Happn: Falling in Love with ScyllaDB

Happn was born in 2014 with the mission to make finding the people you cross paths with easier. To the Happn founders, fate plays a large part in where we find ourselves in life. Happn helps by making you aware of those nearby who may share the same romantic inclinations as you. Their vision is that the love you find online should be as authentic as if you met face-to-face in real life; technology just gives a helping hand to destiny by allowing singles who have crossed paths to find each other on the app.
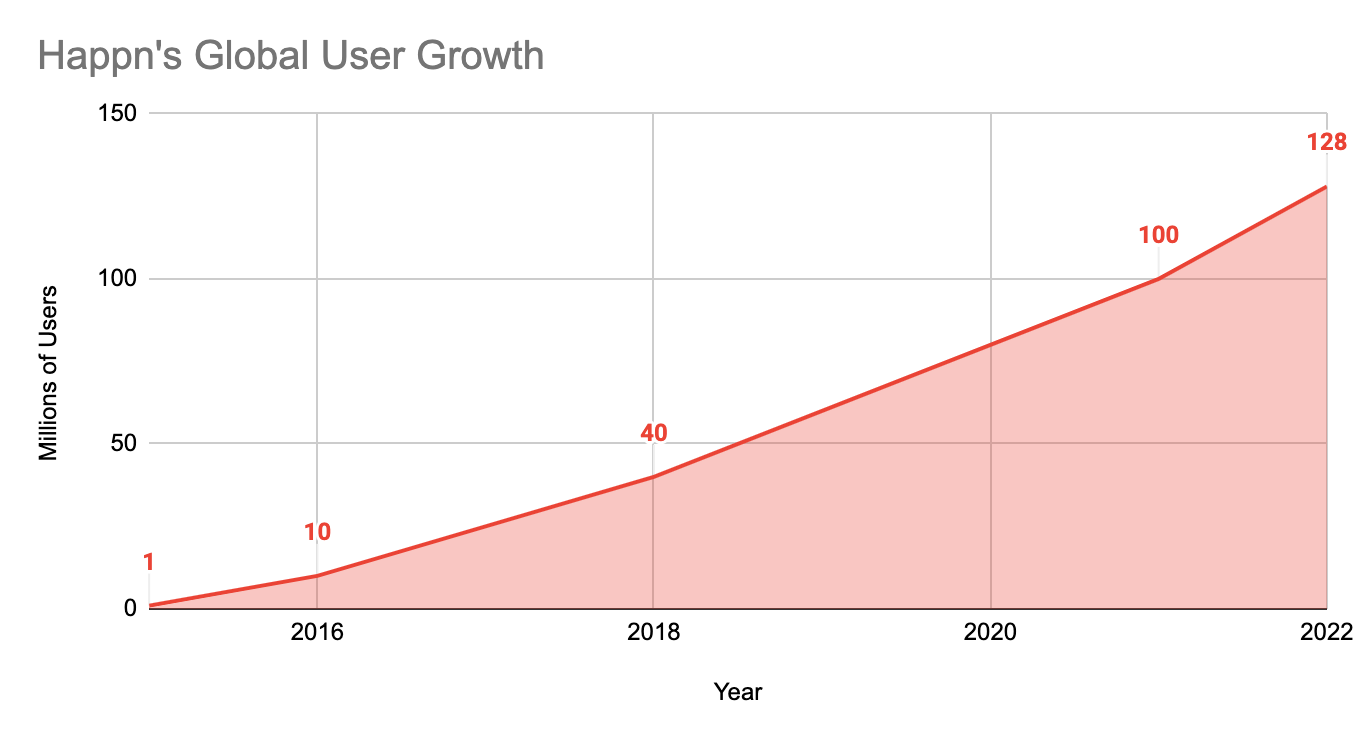
Happn has grown from 1 million users in 2015 to over 128 million users in 2022.
Their strategy has resonated with singles around the world. Happn is one of the most downloaded online dating apps on the planet, active in forty countries with users primarily located in Western Europe, South America, Turkey and India. To date, 126 million people have signed up for the Happn app.

Happn has been part of the FT120 ranking of the French tech sector for two years in a row. Their team reflects their corporate ethos. They are young and cosmopolitan; the average employee age is 31 and 40% of their staff are women. Happn’s staff, now grown to around 100 employees, comprises 18 nationalities.
