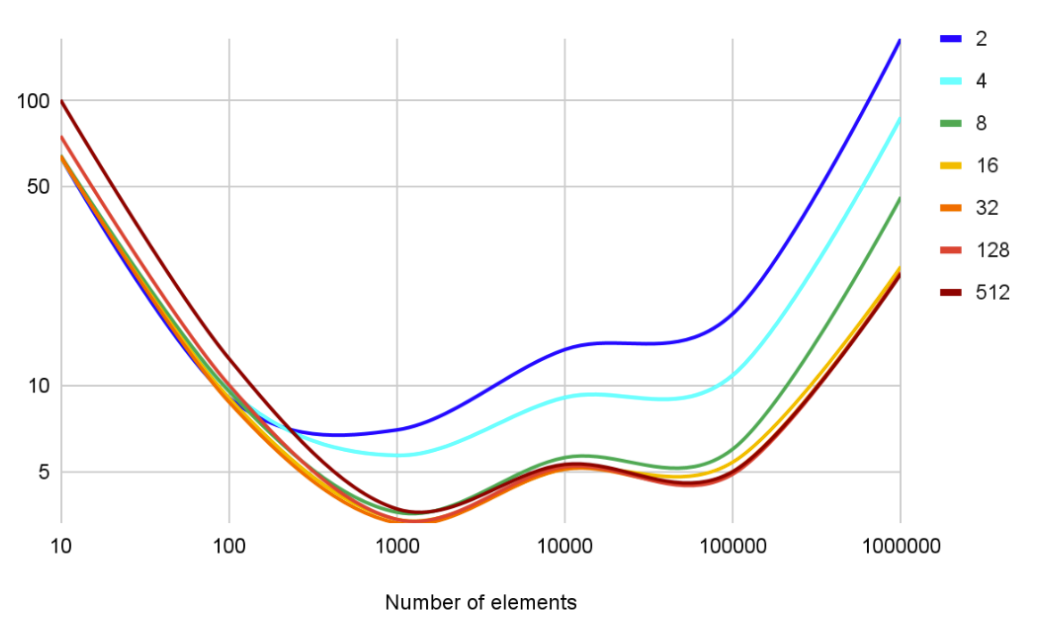
OK, scanning two lists “in parallel” definitely helps. Since the number of splits is compile-time constant, we now need to run several tests to see which value is the most efficient one.
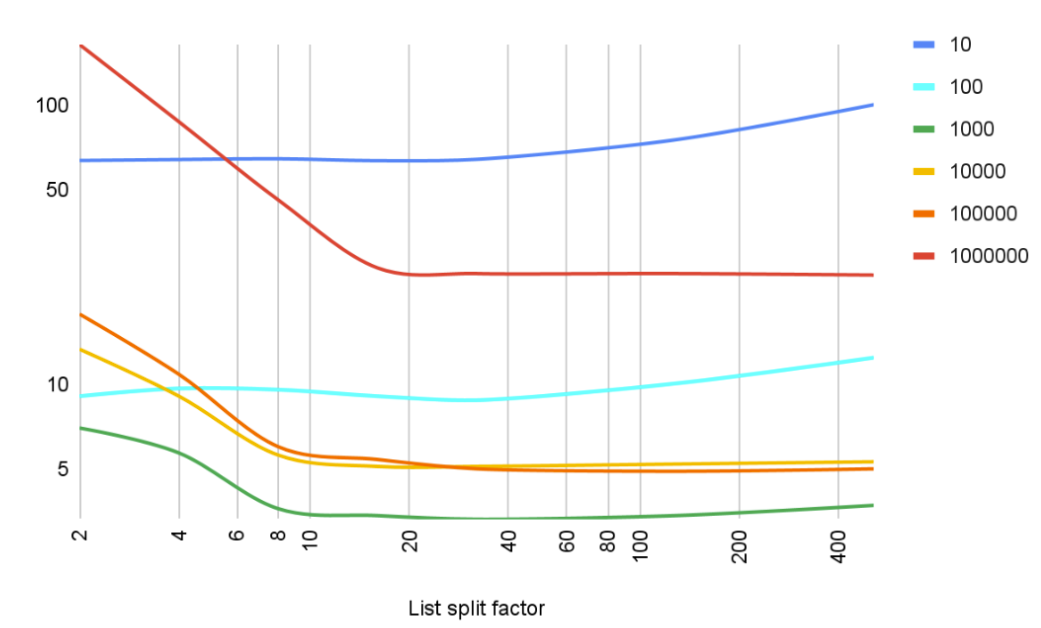
The more we split the list, the worse it seems to behave at small scales, but the better at large scale. Splits at 16 and 32 lanes seem to “saturate” the processor’s parallelism ability. Here’s how the results look at a different angle:
Here, the horizontal axis shows N (the number of lists in the collection), and individual lines on the plot correspond to different collection sizes starting from 10 elements and ending at one million. And both axes are at logarithmic scale too.
At a low scale with 10 and 100 elements, adding more lists doesn’t improve the scanning speed. But at larger scales, 16 parallel lists are indeed the saturation point.
