NoSQL Data Modeling: Application Design Before Schema Design

We’re thrilled to share the following excerpt from Bo Ingram’s informative – and fun! – new book on ScyllaDB: ScyllaDB in Action. It’s available now via Manning and Amazon. You can also access a 3-chapter excerpt for free, compliments of ScyllaDB.
Get the first 3 book chapters, free
You might have already experienced Bo’s expertise and engaging communication style in his blog How Discord Stores Trillions of Messages or ScyllaDB Summit talks How Discord Migrated Trillions of Messages from Cassandra to ScyllaDB and So You’ve Lost Quorum: Lessons From Accidental Downtime If not, you should 😉 And if you want to learn more from Bo, access the on-demand masterclass on Data Modeling for Performance Masterclass.
The following is an excerpt from Chapter 3; it’s reprinted here with permission of the publisher.
***
When designing a database schema, you need to create a schema that is synergistic with your database. If you consider Scylla’s goals as a database, it wants to distribute data across the cluster to provide better scalability and fault tolerance. Spreading the data means queries involve multiple nodes, so you want to design your application to make queries that use the partition key, minimizing the nodes involved in a request. Your schema needs to fit these constraints:
- It needs to distribute data across the cluster
- It should also query the minimal amount of nodes for your desired consistency level
There’s some tension in these constraints — your schema wants to spread data across the cluster to balance load between the nodes, but you want to minimize the number of nodes required to serve a query. Satisfying these constraints can be a balancing act — do you have smaller partitions that might require more queries to aggregate together, or do you have larger partitions that require fewer queries, but spread it potentially unevenly across the cluster? In figure 3.1, you can see the cost of a query that utilizes the partition key and queries across the minimal amount of nodes versus one that doesn’t use the partition key, necessitating scanning each node for matching data. Using the partition key in your query allows the coordinator — the node servicing the request — to direct queries to nodes that own that partition, lessening the load on the cluster and returning results faster.
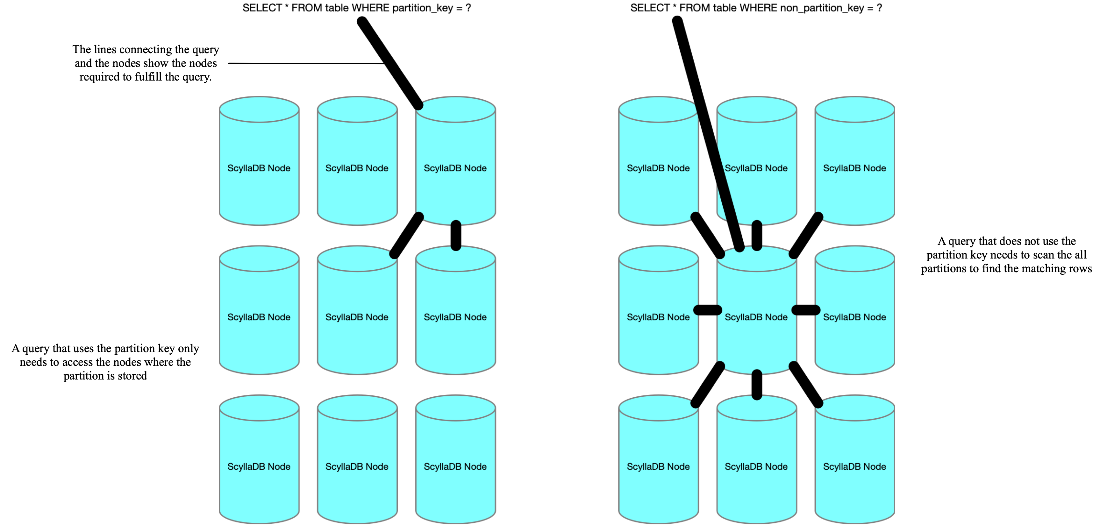
Figure 3.1 Using the partition key minimizes the number of nodes required to serve the request.
The aforementioned design constraints are each related to queries. You want your data to be spread across the cluster so that your queries distribute the load amongst multiple nodes. Imagine if all of your data was clustered on a small subset of nodes in your cluster. Some nodes would be working quite hard, whereas others might not be taking much traffic. If some of those heavily utilized nodes became overwhelmed, you could suffer quite degraded performance, as because of the imbalance, many queries could be unable to complete.
