Cut LLM Costs and Latency with ScyllaDB Semantic Caching
How semantic caching can help with costs and latency as you scale up your AI workload
Developers building large-scale LLM solutions often rely on powerful APIs such as OpenAI’s. This approach outsources model hosting and inference, allowing teams to focus on application logic rather than infrastructure. However, there are two main challenges you might face as you scale up your AI workload: high costs and high latency.
This blog post introduces semantic caching as a possible solution to these problems. Along the way, we cover how ScyllaDB can help implement semantic caching.
What is semantic caching?
Semantic caching follows the same principle as traditional caching: storing data in a system that allows faster access than your primary source. In conventional caching solutions, that source is a database. In AI systems, the source is an LLM.
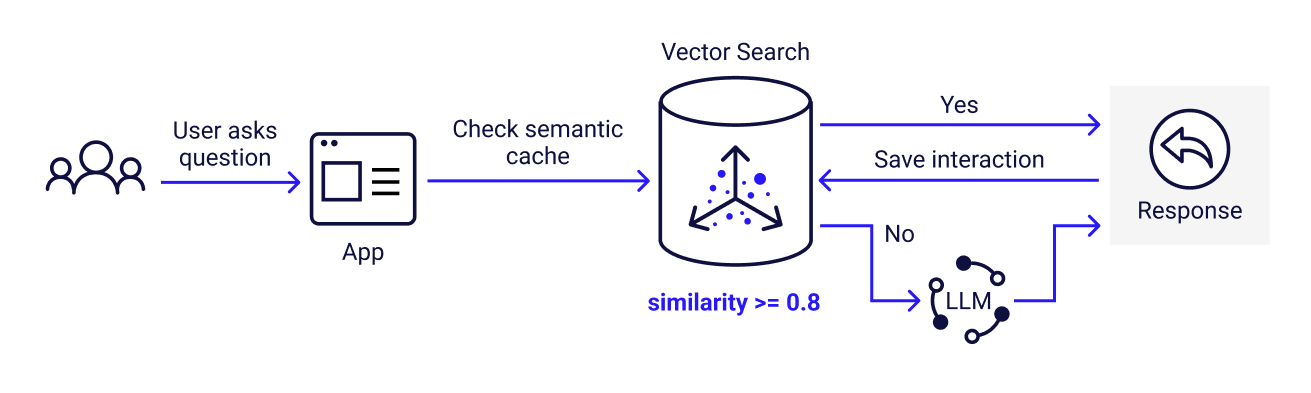
Here’s a simplified semantic caching workflow:
User sends a question (“What is ScyllaDB?”)
Check if this type of question has been asked before (for example “whats scylladb” or “Tell me about ScyllaDB”)
If yes, deliver the response from cache
If no
a)Send the request to LLM and deliver the response from there
b) Save the response to cache
Semantic caching stores the meaning of user queries as vector embeddings and uses vector search to find similar ones. If there’s a close enough match, it returns the cached result instead of calling the LLM. The more queries you can serve from the cache, the more you save on cost and latency over time.
Invalidating data is just as important for semantic caching as it is for traditional caching. For instance, if you are working with RAGs (where the underlying base information can change over time), then you need to invalidate the cache periodically so it returns accurate information.
For example, if the user query is “What’s the most recent version of ScyllaDB Enterprise,” the answer depends on when you ask this question. The cached response to this answer must be refreshed accordingly (assuming the only context your LLM works with is the one provided by the cache).
Why use a semantic cache?
Simply put, semantic caching saves you money and time. You save money by making fewer LLM calls, and you save time from faster responses. When a use case involves repeated or semantically similar queries, and identical responses are acceptable, semantic caching offers a practical way to reduce both inference costs and latency.
Heavy LLM usage might put you on OpenAI’s top spenders list. That’s great for OpenAI. But is it great for you? Sure, you’re using cutting-edge AI and delivering value to users, but the real question is: can you optimize those costs?
