Managing ScyllaDB Background Operations with Task Manager
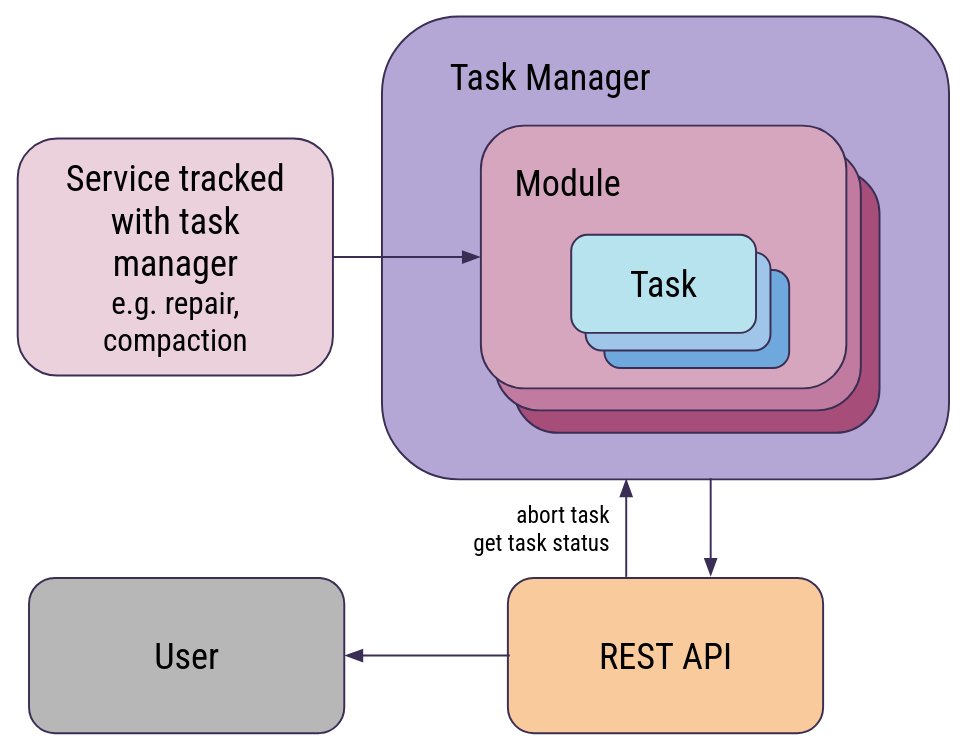
Learn about Task Manager, which provides a unified way to observe and control ScyllaDB’s background maintenance work In each ScyllaDB cluster, there are a lot of background processes that help maintain data consistency, durability, and performance in a distributed environment. For instance, such operations include compaction (which cleans up on-disk data files) and repair (which ensures data consistency in a cluster). These operations are critical for preserving cluster health and integrity. However, some processes can be long-running and resource-intensive. Given that ScyllaDB is used for latency-sensitive database workloads, it’s important to monitor and track these operations. That’s where ScyllaDB’s Task Manager comes in. Task Manager allows administrators of self-managed ScyllaDB to see all running operations, manage them, or get detailed information about a specific operation. And beyond being a monitoring tool, Task Manager also provides a unified way to manage asynchronous operations. How Task Manager Organizes and Tracks Operations Task Manager adds structure and visibility into ScyllaDB’s background work. It groups related maintenance activities into modules, represents them as hierarchical task trees, and tracks their lifecycle from creation through completion. The following sections explain how operations are organized, retained, and monitored at both node and cluster levels. Supported Operations Task Manager supports the following operations: Local: Compaction; Repair; Streaming; Backup; Restore. Global: Tablet repair; Tablet migration; Tablet split and merge; Node operations: bootstrap, replace, rebuild, remove node, decommission. Reviewing Active/Completed Tasks Task Manager is divided into modules: the entities that gather information about operations of similar functionality. Task Manager captures and exposes this data using tasks. Each task covers an operation or its part (e.g., a task can represent the part of the repair operation running on a specific shard). Each operation is represented by a tree of tasks. The tree root covers the whole operation. The root may have children, which give more fine-grained control over the operation. The children may have their own children, etc. Let’s consider the example of a global major compaction task tree: The root covers the compaction of all keyspaces in a node; The children of the root task cover a single keyspace; The second-degree descendants of the root task cover a single keyspace on a single shard; The third-degree descendants of the root task cover a single table on a single shard; etc. You can inspect a task from each depth to see details on the operation’s progress. Determining How Long Tasks Are Shown Task Manager can show completed tasks as well as running ones. The completed tasks are removed from Task Manager after some time. To customize how long a task’s status is preserved, modify task_ttl_in_seconds (aka task_ttl) and user_task_ttl_in_seconds (aka user_task_ttl) configuration parameters. Task_ttl applies to operations that are started internally, while user_task_ttl refers to those initiated by the user. When the user starts an operation, the root of the task tree is a user-task. Descendant tasks are internal and such tasks are unregistered after they finish, propagating their status to their parents. Node Tasks vs Cluster Tasks Task Manager tracks operations local to a node as well as global cluster-wide operations. A local task is created on a node that the respective operation runs on. Its status may be requested only from a node on which the task was created. A global task always covers the whole operation. It is the root of a task tree and it may have local children. A global task is reachable from each node in a cluster. Task_ttl and user_task_ttl are not relevant for global tasks. Per-Task Details When you list all tasks in a Task Manager module, it shows brief information about them with task_stats. Each task has a unique task_id and sequence_number that’s unique within its module. All tasks in a task tree share the same sequence_number. Task stats also include several descriptive attributes: kind: either “node” (a local operation) or “cluster” (a global one). type: what specific operation this task involves (e.g., “major compaction” or “intranode migration”). scope: the