How ShareChat Scaled their ML Feature Store 1000X without Scaling the Database
How ShareChat successfully scaled 1000X without scaling the underlying database (ScyllaDB)
The demand for low-latency machine learning feature stores is higher than ever, but actually implementing one at scale remains a challenge. That became clear when ShareChat engineers Ivan Burmistrov and Andrei Manakov took the P99 CONF 23 stage to share how they built a low-latency ML feature store based on ScyllaDB.
This isn’t a tidy case study where adopting a new product saves the day. It’s a “lessons learned” story, a look at the value of relentless performance optimization – with some important engineering takeaways.
The original system implementation fell far short of the company’s scalability requirements. The ultimate goal was to support 1 billion features per second, but the system failed under a load of just 1 million. With some smart problem solving, the team pulled it off though. Let’s look at how their engineers managed to pivot from the initial failure to meet their lofty performance goal without scaling the underlying database.
ShareChat: India’s Leading Social Media Platform
To understand the scope of the challenge, it’s important to know a little about ShareChat, the leading social media platform in India. On the ShareChat app, users discover and consume content in more than 15 different languages, including videos, images, songs and more. ShareChat also hosts a TikTok-like short video platform (Moj) that encourages users to be creative with trending tags and contests.
Between the two applications, they serve a rapidly growing user base that already has over 325 million monthly active users. And their AI-based content recommendation engine is essential for driving user retention and engagement.
Machine learning feature stores at ShareChat
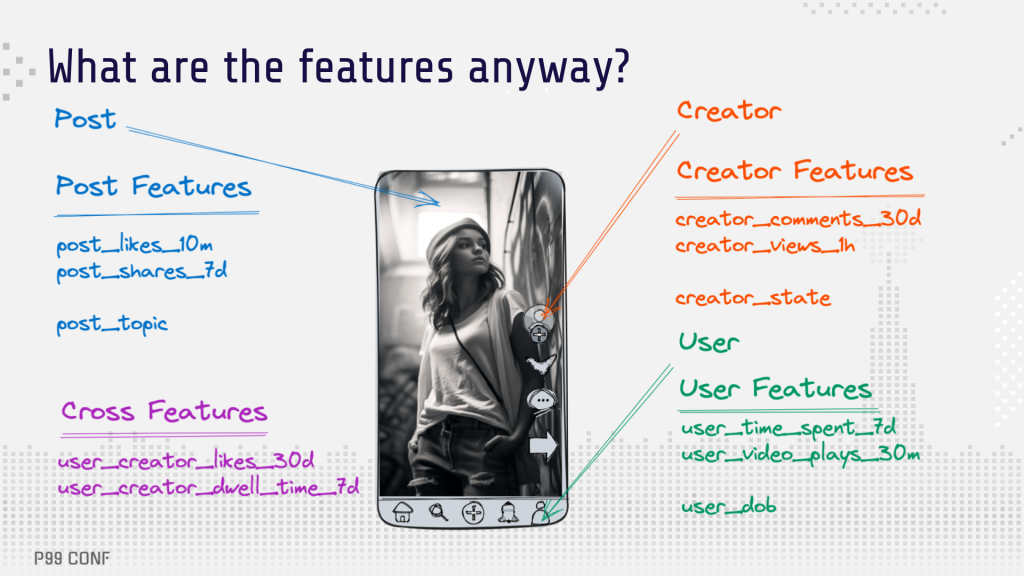
This story focuses on the system behind ML feature stores for the short-form video app Moj. It offers fully personalized feeds to around 20 million daily active users, 100 million monthly active users. Feeds serve 8,000 requests per second, and there’s an average of 2,000 content candidates being ranked on each request (for example, to find the 10 best items to recommend). “Features” are pretty much anything that can be extracted from the data:
Ivan Burmistrov, principal staff software engineer at ShareChat, explained:
“We compute features for different ‘entities.’ Post is one entity, User is another and so on. From the computation perspective, they’re quite similar. However, the important difference is in the number of features we need to fetch for each type of entity. When a user requests a feed, we fetch user features for that single user. However, to rank all the posts, we need to fetch features for each candidate (post) being ranked, so the total load on the system generated by post features is much larger than the one generated by user features. This difference plays an important role in our story.”
What went wrong
At first, the primary focus was on building a real-time user feature store because, at that point, user features were most important. The team started to build the feature store with that goal in mind. But then priorities changed and post features became the focus too. This shift happened because the team started building an entirely new ranking system with two major differences versus its predecessor:
- Near real-time post features were more important
- The number of posts to rank increased from hundreds to thousands
Ivan explained: “When we went to test this new system, it failed miserably. At around 1 million features per second, the system became unresponsive, latencies went through the roof and so on.”
