From ScyllaDB to Kafka: Natura’s Approach to Real-Time Data at Scale
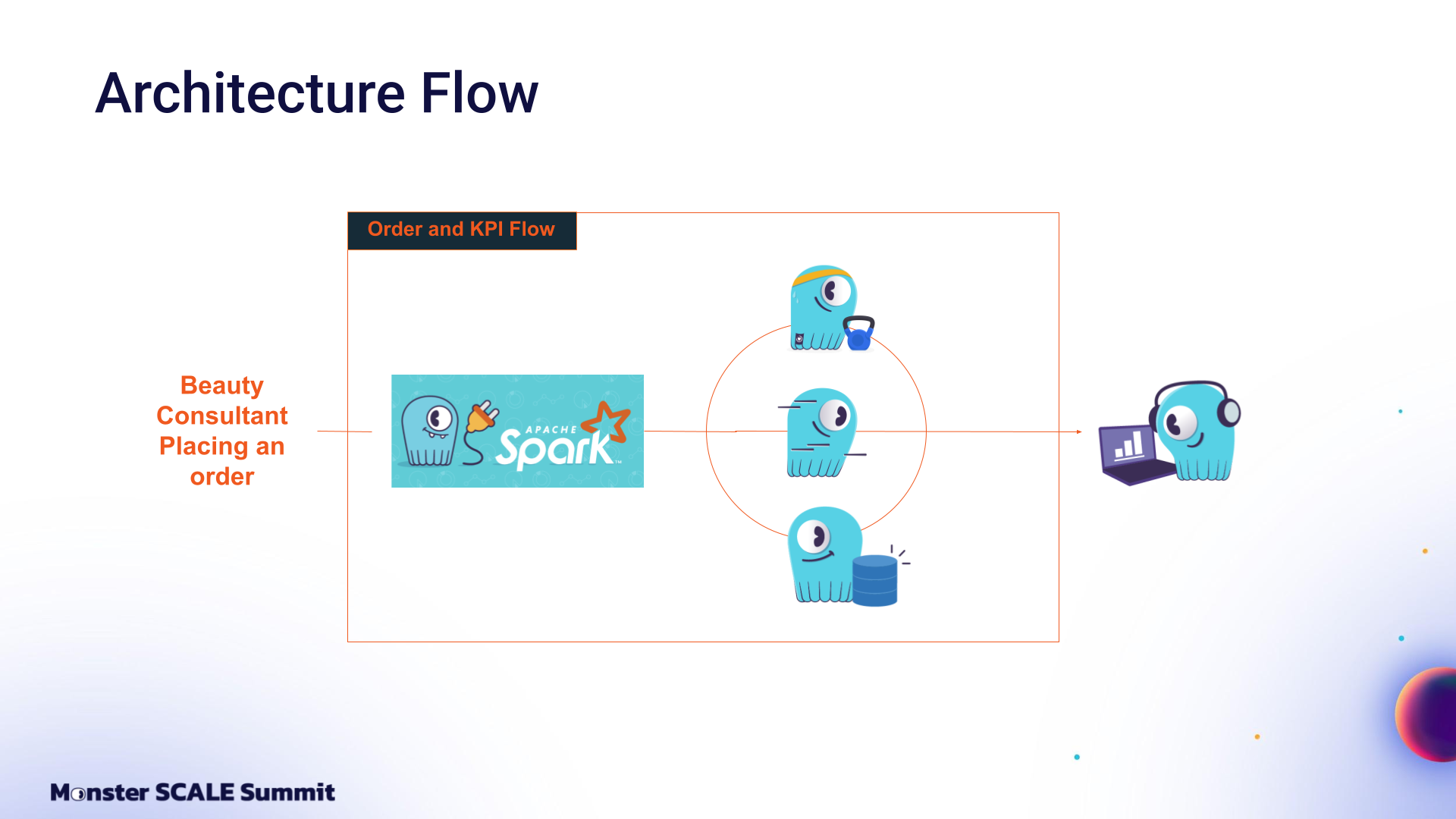
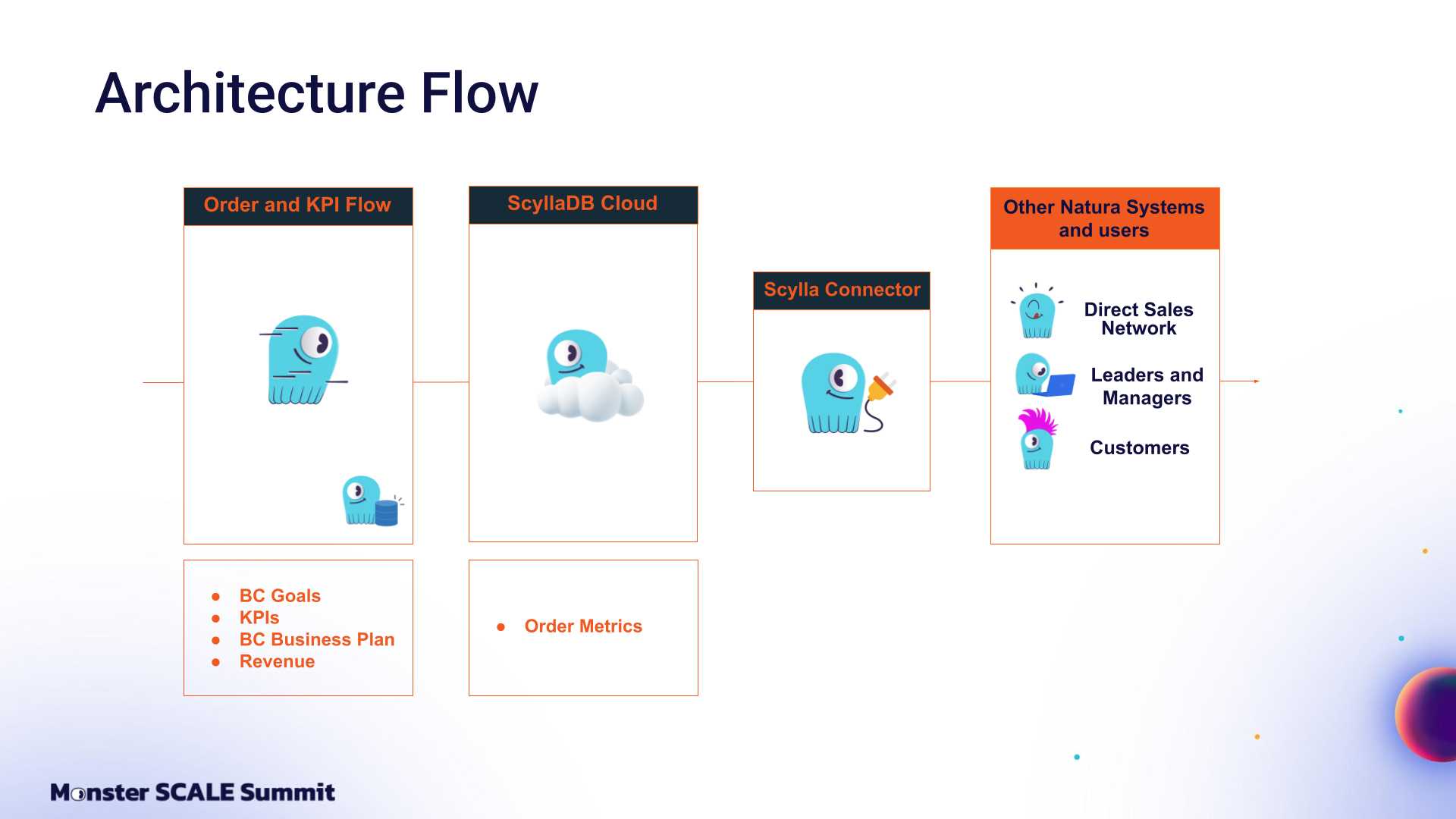
How Natura built a real-time data pipeline to support orders, analytics, and operations Natura, one of the world’s largest cosmetics companies, relies on a network of millions of beauty consultants generating a massive amount of orders, events, and business data every day. From an infrastructure perspective, this requires processing vast amounts of data to support orders, campaigns, online KPIs, predictive analytics, and commercial operations. Natura’s Rodrigo Luchini (Software Engineering Manager) and Marcus Monteiro (Senior Engineering Tech Lead) shared the technical challenges and architecture behind these use cases at Monster SCALE Summit 2025. Fitting for the conference theme, they explained how the team powers real-time sales insights at massive scale by building upon ScyllaDB’s CDC Source Connector. About Natura Rodrigo kicked off the talk with a bit of background on Natura. Natura was founded in 1969 by Antônio Luiz Seabra. It is a Brazilian multinational cosmetics and personal care company known for its commitment to sustainability and ethical sourcing. They were one of the first companies to focus on products connected to beauty, health, and self-care. Natura has three core pillars: Sustainability: They are committed to producing products without animal testing and to supporting local producers, including communities in the Amazon rainforest. People: They value diversity and believe in the power of relationships. This belief drives how they work at Natura and is reflected in their beauty consultant network. Technology: They invest heavily in advanced engineering as well as product development. The Technical Challenge: Managing Massive Data Volume with