Making Effective Partitions for ScyllaDB Data Modeling

Learn how to ensure your tables are perfectly partitioned to satisfy your queries – in this excerpt from the book “ScyllaDB in Action.”
Editor’s note
We’re thrilled to share the following excerpt from Bo Ingram’s informative – and fun! – new book on ScyllaDB: ScyllaDB in Action. It’s available now via Manning and Amazon. You can also access a 3-chapter excerpt for free, compliments of ScyllaDB.
Get the first 3 book chapters, free
You might have already experienced Bo’s expertise and engaging communication style in his blog How Discord Stores Trillions of Messages or ScyllaDB Summit talks How Discord Migrated Trillions of Messages from Cassandra to ScyllaDB and So You’ve Lost Quorum: Lessons From Accidental Downtime If not, you should 😉 And if you want to learn more from Bo, access the on-demand masterclass on Data Modeling for Performance Masterclass.
The following is an excerpt from Chapter 3; it’s reprinted here with permission of the publisher.
***
When analyzing the queries your application needs, you identified several tables for your schema.

The next step in schema design is to ask how can these tables be uniquely identified and partitioned to satisfy the queries?. The primary key contains the row’s partition key — you learned in chapter 2 that the primary key determines a row’s uniqueness. Therefore, before you can determine the partition key, you need to know the primary key.
PRIMARY KEYS
First, you should check to see if what you’re trying to store contains a property that is popularly used for its uniqueness. Cars, for example, have a vehicle identification number, that’s unique per car. Books (including this one!) have an ISBN (international standard book number) to uniquely identify them. There’s no international standard for identifying an article or an author, so you’ll need to think a little harder to find the primary and partition keys. ScyllaDB does provide support for generating unique identifiers, but they come with some drawbacks that you’ll learn about in the next chapter.
Next, you can ask if any fields can be combined to make a good primary key. What could you use to determine a unique article? The title might be reused, especially if you have unimaginative writers. The content would ideally be unique per article, but that’s a very large value for a key. Perhaps you could use a combination of fields — maybe date, author, and title? That probably works, but I find it’s helpful to look back at what you’re trying to query. When your application runs the Read Article query, it’s trying to read only a single article. Whatever is executing that query, probably a web server responding to the contents of a URL, is trying to load that article, so it needs information that can be stored in a URL. Isn’t it obnoxious when you go to paste a link somewhere and the link feels like it’s a billion characters long? To load an article, you don’t want to have to keep track of the author ID, title, and date. That’s why using an ID as a primary key is often a strong choice.
Providing a unique identifier satisfies the uniqueness requirement of a primary key, and they can potentially encode other information inside them, such as time, which can be used for relative ordering. You’ll learn more about potential types of IDs in the next chapter when you explore data types.
What uniquely identifies an author? You might think an email, but people sometimes change their email addresses. Supplying your own unique identifier works well again here. Perhaps it’s a numeric ID, or maybe it’s a username, but authors, as your design stands today, need extra information to differentiate them from other authors within your database.
Article summaries, like the other steps you’ve been through, are a little more interesting. For the various article summary tables, if you try to use the same primary key as articles, an ID, you’re going to run into trouble. If an ID alone makes an article unique in the articles table, then presumably it suffices for the index tables. That turns out to not be the case.
An ID can still differentiate uniqueness, but you also want to query by at least the partition key to have a performant query, and if an ID is the partition key, that doesn’t satisfy the use cases for querying by author, date, or score. Because the partition key is contained within the primary key, you’ll need to include those fields in your primary key (figure 3.12). Taking article_summaries_by_author, your primary key for that field would become author and your article ID. Similarly, the other two tables would have the date and the article ID for article_summaries_by_date, and article_summaries_by_score would use the score and the article ID for its primary key.
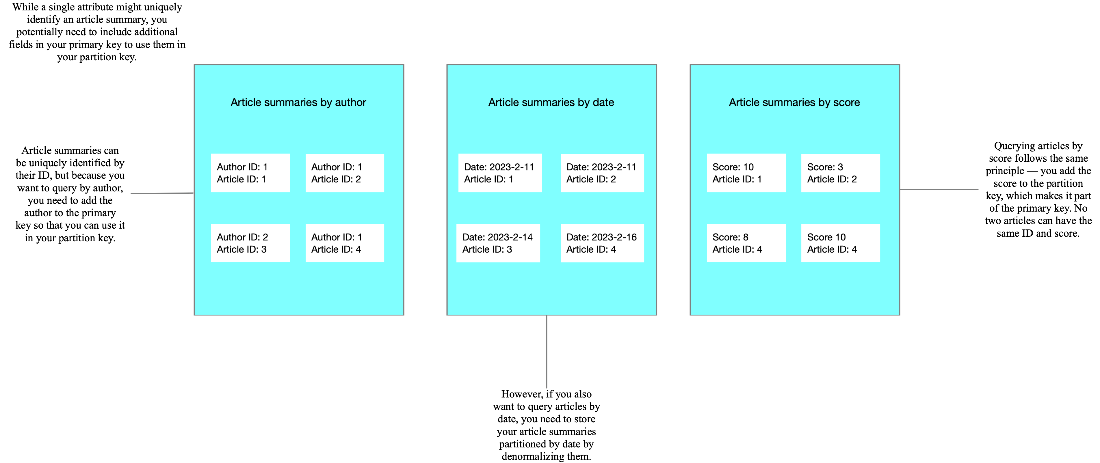
Figure 3.12 You sometimes need to add fields to an already-unique primary key to use them in a partition key, especially when denormalizing data.