Interestingly, the assembly code of the split-list main loop part contains two times more instructions than the plain list scan.
x: mov %eax,%edx
add $0x1,%eax
and $0xf,%edx
mov -0x78(%rsp,%rdx,8),%rcx
mov 0x10(%rcx),%edi
mov 0x8(%rcx),%rcx
add %rdi,%rsi
mov %rcx,-0x78(%rsp,%rdx,8)
cmp %r8d,%eax
jne x
It also has two times more memory access than the plain list scanning code. Nonetheless, since the memory is better organized, prefetching it in a parallel manner makes this code win in terms of timing.
Comparing different processors (and compilers)
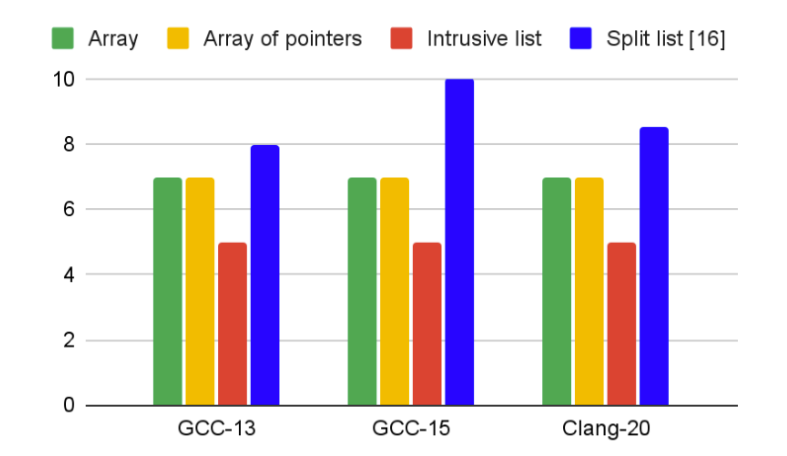
The above measurements were done on an AMD Threadripper processor and the binary was compiled with a GCC-15 compiler. It’s interesting to check what code different compilers render and, more importantly, how different processors behave.
First, let’s look at it with the instructions set. No big surprises here; plain list is the shortest code, split list is the longest:
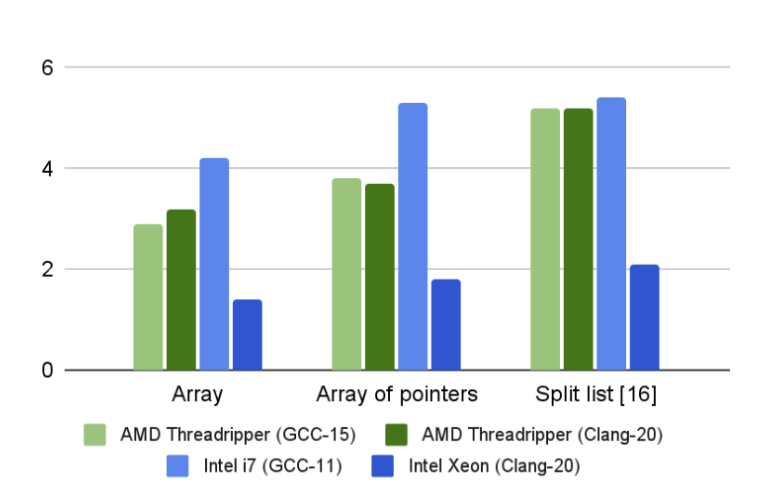
Running the tests on different processors, however, renders very different results. Below are the number of cycles a processor needs to process a single element. Since the plain list is the outlier, it will be shown on its own plot. Here are the top performers – array, array of pointers, and split list:
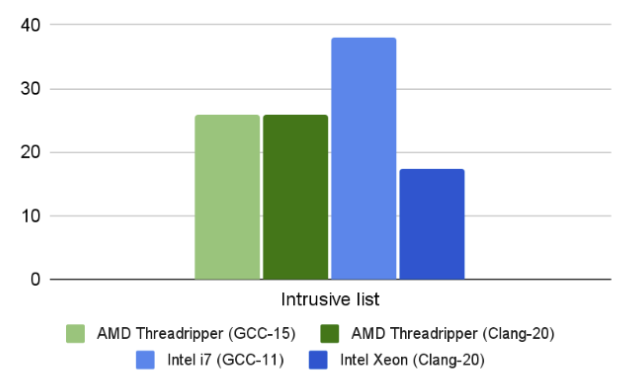
The split list is, as we’ve seen, the slowest one. But it’s not drastically different. More interesting is the way the Xeon processor beats the other competitors.
A similar ratio was measured for plain list processing by different processors:
But, again, even on the Xeon processor, it’s an order of magnitude slower than the split list.
Summing things up
In this article, we explored ways to organize a collection of objects to allow for efficient scanning. We compared four collections – array, intrusive list, array of pointers, and split-list. Since plain arrays have problems maintaining objects independently, we used them as a base reference and mainly compared three other collections with each other to find out which one behaved the best.
From the experiments, we discovered that an array of pointers provided the best timing for single-element access, but required a lot of extra memory. This cost can be mitigated to some extent, but the memory itself doesn’t go away. The split-list approach showed comparable (almost as good) performance. And the advantage of the split-list solution is that it doesn’t require extra memory to work.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}