Cost isn’t the only concern. Latency matters too. LLMs inherently cannot achieve sub-millisecond response times. But users still expect instant responses. So how do you bridge that gap? You can combine LLM APIs with a low-latency database like ScyllaDB to speed things up. Combining AI models with traditional optimization techniques is key to meeting strict latency requirements.
Semantic caching helps mitigate these issues by caching LLM responses associated with the input embeddings. When a new input is received, its embedding is compared to those stored in the cache. If a similar-enough embedding is found (based on a defined similarity threshold), the saved response is returned from the cache. This way, you can skip the round trip to the LLM provider.
This leads to two major benefits:
Lower latency: No need to wait for the LLM to generate a new response. Your low-latency database will always return responses faster than an LLM.
Lower cost: Cached responses are “free” – no LLM API fees. Unlike LLM calls, database queries don’t charge you per request or per token.
Why use ScyllaDB for semantic caching?
From day one, ScyllaDB has focused on three things: cutting latency, cost, and operational overhead. All three of those things matter just as much for LLM apps and semantic caching as they do for “traditional” applications.
Furthermore, ScyllaDB is more than an in-memory cache. It’s a full-fledged high-performance database with a built-in caching layer. It offers high availability and strong P99 latency guarantees, making it ideal for real-time AI applications.
ScyllaDB has recently added Vector Search offering, which is essential for building a semantic cache, and it’s also used for a wide range of AI and LLM-based applications. For example, it’s quite commonly used as a feature store. In short, you can consolidate all your AI workloads into a single high-performance, low-latency database.
Now let’s see how you can implement semantic caching with ScyllaDB.
How to implement semantic caching with ScyllaDB
> If you just want to dive in, clone the repo, and try it yourself, check out the GitHub repository here.
Here’s a simplified, general guide on how to implement semantic caching with ScyllaDB (using Python examples):
1. Create a semantic caching schema
First, we create a keyspace, then a table called prompts, which will act as our cache table. It includes the following columns:
prompt_id: The partition key for the table.
Inserted_at: Stores the timestamp when the row was originally inserted (the response first cached)
prompt_text: The actual input provided by the user, such as a question or query.
prompt_embedding: The vector embedding representation of the user input.
llm_response: The LLM’s response for that prompt, returned from the cache when a similar prompt appears again.
updated_at: Timestamp of when the row was last updated, useful if the underlying data changes and the cached response needs to be refreshed.
Finally, we create an ANN (Approximate Nearest Neighbor) index on the prompt_embedding column to enable fast and efficient vector searches.
Now that ScyllaDB is ready to receive and return responses, let’s implement semantic caching in our application code.
2. Convert user input to vector embedding
Take the user’s text input (which is usually a question or some kind of query) and convert it into an embedding using your chosen embedding model. It’s important that the same embedding model is used consistently for both cached data and new queries.
In this example, we’re using a local embedding model from sentence transformers. In your application, you might use OpenAI or some other embedding provider platform.
3. Calculate similarity score
Use ScyllaDB Vector Search syntax: `ANN OF` to find semantically similar entries in the cache.
There are two key components in this part of the application.
Similarity score: You need to calculate the similarity between the user’s new query and the most similar item returned by vector search. Cosine similarity, which is the most frequently used similarity function in LLM-based applications, ranges from 0 to 1. A similarity of 1 means the embeddings are identical. A similarity of 0 means they are completely dissimilar.
Threshold: Determines whether the response can be provided from cache. If the similarity score is above that threshold, it means the new query is similar enough to one already stored in the cache, so the cached response can be returned. If it falls below the threshold, the system should fetch a fresh response from the LLM. The exact threshold should be tuned experimentally based on your use case.
4. Implement cache logic
Finally, putting it all together, you need a function that decides whether to serve a response from the cache or make a request to the LLM.
If the user query matches something similar in the cache, follow the earlier steps and return the cached response. If it’s not in the cache, make a request to your LLM provider, such as OpenAI, return that response to the user, and then store it in the cache. This way, the next time a similar query comes in, the response can be served instantly from the cache.
Get started!
Get started building with ScyllaDB; check out our examples on GitHub:
` git clone https://github.com/scylladb/vector-search-examples.git
{kind=link}