How GE Healthcare Took DynamoDB on Prem for Its AI Platform
How GE Healthcare moved a DynamoDB-powered AI platform to hospital data centers, without rewriting the app
How do you move a DynamoDB-powered AI platform from AWS to hospital data centers without rewriting the app? That’s the challenge that Sandeep Lakshmipathy (Director of Engineering at GE Healthcare) decided to share with the ScyllaDB community a few years back.
We noticed an uptick in people viewing this video recently, so we thought we’d share it here, in blog form. Watch or read, your choice.
Intro
Hi, I’m Sandeep Lakshmipathy, the Director of Engineering for the Edison-AI group at GE-Healthcare. I have about 20-years of experience in the software industry, working predominantly in product and platform development. For the last seven years I’ve been in the healthcare domain at GE, rolling out solutions for our products.
Let me start by setting some context with respect to the healthcare challenges that we face today. Roughly 130M babies are born every year; about 350K every single day. There’s a 40% shortage of healthcare workers to help bring these babies into the world. Ultrasound scans help ensure the babies are healthy, but those scans are user-dependent, repetitive, and manual. Plus, clinical training is often neglected.
Why am I talking about this? Because AI solutions can really help in this specific use case and make a big difference.
Now, consider this matrix of opportunities that AI presents.
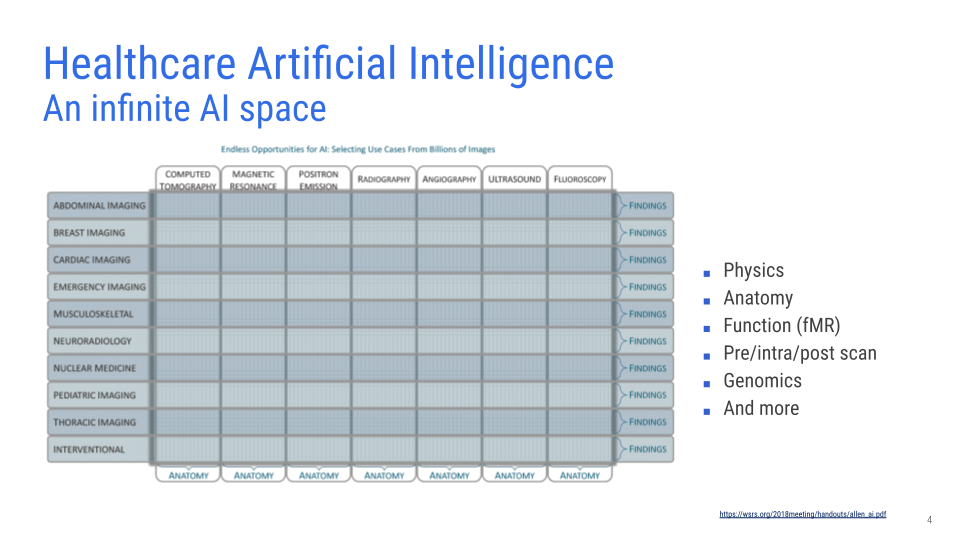
Every single tiny dot within each cell is an opportunity in itself. The newborn-baby challenge I just highlighted is one tiny speck in this giant matrix. It shows what an infinite space this is, and how AI can address each challenge in a unique way.
GE-Healthcare is tackling these opportunities through a platform approach.
Edison-AI Workbench (cloud)
We ingest data from many devices and customers: scanners, research networks, and more. Data is then annotated and used to train models. Once the models are trained, we deploy them onto devices.

The Edison-AI Workbench helps data scientists view and annotate data, train models, and package them for deployment. The whole Edison AI Workbench runs in AWS and uses AWS resources to provide a seamless experience to the data scientists and annotators who are building AI solutions for our customers.
Bringing Edison AI Workbench on-prem
When we showed this solution to our research customers, they said, “Great, we really like the features and the tools….but can we have Edison AI Workbench on-prem?”

So, we started thinking: How do we take something that lives in the AWS cloud, uses all those resources, and relies heavily on AWS services – and move it onto an on-prem server while still giving our research customers the same experience? That’s when we began exploring different options. Since DynamoDB was one of the main things tying us to the AWS cloud, we started looking for a way to replace it in the on-prem world.
After some research, we saw that ScyllaDB was a good DynamoDB replacement because it provides API compatibility with DynamoDB. Without changing much code and keeping all our interfaces the same, we migrated the Workbench to on-prem and quickly delivered what our research customers asked for.
Why ScyllaDB Alternator (DynmamoDB-Compatible API)?
Moving cloud assets on-prem is not trivial; expertise, time-to-market, service parity, and scalability all matter. We also wanted to keep our release cycles short: in the cloud we can push features every sprint; on-prem, we still need regular updates. Keeping the database layer similar across cloud and on-prem minimized rework. Quick proofs of concept confirmed that ScyllaDB-+-Alternator met our needs, and using Kubernetes on-prem let us port microservices comfortably.
The ScyllaDB team has always been available with respect to developer-level interactions, quick fixes in nightly builds, and constant touch-points with technical and marketing teams. All of this helped us move fast. For example, DynamoDB Streams wasn’t yet in ScyllaDB when we adopted it (back in 2020), but the team provided work-arounds until the feature became available. They also worked with us on licensing to match our needs. This partnership was crucial to the solution’s evolution.
By partnering with the ScyllaDB team, we could take a cloud-native Workbench to our on-prem research customers in healthcare.

Final thoughts
Any AI solution rollout depends on having the right data volume and balance. It’s all the annotations that drive model quality. Otherwise, the model will be brittle, and it won’t have the necessary diversity.

Supporting all these on-prem Workbench use cases helps because it takes the tools to where the data is. The cloud workbench handles data in the cloud data lake. But at the same time, our research customers who are partnering with us can use this on-prem, taking the tools to where the data is: in their hospital network.