level of granularity (e.g., “keyspace” or “tablet”). Additional attributes such as shard, keyspace, table, and entity can further specify the scope. Status fields summarize the task’s state and timing: state: indicate if the task was created, running, done, failed, or suspended. start_time and end_time: indicate when the task began and finished. If a task is still running, its end_time is set to epoch. When you request a specific task’s status, you’ll see more detailed metrics: progress_total and progress_completed show how much work is done, measured in progress_units. parent_id and children_ids place the task within its tree hierarchy. is_abortable indicates whether the task can be stopped before completion. If the task failed, you will also see the exact error message. Interacting with Task Manager Task Manager provides a REST API for listing, monitoring, and controlling ScyllaDB’s background operations. You can also use it to manage the execution of long-running maintenance tasks started with the asynchronous API instead of blocking a client call. If you prefer command-line tools, the same functionality is available through nodetool tasks. Using the Task Management API Task Manager exposes a REST API that lets you manage tasks: GET /task_manager/list_modules – lists all supported Task Manager modules. GET /task_manager/list_module_tasks/{module} – lists all tasks in a specified module. GET /task_manager/task_status/{task_id} – shows the detailed status of a specified task. GET /task_manager/wait_task/{task_id} – waits for a specified task and shows its status. POST /task_manager/abort_task/{task_id} – aborts a specified task. GET /task_manager/task_status_recursive/{task_id} – gets statuses of a specified task and all its descendants. GET/POST /task_manager/ttl – gets/sets task_ttl. GET/POST /task_manager/user_ttl – gets/sets user_task_ttl. POST /task_manager/drain/{module} – drains the finished tasks in a specified module. Running Maintenance Tasks Asynchronously Some ScyllaDB maintenance operations can take a while to complete, especially at scale. Waiting for them to finish through a synchronous API call isn’t always practical. Thanks to Task Manager, existing synchronous APIs are easily and consistently converted into asynchronous ones. Instead of waiting for an operation to finish, a new API can immediately return the ID of the root task representing the started operation. Using this task_id, you can check the operation’s progress, wait for completion, or abort it if needed. This gives you a unified and consistent way to manage all those long-running tasks. Nodetool A task can be managed using nodetool’s tasks command. For details, see the related nodetool docs page
{kind=link}
. Example: Tracking and Managing Tasks Preparation To start, we locally set up a cluster of three nodes with the IP addresses 127.43.0.1, 127.43.0.2, and 127.43.0.3. Next, we create two keyspaces: keyspace1 with replication factor 3 and keyspace2 with replication factor 2. In each keyspace, we create 2 tables: table1 and table2 in keyspace1, and table3 and table4 in keyspace2. We populate them with data. Exploring Task Manager Let’s start by listing the modules supported by Task Manager: nodetool tasks modules -h 127.43.0.1 Starting and Tracking a Repair Task We request a tablet repair on all tokens of table keyspace2.table3. curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' 'http://127.43.0.3:10000/storage_service/tablets/repair?ks=keyspace2&table=table3&tokens=all' {"tablet_task_id":"2f06bff0-ab45-11f0-94c2-60ca5d6b2927"} In response, we get the task id of the respective tablet repair task. We can use it to track the progress of the repair. Let’s check whether the task with id 2f06bff0-ab45-11f0-94c2-60ca5d6b2927 will be listed in a tablets module. nodetool tasks list tablets -h 127.43.0.1 Apart from the repair task, we can see that there are two intranode migrations running. All the tasks are of type “cluster”, which means that they cover the global operations. All these tasks would be visible regardless of which node we request them from. We can also see the scope of the operations. We always migrate one tablet at a time, so the migration tasks’ scope is “tablet”. For repair, the scope is “table” because we previously started the operation on a whole table. Entity, sequence_number, and shard are irrelevant for global tasks. Since all tasks are running, their end_time is set to a default value (epoch). Examining Task Status Let’s examine the status of the tablet repair using its task_id. Global tasks are available on the whole cluster, so we change the requested node… just because we can. 