ScyllaDB Vector Search: 1B Vectors with 2ms P99s and 250K QPS Throughput

Results from a benchmark using the yandex-deep_1b dataset, which contains 1 billion vectors of 96 dimensions
As AI-driven applications move from experimentation into real-time production systems, the expectations placed on vector similarity search continue to rise dramatically. Teams now need to support billion-scale datasets, high concurrency, strict p99 latency budgets, and a level of operational simplicity that reduces architectural overhead rather than adding to it.
ScyllaDB Vector Search was built with these constraints in mind. It offers a unified engine for storing structured data alongside unstructured embeddings, and it achieves performance that pushes the boundaries of what a managed database system can deliver at scale. The results of our recent high scale 1-billion-vector benchmark show that ScyllaDB demonstrates both ultra-low latency and highly predictable behaviour under load.
Architecture at a Glance
To achieve low-single-millisecond performance across massive vector sets, ScyllaDB adopts an architecture that separates the storage and indexing responsibilities while keeping the system unified from the user’s perspective. The ScyllaDB nodes store both the structured attributes and the vector embeddings in the same distributed table. Meanwhile, a dedicated Vector Store service – implemented in Rust and powered by the USearch engine optimized to support ScyllaDB’s predictable single-digit millisecond latencies – consumes updates from ScyllaDB via CDC and builds approximate-nearest-neighbour (ANN) indexes in memory. Queries are issued to the database using a familiar CQL expression such as:
SELECT … ORDER BY vector_column ANN_OF ? LIMIT k;
They are then internally routed to the Vector Store, which performs the similarity search and returns the candidate rows. This design allows each layer to scale independently, optimising for its own workload characteristics and eliminating resource interference.
Benchmarking 1 Billion Vectors
To evaluate real-world performance, ScyllaDB ran a rigorous benchmark using the publicly available yandex-deep_1b dataset, which contains 1 billion vectors of 96 dimensions. The setup consisted of six nodes: three ScyllaDB nodes running on i4i.16xlarge instances, each equipped with 64 vCPUs, and three Vector Store nodes running on r7i.48xlarge instances, each with 192 vCPUs. This hardware configuration reflects realistic production deployments where the database and vector indexing tiers are provisioned with different resource profiles. The results focus on two usage scenarios with distinct accuracy and latency goals (detailed in the following sections).
A full architectural deep-dive, including diagrams, performance trade-offs, and extended benchmark results for higher-dimension datasets, can be found in the technical blog post Building a Low-Latency Vector Search Engine for ScyllaDB. These additional results follow the same pattern seen in the 96-dimensional tests: exceptionally low latency, high throughput, and stability across a wide range of concurrent load profiles.
Scenario #1 — Ultra-Low Latency with Moderate Recall
The first scenario was designed for workloads such as recommendation engines and real-time personalisation systems, where the primary objective is extremely low latency and the recall can be moderately relaxed. We used index parameters m = 16, ef-construction = 128, ef-search = 64 and Euclidean distance.
At approximately 70% recall and with 30 concurrent searches, the system maintained a p99 latency of only 1.7 milliseconds and a p50 of just 1.2 milliseconds, while sustaining 25,000 queries per second.
When expanding the throughput window (still keeping p99 latency below 10 milliseconds), the cluster reached 60,000 QPS for k = 100 with a p50 latency of 4.5 milliseconds, and 252,000 QPS for k = 10 with a p50 latency of 2.2 milliseconds. Importantly, utilizing ScyllaDB’s predictable performance, this throughput scales linearly: adding more Vector Store nodes directly increases the achievable QPS without compromising latency or recall.
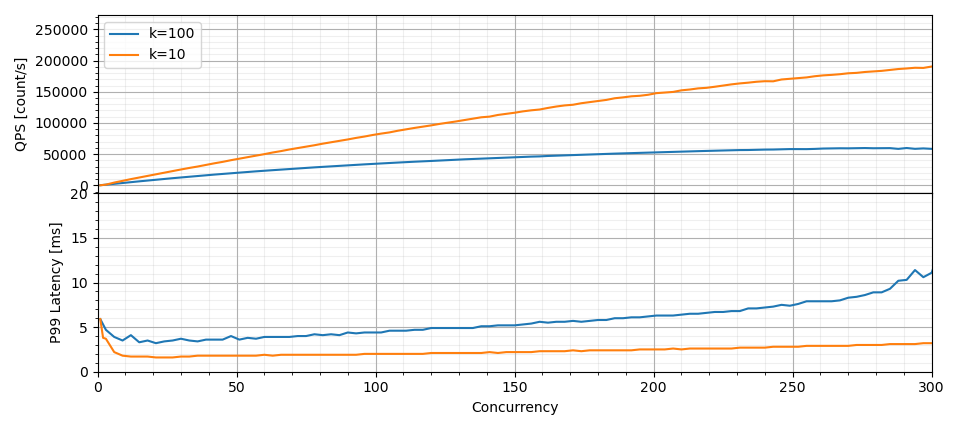 Latency and throughput depending on the concurrency level for recall equal to 70%.
Latency and throughput depending on the concurrency level for recall equal to 70%.
Scenario #2 — High Recall with Slightly Higher Latency
The second scenario targets systems that require near-perfect recall, including high-fidelity semantic search and retrieval-augmented generation pipelines. Here, the index parameters were significantly increased to m = 64, ef-construction = 512, and ef-search = 512. This configuration raises compute requirements but dramatically improves recall.