Real-Time Updates The first challenge they face is integrating a high volume of data (just imagine millions of beauty consultants generating data and information every single day). The second challenge is having real-time updated data processing for different consumers across disconnected systems. Rodrigo explained, “Imagine two different challenges: creating and generating real-time data, and at the same time, delivering it to the network of consultants and for various purposes within Natura.” This is where ScyllaDB comes in. Here’s a look at the initial architecture flow, focusing on the order and API flow. As soon as a beauty consultant places an order, they need to update and process the related data immediately. This is possible for three main reasons: As Rodrigo put it, “The first is that ScyllaDB is a fast database infrastructure that operates in a resilient way. The second is that it is a robust database that replicates data across multiple nodes, which ensures data consistency and reliability. The last but not least reason is scalability – it’s capable of supporting billions of data processing operations.” The Natura team architected their system as follows: In addition to the order ingestion flow mentioned above, there’s an order metrics flow closely connected to ScyllaDB Cloud (ScyllaDB’s fully-managed database-as-a-service offering), as well as the ScyllaDB CDC Source Connector (A Kafka source connector capturing ScyllaDB CDC changes). Together, this enables different use cases in their internal systems. For example, it’s used to determine each beauty consultant’s business plan and also to report data across the direct sales network, including beauty consultants, leaders, and managers. These real-time reports drive business metrics up the chain for accurate, just-in-time decisions. Additionally, the data