However, you also want to minimize the number of nodes hit per query to minimize the work your query needs to do; a query that uses all nodes in a very large cluster would be very inefficient. These query-centric constraints necessitate a query-centric approach to design. How you query Scylla is a key component of its performance, and since you need to consider the impacts of your queries across multiple dimensions, it’s critical to think carefully about how you query Scylla.
When designing schemas in Scylla, it’s best to practice an approach called query-first-design, where you focus on the queries your application needs to make and then build your database schema around that. In Scylla, you structure your data based on how you want to query it — query-first design helps you.
Your query-first design toolbox
In query-first design, you take a set of application requirements and ask yourself a series of questions that guide you through translating the requirements into a schema in ScyllaDB. Each of these questions builds upon the next, iteratively guiding you through building an effective ScyllaDB schema. These questions include the following:
- What are the requirements for my application?
- What are the queries my application needs to run to meet these requirements?
- What tables are these queries querying?
- How can these tables be uniquely identified and partitioned to satisfy the queries?
- What data goes inside these tables?
- Does this design match the requirements?
- Can this schema be improved?
This process is visualized in (figure 3.2), showing how you start with your application requirements and ask yourself a series of questions, guiding you from your requirements to the queries you need to run to ultimately, a fully designed ScyllaDB schema ready to store data effectively.
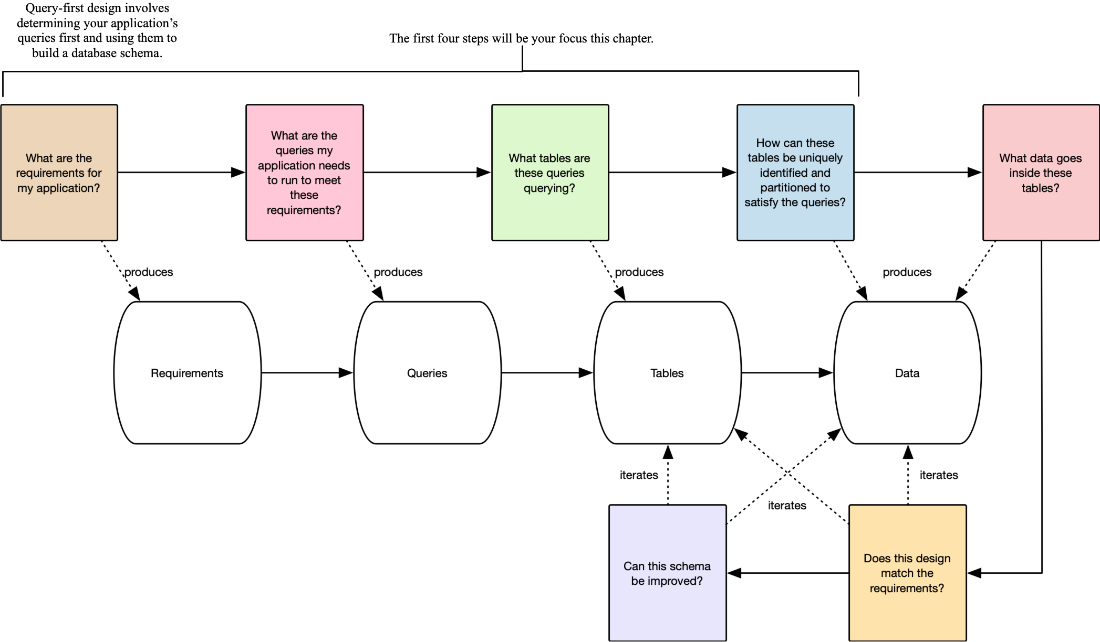
Figure 3.2 Query-first design guides you through taking application requirements and converting them to a ScyllaDB schema.
You begin with requirements and then use the requirements to identify the queries you need to run. These queries are seeking something — those “somethings” need to be stored in tables. Your tables need to be partitioned to spread data across the cluster, so you determine that partitioning to stay within your requirements and database design constraints. You then specify the fields inside each table, filling it out. At this point, you can check two things:
- Does the design match the requirements?
- Can it be improved?
