ScyllaDB Cloud on AWS I8g and I8ge: 2x Throughput, Lower Latency, Zero Extra Cost
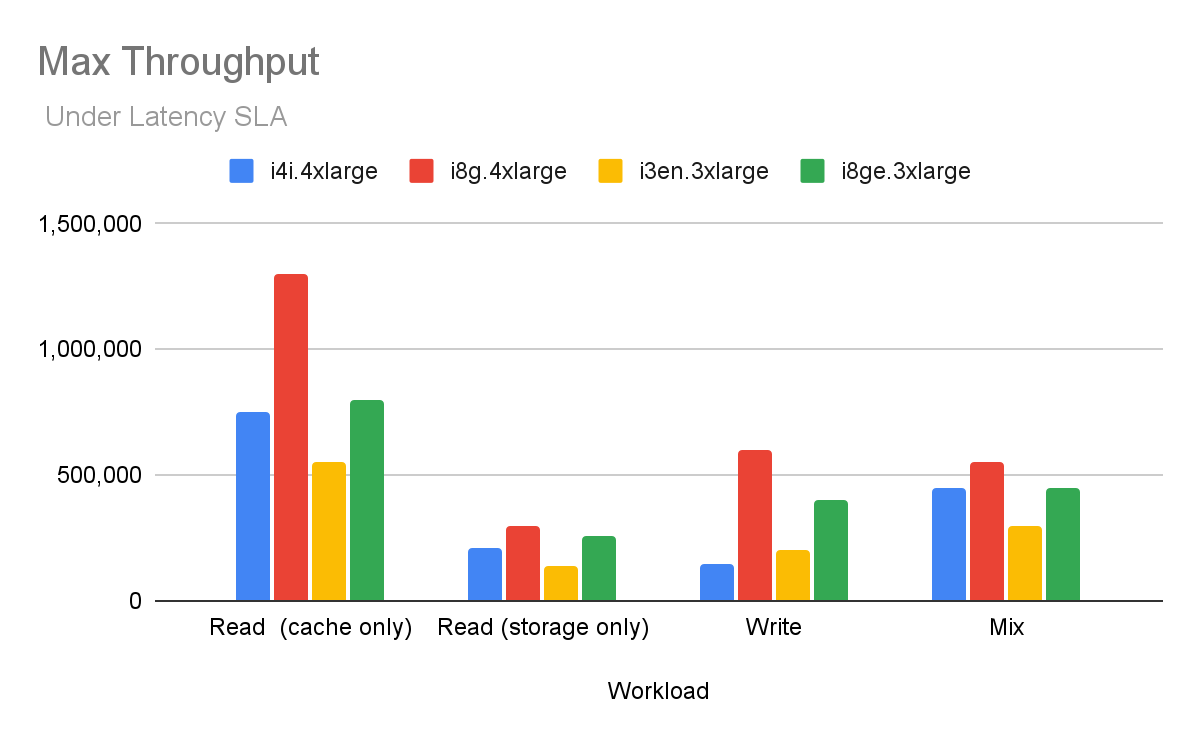
How ScyllaDB performs on the new I8g and I8ge instances, across different workload types Let’s start with the bottom line. For ScyllaDB, the new Graviton4-based i8g instances improve i4i throughput by up to 2x with better latency – and the i8ge improves i3en throughput by up to 2x with better latency. Benchmarks also show single-digit millisecond latency during maintenance operations like scaling. Fast and smooth scaling is an important part of the new ScyllaDB X Cloud offering. The chart below shows ScyllaDB max through under a latency SLA of 10ms latency for different workloads, for the old i4i, i3en and the new i8g, i8ge. AWS recently launched the I8g and I8ge storage-optimized EC2 instances powered by AWS Graviton4 CPUs and 3rd-generation AWS Nitro SSDs. They’re designed for I/O-intensive workloads like real-time databases, search, and analytics (so a nice fit for ScyllaDB). Instance Family Use Case Number of vCPUs per instance Storage i8g Compute bound 2 to 96 0.5 to 22.5 TB i8ge Storage bound 2 to 192 1.25 to 120 TB Reduced TCO in ScyllaDB Cloud Based on our performance results, ScyllaDB users migrating to Graviton4 can reduce infrastructure requirements by up to 50% compared to i4i and i3en previous generations. This translates into significantly lower total cost of ownership (TCO) by requiring fewer nodes to sustain the same workload. These improvements stem from a few factors – both in the new instances themselves, and in the match between ScyllaDB and these instances. The new I8g architecture features: vCPU-to-core mapping: On x86, each vCPU uses half a physical core (a hyperthread); for i8g (ARM), each core matches one physical core Larger caches: 64kB instruction cache and 64kB data cache, compared to 32/48kB on Intel (shared between the two hyperthreads) Faster storage and networking (see spec above) In addition, ScyllaDB’s design allows it to take full advantage of the new server types: The shard-per-core architecture scales with linear performance to any number of cores The IO scheduler can take full advantage of the 3rd-generation AWS Nitro SSD, fully utilizing the higher IO rate, and lower latency without overloading it and increasing latency ARM’s relaxed memory model suits Seastar applications. Since locks and fences are rare, the memory subsystem has more opportunities to reorder memory accesses to optimize performance. What this means for you I8g and i8ge are now available on ScyllaDB Cloud. If you’re running ScyllaDB Cloud, the net impact is: Compute-bound workloads: Move from I4i to I8g. This should provide up to 2x throughput at the same ScyllaDB Cloud price. Storage-bound workloads: Move from I3en to I8ge. Here, you should expect up to 2x higher throughput at the same ScyllaDB Cloud price. Note that using the new ScyllaDB dictionary-based compression can lower the storage cost further. For both use cases, ScyllaDB can keep the 10ms P99 latency SLA during maintenance operations, including scaling out and scaling down. What we measured Max Throughput: The maximum requests per second the database can handle Max Throughput under SLA: The maximum request