Cache vs. Database: How Architecture Impacts Performance
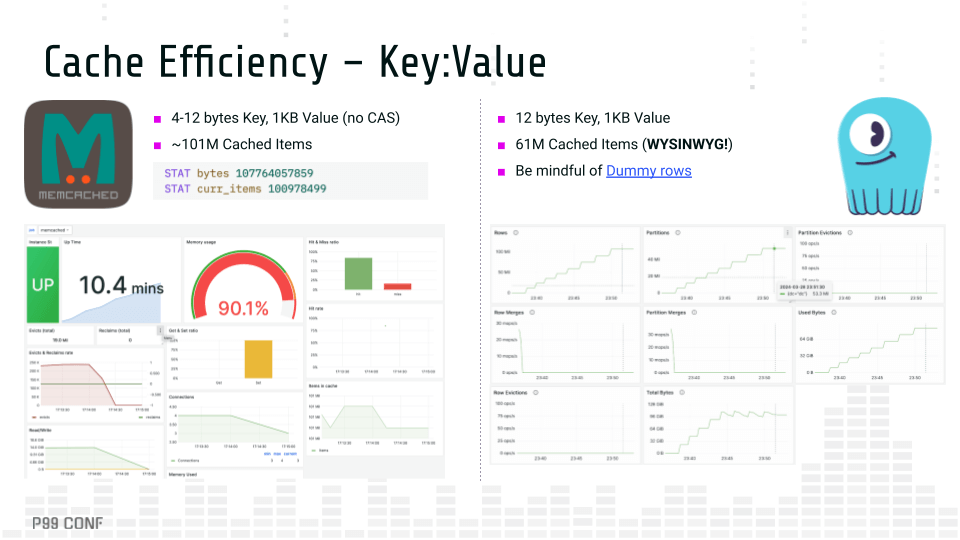
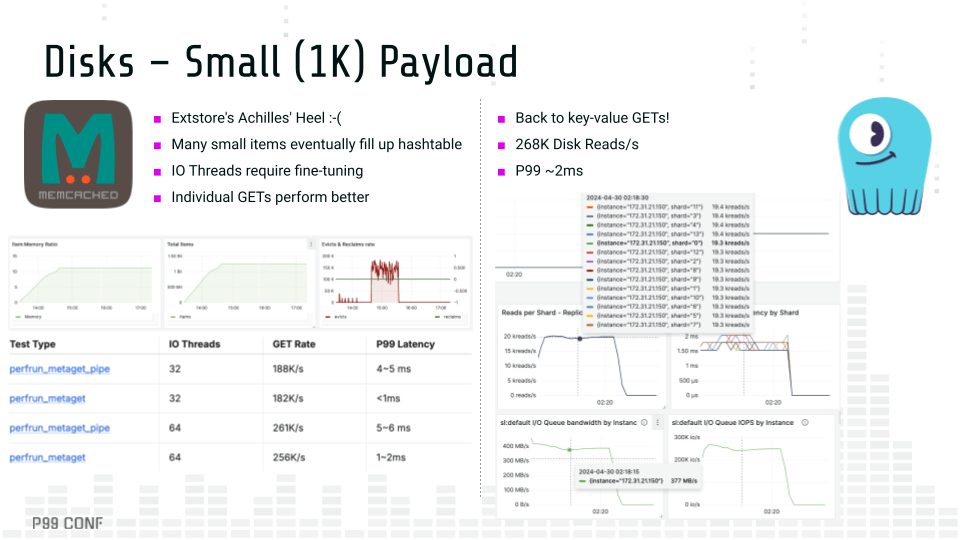
Lessons learned comparing Memcached with ScyllaDB Although caches and databases are different animals, databases have always cached data and caches started to use disks, extending beyond RAM. If an in-memory cache can rely on flash storage, can a persistent database also function as a cache? And how far can you reasonably push each beyond its original intent, given the power and constraints of its underlying architecture? A little while ago, I joined forces with Memcached maintainer Alan Kasindorf (a.k.a. dormando) to explore these questions. The collaboration began with the goal of an “apples to oranges” benchmark comparing ScyllaDB with Memcached, which is covered in the article “We Compared ScyllaDB and Memcached and… We Lost?” A few months later, we were pleasantly surprised that the stars aligned for P99 CONF. At the last minute, Kasindorf was able to join us to chat about the project – specifically, what it all means for developers with performance-sensitive use cases. Note: P99 CONF is a highly technical conference on performance and low-latency engineering. We just wrapped P99 CONF 2025, and you can watch the core sessions on-demand. Watch on demand Cache Efficiency Which data store uses memory more efficiently? To test it, we ran a simple key-value workload on both systems. The results: Memcached cached 101 million items before evictions began ScyllaDB cached only 61 million items before evictions Cache efficiency comparison What’s behind the difference? ScyllaDB also has its own LRU (Least Recently Used) cache, bypassing the Linux cache. But unlike Memcached, ScyllaDB supports a wide-column data representation: A single key may contain many rows. This, along with additional protocol overhead, causes a single write in ScyllaDB to consume more space than a write in Memcached. Drilling down into the differences, Memcached has very little per-item overhead. In the example from the image above, each stored item consumes either 48 or 56 bytes, depending on whether compare and swap (CAS) is enabled. In contrast, ScyllaDB has to handle a lot more (it’s a persistent database after all!). It needs to allocate space for its memtables, Bloom filters and SSTable summaries so it can efficiently retrieve data from disk when a cache miss occurs. On top of that, ScyllaDB supports a much richer data model(wide column). Another notable architectural difference stands out in the performance front: Memcached is optimized for pipelined requests (think batching, as in DynamoDB’s BatchGetItem), considerably reducing the number of roundtrips over the network to retrieve several keys. ScyllaDB is optimized for single (and contiguous) key retrievals under a wide-column representation. Read-only in-memory efficiency comparison Following each system’s ideal data model, both ScyllaDB and Memcached managed to saturate the available network throughput, servicing around 3 million rows/s while sustaining below single-digit millisecond P99 latencies. Disks and IO Efficiency Next, the focus shifted to disks. We measured performance under different payload sizes, as well as how efficiently each of the systems could maximize the underlying storage. With Extstore and small (1K) payloads, Memcached stored about 11 times more items (compared to its in-memory workload) before evictions started to kick in, leaving a significant portion of free available disk space. This happens because, in addition to the regular per-key overhead, Memcached stores