With your primary keys figured out, you can move forward to determining your partition keys and potentially adjusting your primary keys.
PARTITION KEYS
You learned in the last chapter that the first entry in the primary key serves as the partition key for the row (you’ll see later how to build a composite primary key). A good partition key distributes data evenly across the cluster and is used by the queries against that table. It stores a relatively small amount of data (a good rule of thumb is that 100 MB is a large partition, but it depends on the use case). I’ve listed the tables and their primary key; knowing the primary keys, you can now rearrange them to specify your partition keys. What would be a good partition key for each of these tables?
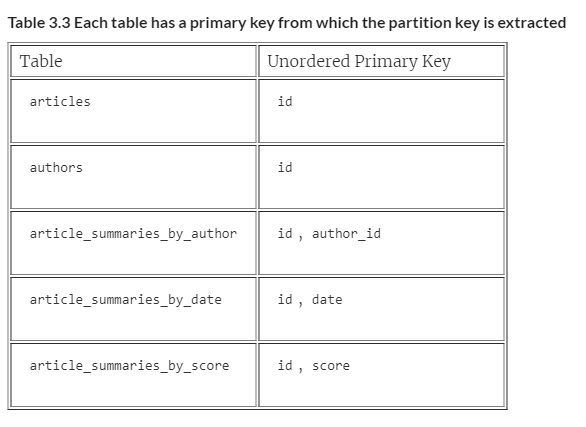
Table 3.3 Each table has a primary key from which the partition key is extracted
For the articles and authors tables, it’s very straightforward. There is one column in the primary key; therefore, the partition key is the only column. If only everything was that easy!
TIP: By only having the ID as the primary key and the partition key, you can look up rows only by their ID. A query where you want to get multiple rows wouldn’t work with this approach, because you’d be querying across partitions, bringing in extra nodes and hampering performance. Instead, you want to query by a partition key that would contain multiple rows, as you’ll do with article summaries.
The article summaries tables, however, present you with a choice. Given a primary key of an ID and an author, for article_summaries_by_author, which should be the partition key? If you choose ID, Scylla will distribute the rows for this table around the cluster based on the ID of the article. This distribution would mean that if you wanted to load all articles by their author, the query would have to hit nodes all across the cluster. That behavior is not efficient. If you partitioned your data by the author, a query to find all articles written by a given author would hit only the nodes that store that partition, because you’re querying within that partition (figure 3.13). You almost always want to query by at least the partition key — it is critical for good performance. Because the use case for this table is to find articles by who wrote them, the author is the choice for the partition key. This distribution makes your primary key author_id, id because the partition key is the first entry in the primary key.
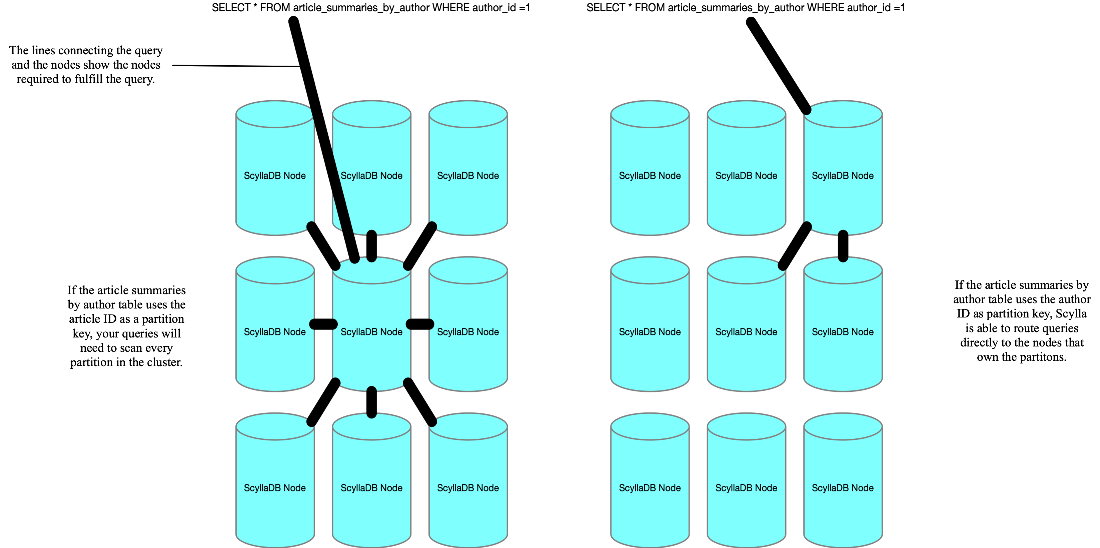
Figure 3.13 The partition key for each table should match the queries you previously determined to achieve the best performance.