per second under a P99 latency of 10ms. Only throughput with latency below this SLA counts. This throughput can be sustained under any operation, like scaling and repair. This is the number you should use when sizing your ScyllaDB Database on i8g instances. P99 Latency: Measures the p99 latency for the Max Throughput under SLA Results Read Workload – cached data Cached data: working set size < available RAM, resulting in close to 100% cache hit rate. Instance type Max throughput Max Throughput Under Latency SLA Improvement P99 in ms i4i.4xlarge 1,062,578 750,000 100% 7.84 i8g.4xlarge 1,434,215 1,300,000 135% 6.29 i3en.3xlarge 585,975 550,000 100% 4.37 i8ge.3xlarge 962,504 800,000 164% 6.38 Read Workload – non-cached data, storage only Non-cached data: working set size >> available RAM, resulting in 0% cache hit rate. When most of the data is not cached, storage becomes a significant factor for performance. Instance type Max throughput Max Throughput Under Latency SLA Improvement P99 in ms i4i.4xlarge 218,674 210,000 100% 4.56 i8g.4xlarge 444,548 300,000 203% 4.24 i3en.3xlarge 145,702 140,000 100% 6.83 i8ge.3xlarge 259,693 255,000 178% 7.95 Write Workload Instance type Max throughput Max Throughput Under Latency SLA Improvement P99 in ms i4i.4xlarge 289,154 150,000 100% 2.4 i8g.4xlarge 689,474 600,000 238% 4.02 i3en.3xlarge 217,072 200,000 100% 5.42 i8ge.3xlarge 452,968 400,000 209% 3.41 Tests under maintenance operations ScyllaDB takes pride in testing under realistic use cases, including scaling out and in, repair, backups, and various failure tests. The following results represent the P99 average latency (across all nodes) of different maintenance operations on a 3-node cluster of i8ge.3xlarge. It’s using the same setup as above. Setup ScyllaDB version: 2025.3.1-20250907.2bbf3cf669bb DB node amount: 3 DB instance types: i8ge.3xlarge Loader node amount: 4 Loader instance type: c5.2xlarge Throughput: Read 41K, write 81K, Mixed 35K Results Read Test: Read Latency Operation Read P99 latency in ms Base: Steady State 0.95 During Repair 4.92 During Add Node (out scale) 2.68 During Replace Node 3.10 During Decommission Node (downscale) 2.44 Write Test: Write Latency Operation Write P99 latency in ms Steady State 2.22 During Repair 3.24 Add Node (scale out) 2.49 Replace Node 3.07 Decommission Node (downscale) 2.37 Mixed Test: Write and Read Latency Operation Write P99 Latency in ms Read P99 Latency in ms Steady state 2.03 2.11 During Repair 3.21 4.70 Add Node (scale out) 2.19 2.71 Replace Node 3.00 3.37 Decommission Node (downscale) 2.20 3.05 The results indicate that ScyllaDB can meet the latency SLA under maintenance operations. This is critical for ScyllaDB Cloud, and in particular ScyllaDB X Cloud, where scaling out and in scaling are automatic, and can happen multiple times per day. It’s also critical in unexpected failure cases, when a node must be replaced rapidly, without hurting availability and the latency SLA. Test Setup ScyllaDB cluster 3-node cluster I4i.4xlarge vs. i8g.4xlarge I3en.3xlarge vs. i8ge.3xlarge Loaders Loader node amount: 4 Loader instance type: c7i.8xlarge Workload Replication Factor (RF): 3 Consistency Level (CL): Quorum Data size 650GB for read/mixed, 1.5T for write
{kind=link}