an additional 12 bytes per item in RAM as a pointer to storage. As RAM gets depleted, Extstore is no longer effective and users will no longer observe savings beyond that point. Disk performance with small payloads comparison For the actual performance tests, we stressed Extstore against item sizes of 1KB and 8KB. The table below summarizes the results: Test Type Payload Size I/O Threads GET Rate P99 Latency perfrun_metaget_pipe 1KB 32 188K/s 4~5 ms perfrun_metaget 1KB 32 182K/s <1ms perfrun_metaget_pipe 1KB 64 261K/s 5~6 ms perfrun_metaget 1KB 64 256K/s 1~2ms perfrun_metaget_pipe 8KB 16 92K/s 5~6 ms perfrun_metaget 8KB 16 90K/s <1ms perfrun_metaget_pipe 8KB 32 110K/s 3~4 ms perfrun_metaget 8KB 32 105K/s <1ms We populated ScyllaDB with the same number of items as we used for Memcached. ScyllaDB actually achieved higher throughput – and just slightly higher latency – than Extstore. I’m pretty sure that if the throughput had been reduced, the latency would have been lower. But even with no tuning, the performance is quite comparable. This is summarized below: Test Type Payload Size GET Rate Server-Side P99 Client-Side P99 1KB Read 1KB 268.8K/s 2ms 2.4ms 8KB Read 8KB 156.8K/s 1.54ms 1.9ms A few notable points from these tests: Extstore required considerable tuning to fully saturate flash storage I/O. Due to Memcached’s architecture, smaller payloads are unable to fully use the available disk space, providing smaller gains compared to ScyllaDB. ScyllaDB rates were overall higher than Memcached in a key-value orientation, especially under higher payload sizes. Latencies were better than pipelined requests, but slightly higher than individual GETs in Memcached. I/O Access Methods Discussion These disk-focused tests unsurprisingly sparked a discussion about the different I/O access methods used by ScyllaDB vs. Memcached/Extstore. I explained that ScyllaDB uses asynchronous direct I/O. For an extensive discussion of this, read this blog post by ScyllaDB CTO and cofounder Avi Kivity. Here’s the short version: ScyllaDB is a persistent database. When people adopt a database, they rightfully expect that it will persist their data. So, direct I/O is a deliberate choice. It bypasses the kernel page cache, giving ScyllaDB full control over disk operations. This is critical for things like compactions, write-ahead logs and efficiently reading data off disk. A user-space I/O scheduler is also involved. It lives in the middle and decides which operation gets how much I/O bandwidth. That could be an internal compaction task or a user-facing query. It arbitrates between them. That’s what enables ScyllaDB to balance persistence work with latency-sensitive operations. Extstore takes a rather very different approach: keep things as simple as possible and avoid touching the disk unless it’s absolutely necessary. As Kasindorf put it: “We do almost nothing.” That’s fully intentional. Most operations — like deletes, TTL updates, or overwrites — can happen entirely in memory. No disk access needed. So Extstore doesn’t bother with a scheduler.” Without a scheduler, Extstore performance tuning is manual. You can change the number of Extstore I/O threads to get better utilization. If you roll it out and notice that your disk doesn’t look fully utilized – and you still have a lot of spare CPU – you can bump up the thread count. Kasindorf mentioned that it will likely become self-tuning at some point. But for now, it’s a knob that users can tweak. Another important piece is how Extstore layers itself on top of Memcached’s existing RAM cache. It’s not a replacement; it’s additive. You