article_summaries_by_date and article_summaries_by_score, in what might be the least surprising statement of the book, present a similar choice as article_summaries_by_author with a similar solution. Because you’re querying article_summaries_by_date by the date of the article, you want the data partitioned by it as well, making the primary key date, id, or score, id for article_summaries_by_score.
Tip: Right-sizing partition keys:
If a partition key is too large, data will be unevenly distributed across the cluster. If a partition key is too small, range scans that load multiple rows might need several queries to load the desired amount of data. Consider querying for articles by date — if you publish one article a week but your partition key is per day, then querying for the most recent articles will require queries with no results six times out of seven.
Partitioning your data is a balancing exercise. Sometimes, it’s easy. Author is a natural partition key for articles by author, whereas something like date might require some finessing to get the best performance in your application. Another problem to consider is one partition taking an outsized amount of traffic — more than the node can handle. In the next chapters, as you refine your design, you’ll learn how to adjust your partition key to fit your database just right.
After looking closely at the tables, your primary keys are now ordered correctly to partition the data.
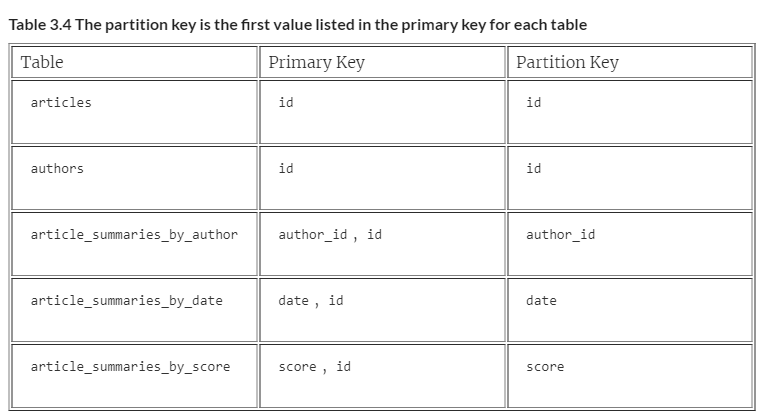
For the article summaries tables, your primary keys are divided into two categories — partition key and not-partition key. The leftover bit has an official name and performs a specific function in your table. Let’s take a look at the not-partition keys — clustering keys.
CLUSTERING KEYS
A clustering key is the non-partition key part of a table’s primary key that defines the ordering of the rows within the table. In the previous chapter, when you looked at your example table, you noticed that Scylla had filled in the table’s implicit configuration, ordering the non-partition key columns — the clustering keys — by ascending order.
CREATE TABLE initial.food_reviews ( restaurant text, ordered_at timestamp, food text, review text, PRIMARY KEY (restaurant, ordered_at, food) ) WITH CLUSTERING ORDER BY (ordered_at ASC, food ASC);
Within the partition, each row is sorted by its time ordered and then by the name of the food, each in an ascending sort (so earlier order times and alphabetically by food). Left to its own devices, ScyllaDB always defaults to the ascending natural order of the clustering keys.
When creating tables, if you have clustering keys, you need to be intentional about specifying their order to make sure that you’re getting results that match your requirements. Consider article_summaries_by_author. The purpose of that table is to retrieve the articles for a given author, but do you want to see their oldest articles first or their newest ones? By default, Scylla is going to sort the table by id ASC, giving you the old articles first. When creating your summary tables, you’ll want to specify their sort orders so that you get the newest articles first — specifying id DESC.
You now have tables defined, and with those tables, the primary keys and partition keys are set to specify uniqueness, distribute the data, and provide an ordering based on your queries. Your queries, however, are looking for more than just primary keys — authors have named, and articles have titles and content. Not only do you need to store these fields, you need to specify the structure of that data. To accomplish this definition, you’ll use data types. In the next chapter, you’ll learn all about them and continue practicing query-first design.