Falling In Love with ScyllaDB
One of the staff at Happn, Senior Platform Engineer Robert Czupiol, described their path to falling in love with our database at ScyllaDB Summit 2022.
Early in their growth Happn adopted Apache Cassandra. Yet by 2021 the relationship had soured. There were many issues with using Cassandra:
- Total Cost of Ownership (TCO)
- Technical debt
- Managing growing volumes of data
- Minimizing latencies
- Real-time monitoring
Technical debt was incurred in great part by running a very old version of Cassandra 2.1, originally released in 2014. They were also running a down-rev version of Debian 8 (released in 2015) which they knew they needed to upgrade. Yet because of the other compounding factors the Happn team looked beyond just upgrading to the current Cassandra and Debian releases to solve their broader issues. After internal analysis the decision was made to move to ScyllaDB.
Happn migrated fourteen of their clusters from Cassandra to ScyllaDB, the main one of which stores over 20 terabytes of data and at peak times hitting over 300,000 operations per second. While setting up dual writes and then making a cut-over is a standard procedure for migrations, one cluster proved a bit more complicated.
The second biggest cluster was known as the “Crossings Cluster.” This was responsible for tracking when two individuals who might be potentially romantically interested in each other came within physical proximity — an important event the server wanted to count. This Cassandra cluster, running on Google Cloud, comprised 48 e2-highmem-4 nodes, each of which had 4 CPUs, 32 GB of RAM, and 1 TB of networked persistent SSD (PD-SSD). This Crossings_count table alone comprised 68 billion records, and collectively they had over 88 billion records total to migrate.
The problem with migrating counter data from Cassandra to ScyllaDB was to ensure they weren’t double counting across the two systems. For example, if you had records with values of 26, 27, and 28 on Cassandra, and just started up a corresponding counter table on ScyllaDB, it would have initial values of 1, 2, 3. If you tried to later merge the Cassandra table data, you could end up double-counting or totally miscounting activities.
To solve this, Happn invented their own Java-based counter-migrator, which did a compare-and-set operation. This double-checked the latest value in Cassandra, and set ScyllaDB to that latest value. However, with their scale they still had issues with performance and memory consumption of the Java app, so they eventually moved their code to Golang.
When finally in full production operations on ScyllaDB, the results were significantly better. P99 latencies dropped from 80 ms to only 20 ms — four times better. P90 latencies dropped from 50ms down to 15ms — over three times better.
Happn also saved significantly on disk space. With Cassandra they were using upwards of 48 TB total storage. With ScyllaDB that figure dropped to only 18 TB — about a third. These savings were attributable to three main factors:
- The more compact “md” format for SSTables
- More aggressive compaction ScyllaDB could manage with its custom IO scheduler, and
- ScyllaDB’s support for Zstandard (Zstd) compression.
Because ScyllaDB could vertically scale up to bigger nodes and use significantly less storage overall, Happn was able to shrink its cluster footprint from 48 nodes of Cassandra to just 6 nodes with ScyllaDB.
Happn also reduced their Google Cloud Storage (GCS) budget by going to incremental snapshot backups. Finally, knowing they could at last manage the scale of their growth they moved to committed annual contracts. Overall Happn reduced their total cost of ownership (TCO) by 75%.
The Romance Continues to Bloom
Robert’s presentation at ScyllaDB Summit 2022 was held the week just before Valentine’s Day in February. Much has changed since then. I had the opportunity to interview Robert to find out how the romance has continued to bloom between Happn and ScyllaDB.
To serve their global community Happn now performs between 200K to 350k read ops/second, and 45k to 80k write ops/second, depending on the time of day.
They have continued to shift workloads to ScyllaDB. Now, their total node count is 51 n2 series servers using fast local NVMe SSD. These can store 91 TB of total capacity. 60 TBs of that capacity is currently occupied, with the biggest cluster now being 25 TB of data.