still have your in-memory cache and Extstore just handles the overflow. Here’s how Kasindorf explained it: “If you have, say, five gigs of RAM and one gig of that is dedicated to these small pointers that point from memory into disk, we still have a couple extra gigs left over for RAM cache.” That means if a user is actively clicking around, their data may never even go to disk. The only time Extstore might need to read from disk is when the cache has gone cold (for instance, a user returning the next day). Then the entries get pulled back in. Basically, while ScyllaDB builds around persistent, high-performance disk I/O (with scheduling, direct control and durable storage), Extstore is almost the opposite. It’s light, minimal and tries to avoid disk entirely unless it really has to. Conclusion and Takeaways Across these and the other tests that we performed in the full benchmark, Memcached and ScyllaDB both managed to maximize the underlying hardware utilization and keep latencies predictably low. So which one should you pick? The real answer: It depends. If your existing workload can accommodate a simple key-value model and it benefits from pipelining, then Memcached should be more suitable to your needs. On the other hand, if the workload requires support for complex data models, then ScyllaDB is likely a better fit. Another reason for sticking with Memcached: It easily delivers traffic far beyond what a network interface card can sustain. In fact, in this Hacker News thread, dormando mentioned that he could scale it up past 55 million read ops/sec for a considerably larger server. Given that, you could make use of smaller and/or cheaper instance types to sustain a similar workload, provided the available memory and disk footprint meet your workload needs. A different angle to consider is the data set size. Even though Extstore provides great cost savings by allowing you to store items beyond RAM, there’s a limit to how many keys can fit per gigabyte of memory. Workloads with very small items should observe smaller gains compared to those with larger items. That’s not the case with ScyllaDB, which allows you to store billions of items irrespective of their sizes. It’s also important to consider whether data persistence is required. If it is, then running ScyllaDB as a replicated distributed cache provides you greater resilience and non-stop operations, with the tradeoff being (and as Memcached correctly states) that replication halves your effective cache size. Unfortunately, Extstore doesn’t support warm restarts and thus the failure or maintenance of a single node is prone to elevating your cache miss ratios. Whether this is acceptable depends on your application semantics: If a cache miss corresponds to a round-trip to the database, then the end-to-end latency will be momentarily higher. Regardless of whether you choose a cache like Memcached or a database like ScyllaDB, I hope this work inspires you to think differently about performance testing. As we’ve seen, databases and caches are fundamentally different. And at the end of the day, just comparing performance numbers isn’t enough. Moreover, recognize that it’s hard to fully represent your system’s reality with simple benchmarks, and every optimization comes with some trade-offs. For example, pipelining is great, but as we saw with Extstore, it can easily introduce I/O contention. ScyllaDB’s shard-per-core model and support for complex data models are also powerful, but they come with costs too, like losing some pipelining flexibility and adding memory overhead.
{kind=link}
{kind=link}
{kind=link}