This up-front design is important because in ScyllaDB changing your schema to match new use cases can be a high-friction operation. While Scylla supports new query patterns via some of its features (which you’ll learn about in chapter 7), these come at an additional performance cost, and if they don’t fit your needs, might necessitate a full manual copy of data into a new table. It’s important to think carefully about your design: not only what it needs to be, but also what it could be in the future.
You start by extracting the queries from your requirements and expanding your design until you have a schema that fits both your application and ScyllaDB. To practice query-first design in Scylla, let’s take the restaurant review application introduced at the beginning of the chapter and turn it into a ScyllaDB schema.
The sample application requirements
In the last chapter, you took your restaurant reviews and stored them inside ScyllaDB. You enjoyed working with the database, and as you went to more places, you realized you could combine your two great loves — restaurant reviews and databases (if these aren’t your two great loves, play along with me). You decide to build a website to share your restaurant reviews. Because you already have a ScyllaDB cluster, you choose to use that (this is a very different book if you pick otherwise) as the storage for your website.
The first step to query-first design is identifying the requirements for your application, as seen in figure 3.4.
Figure 3.4 You begin query-first design by determining your application’s requirements.
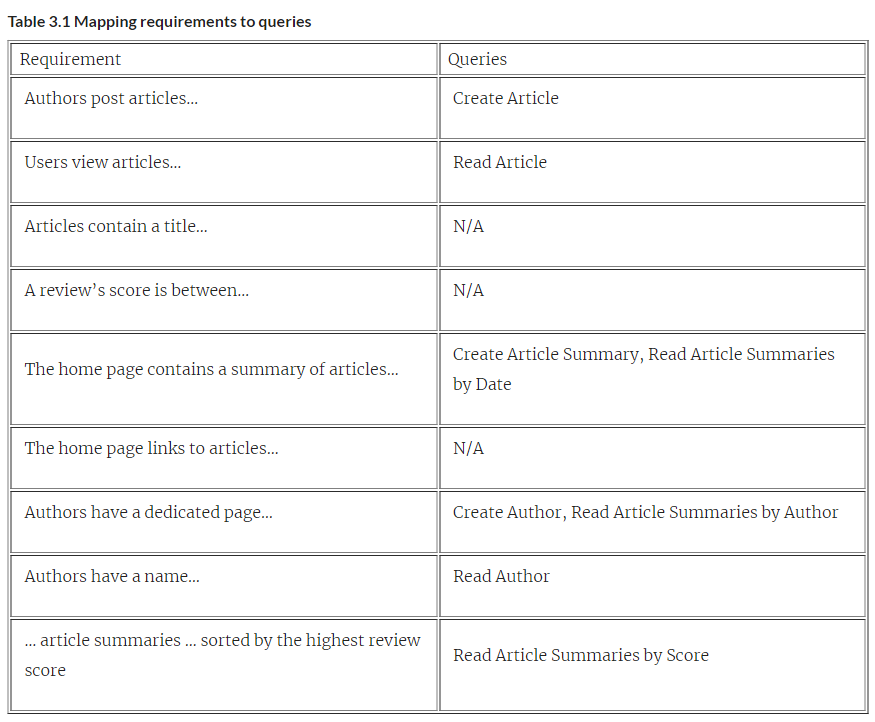
After ruminating on your potential website, you identify the features it needs, and most importantly, you give it a name — Restaurant Reviews. It does what it says! Restaurant Reviews has the following initial requirements:
- Authors post articles to the website
- Users view articles to read restaurant reviews
- Articles contain a title, an author, a score, a date, a gallery of images, the review text, and the restaurant
- A review’s score is between 1 and 10
- The home page contains a summary of articles sorted by most recent, showing the title, author name, score, and one image
- The home page links to articles
- Authors have a dedicated page containing summaries of their articles
- Authors have a name, bio, and picture
- Users can view a list of article summaries sorted by the highest review score
You have a hunch that as time goes by, you’ll want to add more features to this application and use those features to learn more about ScyllaDB. For now, these features give you a base to practice decomposing requirements and building your schema — let’s begin!
Determining the queries
Next, you ask what are the queries my application needs to run to meet these requirements?, as seen in figure 3.5 Your queries drive how you design your database schema; therefore, it is critical to understand your queries at the beginning of your design.
Figure 3.5 Next, you take your requirements and use them to determine your application’s queries.