With 50 concurrent searches and recall approaching 98%, ScyllaDB kept p99 latency below 12 milliseconds and p50 around 8 milliseconds while delivering 6,500 QPS. When shifting the focus to maximum sustained throughput while keeping p99 latency under 20 milliseconds and p50 under 10 milliseconds, the system achieved 16,600 QPS. Even under these settings, latency remained notably stable across values of k from 10 to 100, demonstrating predictable behaviour in environments where query limits vary dynamically.
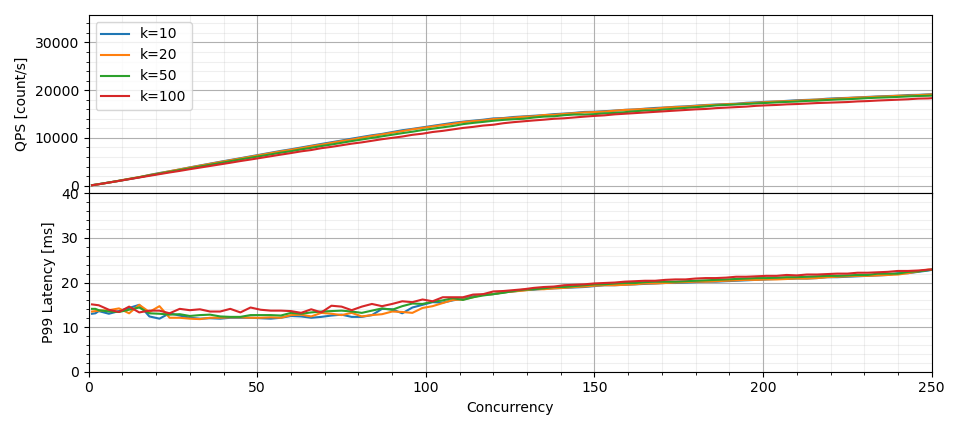
Latency and throughput depending on the concurrency level for recall equal to 98%.
Detailed results
The table below presents the summary of the results for some representative concurrency levels.
| Run 1 | Run 2 | Run 3 | |
|---|---|---|---|
| m | 16 | 16 | 64 |
| efconstruct | 128 | 128 | 512 |
| efsearch | 64 | 64 | 512 |
| metric | Euclidean | Euclidean | Euclidean |
| upload | 3.5 h | 3.5 h | 3.5 h |
| build | 4.5 h | 4.5 h | 24.4 h |
| p50 [ms] | 2.2 | 1.7 | 8.2 |
| p99 [ms] | 9.9 | 4 | 12.3 |
| qps | 252,799 | 225,891 | 10,206 |
Unified Vector Search Without the Complexity
A big advantage of integrating Vector Search with ScyllaDB is that it delivers substantial performance and networking cost advantages. The vector store resides close to the data with just a single network hop between metadata and embedding storage in the same availability zone. This locality, combined with ScyllaDB’s shard-per-core execution model, allows the system to provide real-time latency and massive throughput even under heavy load. The result is that teams can accomplish more with fewer resources compared to specialised vector-search systems.
In addition to being fast at scale, ScyllaDB’s Vector Search is also simpler to operate. Its key advantage is its ability to unify structured and unstructured retrieval within a single dataset. This means you can store traditional attributes and vector embeddings side-by-side and express hybrid queries that combine semantic search with conventional filters. For example, you can ask the database to “find the top five most similar documents, but only those belonging to this specific customer and created within the past 30 days.” This approach eliminates the common pain of maintaining separate systems for transactional data and vector search, and it removes the operational fragility associated with syncing between two sources of truth.
This also means there is no ETL drift and no dual-write risk. Instead of shipping embeddings to a separate vector database while keeping metadata in a transactional store, ScyllaDB consolidates everything into a single system. The only pipeline you need is the computational step that generates embeddings using your preferred LLM or ML model. Once written, the data remains consistent without extra coordination, backfills, or complex streaming jobs.
Operationally, ScyllaDB simplifies the entire retrieval stack. Because it is built on ScyllaDB’s proven distributed architecture, the system is highly available, horizontally scalable, and resilient across availability zones and regions. Instead of operating two or three different technologies – each with its own monitoring, security configurations, and failure modes – you only manage one. This consolidation drastically reduces operational complexity while simultaneously improving performance.
Public Preview and Roadmap
The vector search feature is currently offered in public preview, with a clear path toward general availability and a set of enhancements focused on performance, flexibility, and developer experience.
The GA release is planned at the beginning of Q1’26 and will include Cloud Portal provisioning, on-demand billing, a full range of instance types, self-service scaling and additional performance optimisations. By the end of Q1 we will introduce native filtering capabilities, enabling vector search queries to combine ANN results with traditional predicates for more precise hybrid retrieval.
Looking further ahead, the roadmap includes support for scalar and binary quantisation to reduce memory usage, TTL functionality for lifecycle automation of vector data, and integrated hybrid search combining ANN with BM25 for unified lexical and semantic relevance.
Conclusion
ScyllaDB has demonstrated that it is capable of delivering industry-leading performance for vector search at massive scale, handling a dataset of 1 billion vectors with p99 latency as low as 1.7 milliseconds and throughput up to 252,000 QPS. These results validate ScyllaDB Vector Search as a unified, high-performance solution that simplifies the operational complexity of real-time AI applications by co-locating structured data and unstructured embeddings.
The current benchmarks showcase the current state of ScyllaDB’s scalability. With planned enhancements in the upcoming roadmap, including scalar quantization and sharding, these performance limits are set to increase in the next year. Nevertheless, even now, the feature is ready for running latency critical workloads such as fraud detection or recommendation systems.