is used to define strategy and determine what products to offer customers. Contributing to the ScyllaDB CDC Source Connector When Natura started testing the ScyllaDB Connector, they noticed a significant spike in the cluster’s resource consumption. This continued until the CDC log table was fully processed, then returned to normal. At that point, the team took a step back. After reviewing the documentation, they learned that the connector operates with small windows (15 seconds by default) for reading the CDC log tables and sending the results to Kafka. However, at startup, these windows are actually based on the table TTL, which ranged from one to three days in Natura’s use case. Marcus shared: “Now imagine the impact. A massive amount of data, thousands of partitions, and the database reading all of it and staying in that state until the connector catches up to the current time window. So we asked ourselves: ‘Do we really need all the data?’ No. We had already run a full, readable load process for the ScyllaDB tables. What we really needed were just incremental changes, not the last three days, not the last 24 hours, just the last 15 minutes.” So, as ScyllaDB was adding this feature to the GitHub repo, the Natura team created a new option: scylla.custom.window.start. This let them tell the connector exactly where to start, so they could avoid unnecessary reads and relieve unnecessary load on the database. Marcus wrapped up the talk with the payoff: “This results in a highly efficient real-time data capture system that streams the CDC events straight to Kafka. From there, we can do anything—consume the data, store it, or move it to any database. This is a gamechanger. With this optimization, we unlocked a new level of efficiency and scalability, and this made a real difference for us.”
{kind=link}
{kind=link}