11X Faster ScyllaDB Backup
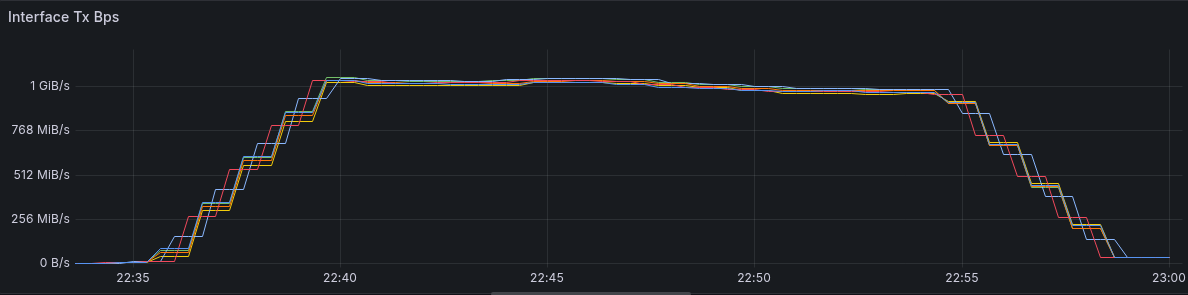
Learn about ScyllaDB’s new native backup, which improves backup speed up to 11X by using Seastar’s CPU and IO scheduling ScyllaDB’s 2025.3 release introduces native backup functionality. Previously, an external process managed backups independently, without visibility into ScyllaDB’s internal workload. Now, Seastar’s CPU and I/O schedulers handle backups internally, which gives ScyllaDB full control over prioritization and resource usage. In this blog post, we explain why we changed our approach to backup, share what users need to know, and provide a preview of what to expect next. What We Changed and Why Previously, SSTable backups to S3 were managed entirely by ScyllaDB Manager and the Scylla Manager Agent running on each node. You would schedule the backup, and Manager would coordinate the required operations (taking snapshots, collecting metadata, and orchestrating uploads). Scylla Manager Agent handled all the actual data movement. The problem with this approach was that it was often too slow for our users’ liking, especially at the massive scale that’s common across our user base. Since uploads ran through an external process, they competed with ScyllaDB for resources (CPU, disk I/O, and network bandwidth). The rclone process read from \disk at the same time that ScyllaDB did – so two processes on the same node were performing heavy disk I/O simultaneously. This contention on the disk could impact query latencies when user requests were being processed during a backup. To mitigate the effect on real-time database requests, we use Systemd slice to control Scylla Manager Agent resources. This solution successfully reduced backup bandwidth, but failed to increase the bandwidth when the pressure from online requests was low. To optimize this process, ScyllaDB now provides a native backup capability. Rather than relying on an external agent (ScyllaDB Manager) to copy files, ScyllaDB uploads files directly to S3. The new approach is faster and more efficient because ScyllaDB uses its internal IO and CPU scheduling to control the backup operations. Backup operations are assigned a lower priority than user queries. In the event of resource contention, ScyllaDB will deprioritize them so they don’t interfere with the latency of the actual workload. Note that this new native backup capability is currently available for AWS. It is coming soon for other backup targets (such as GCP Cloud Storage and Azure Storage). To enable native backup, configure the S3 connectivity on each node’s scylla.yaml and set the desired strategy (Native, Auto, or Rclone) in ScyllaDB Manager. Note that the rclone agent is always used to upload backup metadata, so you should still configure the Manager Agent even if you are using native backup and restore. Performance Improvements So how much faster is the new backup approach? We recently ran some tests to find out. We ran two tests which are the same in all aspects except for the tool being used for backup: rclone in one and native scylla in the other. Test Setup The test uses 6 nodes i4i.2xlarge with total injected data of 2TB with RF=3. That means that the 2TB injected data becomes 6TB (RF=3) and these 6TB are spread across 6 nodes, resulting in each node holding 1TB of data. The backup benchmark then measures how long it takes to backup the entire cluster, indicating the data size of one node Native Backup Here are the results of the native backup tests: Name Size Time [s] native_backup_1016_2234 1.057 TiB 00:19:18 Data was uploaded at a rate of approximately 900 MB/s. OS Tx Bytes during backup The slightly higher values for the OS metrics are due to for example tcp-retransmit, size of HTTP headers that is not part of the data but part of the transmitted bytes, and more alike. rclone Backup The same exact test with rclone produced the following results: Name Size Time [s] rclone_backup_1017_2334 1.057 TiB 03:48:57 Here, data was uploaded at a rate of approximately 80MB/s Next Up: Faster Restore Next, we’re optimizing restore, which is the more complex part of the backup/restore process. Backups are relatively straightforward: you just upload the data to object storage. But restoring that data is harder, especially if you need to bring a cluster back online quickly or restore it onto a topology that’s different from the original one. The original cluster’s nodes, token ranges, and data distribution might look quite different from the new setup – but during restore, ScyllaDB must somehow map between what was backed up and what the new topology expects. Replication adds even more complexity. ScyllaDB replicates data according to the specified replication factor (RF), so the backup has multiple copies of the same data. During the restore process, we don’t want to redundantly download or process those copies; we need a way to handle them efficiently. And one more complicating factor: the restore process must understand whether the cluster uses virtual nodes or tablets because that affects how data is distributed. Wrapping Up ScyllaDB’s move to native integration with object storage is a big step forward for the faster backup/restore operations that many of our large-scale users have been asking for. We’ve already sped up backups by eliminating the extra rclone layer. Now, our focus is on making restores equally efficient while handling complex topologies, replication, and data distribution. This will make it faster and easier to restore large clusters. Looking ahead, we’re working on using object storage not only for backup and restore, but also for tiering: letting ScyllaDB read data directly from object storage as if it were on local disk. For a more detailed look at ScyllaDB’s plans for backup, restore, and object storage as native storage, see this video:
{kind=link}