😉 nodetool tasks status 2f06bff0-ab45-11f0-94c2-60ca5d6b2927 -h 127.43.0.3 The task status contains detailed information about the tablet repair task. We can see whether the task is abortable (via task_manager API). There could also be some additional information that’s not applicable for this particular task : error, which would be set if the task failed; parent_id, which would be set if it had a parent (impossible for a global task); progress_unit, progress_total, progress_comwepleted, which would indicate task progress (not yet supported for tablet repair tasks). There’s also a list of tasks that were created as a part of the global task. The list above has been shortened to improve readability. The key point is that children of a global task may be created on all nodes in a cluster. Those children are local tasks (because global tasks cannot have a parent). Thus, they are reachable only from the nodes where they were created. For example, the status of a task 1eb69569-c19d-481e-a5e6-0c433a5745ae should be requested from node 127.43.0.2. nodetool tasks status 1eb69569-c19d-481e-a5e6-0c433a5745ae -h 127.43.0.2 As expected, the child’s kind is “node”. Its parent_id references the tablet repair task’s task_id. The task has completed successfully, as indicated by the state. The end_time of a task is set. Its sequence_number is 15, which means it is the 15th task in its module. The task’s scope is wider than the parent’s. It could encompass the whole keyspace, but – in this case – it is limited to the parent’s scope. The task’s progress is measured in ranges, and we can see that exactly one range was repaired. This task has one child that is created on the same node as its parent. That’s always true for local tasks. nodetool tasks status 70d098c4-df79-4ea2-8a5e-6d7386d8d941 -h 127.43.0.3 We may examine other children of the global tablet repair task too. However, we may only check each one on the node where it was created. Let’s wait until the global task is completed. nodetool tasks wait 2f06bff0-ab45-11f0-94c2-60ca5d6b2927 -h 127.43.0.2 We can see that its state is “done” and its end_time is set. Working with Compaction Tasks Let’s start some compactions and have a look at the compaction module. nodetool tasks list compaction -h 127.43.0.2 We can see that one of the major compaction tasks is still running. Let’s abort it and check its task tree. nodetool tasks abort 16a6cdcc-bb32-41d0-8f06-1541907a3b48 -h 127.43.0.2 nodetool tasks tree 16a6cdcc-bb32-41d0-8f06-1541907a3b48 -h 127.43.0.2 We can see that the abort request propagated to one of the task’s children and aborted it. That task now has a failed state and its error field contains abort_requested_exception. Managing Asynchronous Operations Beyond examining the running operations, Task Manager can manage asynchronous operations started with the REST API. For example, we may start a major compaction of a keyspace synchronously with /storage_service/keyspace_compaction/{keyspace} or use an asynchronous version of this API: curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' 'http://127.43.0.1:10000/tasks/compaction/keyspace_compaction/keyspace2' "4c6f3dd4-56dc-4242-ad6a-8be032593a02" The response includes the task_id of the operation we just started. This id may be used in Task Manager to track the progress, wait for the operation, or abort it. Key Takeaways The Task Manager provides a clear, unified way to observe and control background maintenance work in ScyllaDB.
Visibility: It shows detailed, hierarchical information about ongoing and completed operations, from cluster-level tasks down to individual shards. Consistency: You can use the same mechanisms for listing, tracking, and managing all asynchronous operations. Control: You can check progress, wait for completion, or abort tasks directly, without guessing what’s running. Extensibility: It also provides a framework for turning synchronous APIs into asynchronous ones by returning task IDs that can be monitored or managed through the Task Manager. Together, these capabilities make it easier to see what ScyllaDB is doing, keep the system stable, and convert long-running operations to asynchronous workflows.