For identifying queries, you can use the familiar CRUD operations — create, read, update, and delete — as verbs. These queries will act on nouns in your requirements, such as authors or articles. Occasionally, you’ll want to filter your queries — you can notate this filtering with by followed by the filter condition. For example, if your app needed to load events on a given date, you might use a Read Events by Date query. If you take a look at your requirements, you’ll see several queries you’ll need.
TIP: These aren’t the actual queries you’ll run; those are written in CQL, as seen in chapter 2, and look more like SELECT * FROM your_cool_table WHERE your_awesome_primary_key = 12;. These are descriptions of what you’ll need to query — in a later chapter when you finish your design, you’ll turn these into actual CQL queries.
The first requirement is “Authors post articles to the website,” which sounds an awful lot like a process that would involve inserting an article into a database. Because you insert articles in the database via a query, you will need a Create Article statement. You might be asking at this point — what is an article? Although other requirements discuss these fields, you should skip that concern for the moment. Focus first on what queries you need to run, and then you’ll later figure out the needed fields.
The second requirement is “Users view articles to read restaurant reviews.” Giving users unfettered access to the database is a security no-go, so the app needs to load an article to display to a user. This functionality suggests a Read Article query (which is different than the user perusing the article), which you can use to retrieve an article for a user.
The following two requirements refer to the data you need to store and not a novel way to access them:
- Articles contain a title, an author, a score, a date, a gallery of images, the review text, and the restaurant
A review’s score is between 1 and 10 - Articles need certain fields, and each article is associated with a review score that fits within specified parameters. You can save these requirements for later when you fill out what fields are needed in each table.
The next relevant requirement says “The home page contains a summary of articles sorted by most recent, showing the title, author name, score, and one image.” The home page shows article summaries, which you’ll need to load by their date, sorted by most recent– Read Article Summaries by Date. Article summaries, at first glance, look a lot like articles. Because you’re querying different data, and you also need to retrieve summaries by their time, you should consider them as different queries.
Querying for an article:
- loads a title, author, score, date, a gallery of images, the review text, and the restaurant
- retrieves one specific article
On the other hand, loading the most recent article summaries:
- loads only the title, author name, score, and one image
- loads several summaries, sorted by their publishing date
Perhaps they can run against the same table, but you can see if that’s the case further on in the exercise. When in doubt, it’s best to not over-consolidate. Be expansive in your designs, and if there’s duplication, you can reduce it when refining your designs. As you work through implementing your design, you might discover reasons for what seems to be unnecessarily duplicated in one step to be a necessary separation later.
Following these requirements is “the home page links to articles”, which makes explicit that the article summaries link to the article — you’ll look closer at this one when you determine what fields you need.
The next two requirements are about authors. The website will contain a page for each author — presumably only you at the moment, but you have visions of a media empire. This author page will contain article summaries for each author — meaning you’ll need to Read Article Summaries by Author. In the last requirement, there’s data that each author has. You can study the specifics of these in a moment, but it means that you’ll need to read information about the author, so you will need a Read Author query.
For the last requirement — ”Users can view a list of article summaries sorted by the highest review score” — you’ll need a way to surface article summaries sorted by their scores. This approach requires a Read Article Summaries by Score.
TIP: What would make a good partition key for reading articles sorted by score? It’s a tricky problem; you’ll learn how to attack it shortly.
Having analyzed the requirements, you’ve determined six queries your schema needs to support:
- Create Article
- Read Article
- Read Article Summaries by Date
- Read Article Summaries by Author
- Read Article Summaries by Score
- Read Author
You might notice a problem here — where do article summaries and authors get created? How can you read them if nothing makes them exist? Requirement lists often have implicit requirements — because you need to read article summaries, they have to be created somehow. Go ahead and add a Create Article Summary and Create Author query to your list. You now have eight queries from the requirements you created, listed in table 3.1.
There’s a joke that asks “How do you draw an owl?” — you draw a couple of circles, and then you draw the rest of the owl. Query-first design sometimes feels similar. You need to map your queries to a database schema that is not only effective in meeting the application’s requirements but is performant and uses ScyllaDB’s benefits and features. Drawing queries out of requirements is often straightforward, whereas designing the schema from those queries requires balancing both application and database concerns. Let’s take a look at some techniques you can apply as you design a database schema...