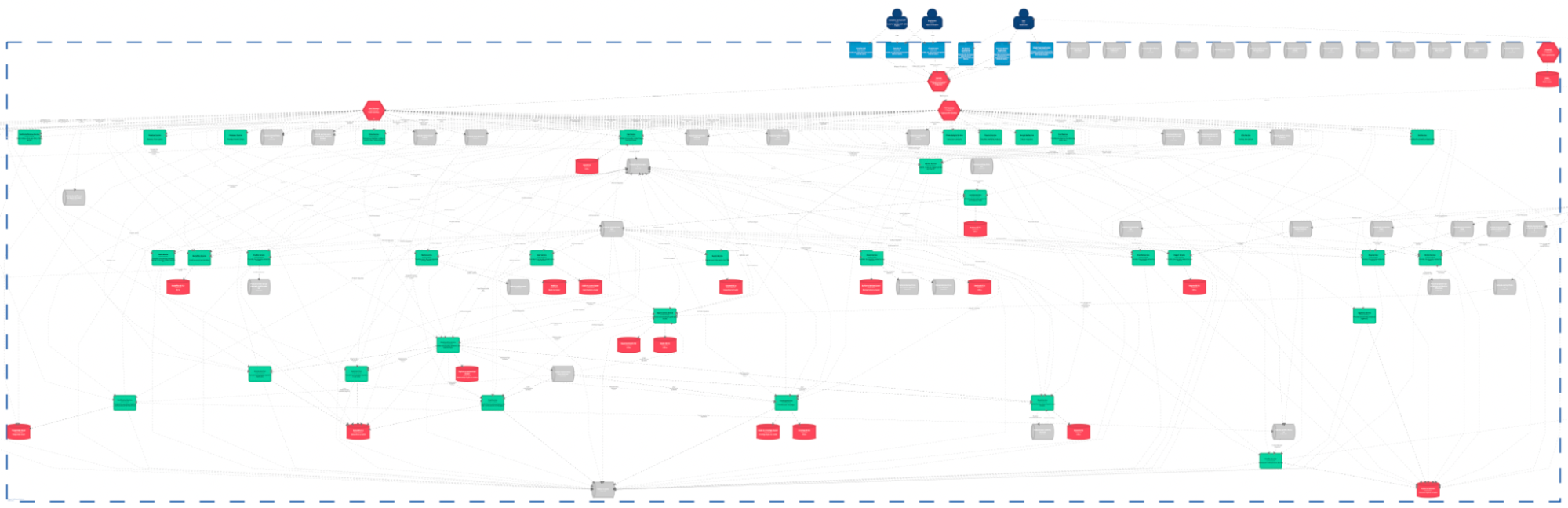
Block diagram showing the extents of ScyllaDB in use at Happn. Red rectangles are ScyllaDB clusters. Green rectangles are microservices.
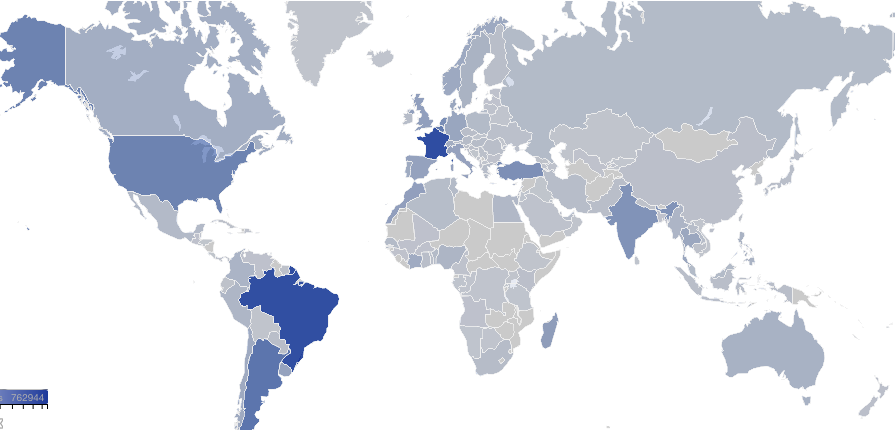
Heat map of where Happn’s current global daily requests come from
Looking to Build a Community of a Hundred Million or More?
Happn isn’t alone in falling in love with ScyllaDB. Along with Asian-based dating app Tantan, Happn shows how ScyllaDB can be used to build relationships within communities of a hundred million people or more using our fast and scalable NoSQL database.
Beyond online dating, Discord has built their platform using ScyllaDB as its core storage engine for over 350 million users, and online shopping giant Rakuten has grown their product catalog to more than a billion products which you can browse through and buy.
If you are interested in scaling your own business we’d love to hear. Please contact us directly, or join our Slack community to discuss your use case with your fellow big data monsters.