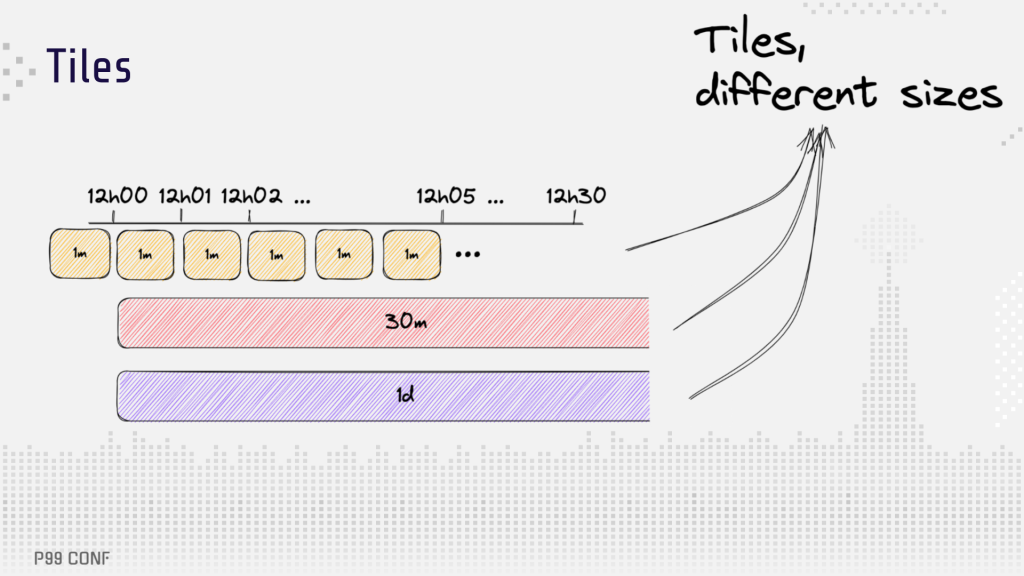
Ultimately, the problem stemmed from how the system architecture used pre-aggregated data buckets called tiles. For example, they can aggregate the number of likes for a post in a given minute or other time range. This allows them to compute metrics like the number of likes for multiple posts in the last two hours.
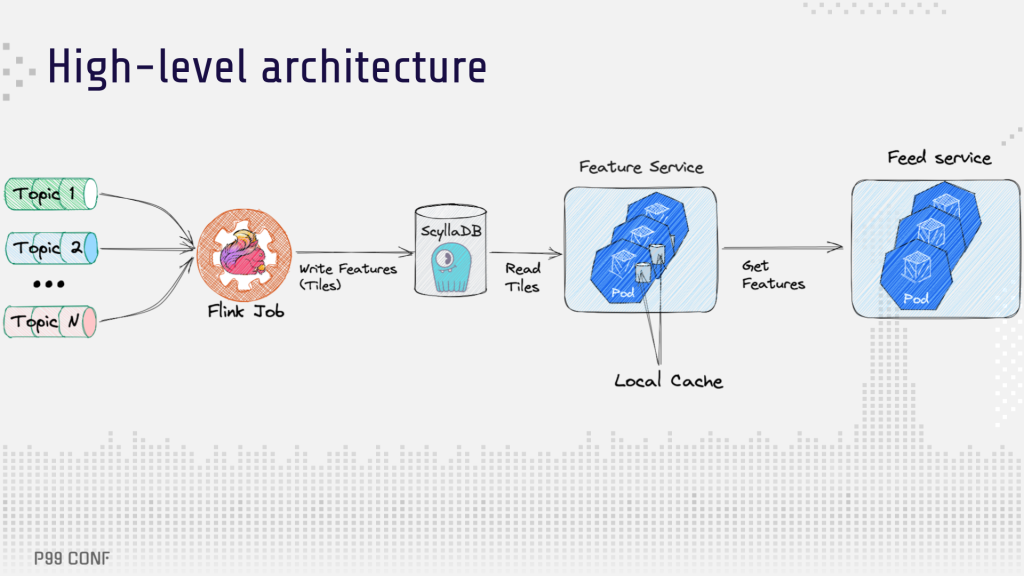
Here’s a high-level look at the system architecture. There are a few real-time topics with raw data (likes, clicks, etc.). A Flink job aggregates them into tiles and writes them to ScyllaDB. Then there’s a feature service that requests tiles from ScyllaDB, aggregates them and returns results to the feed service.
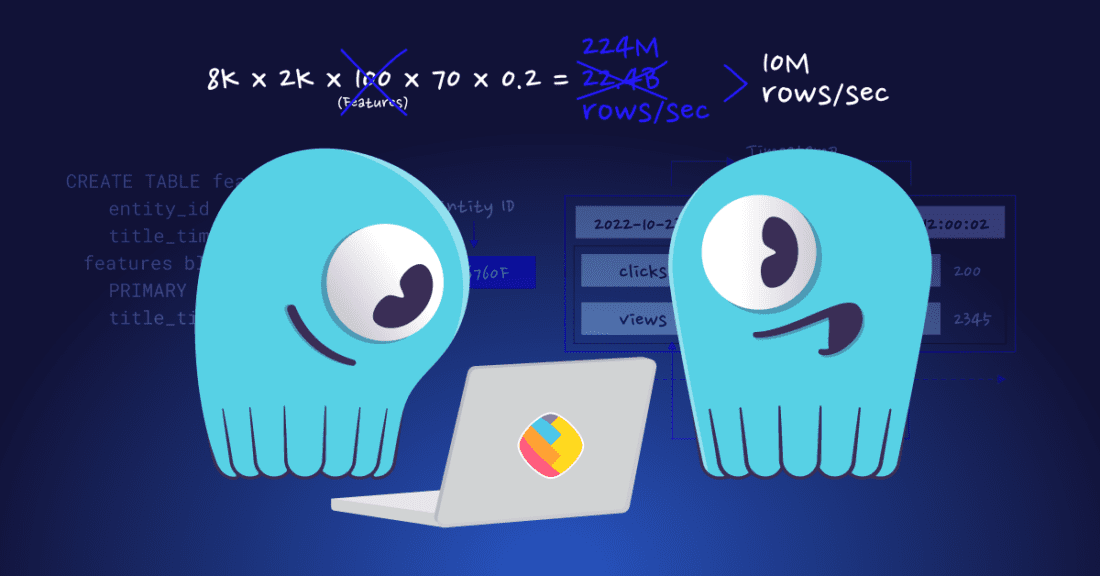
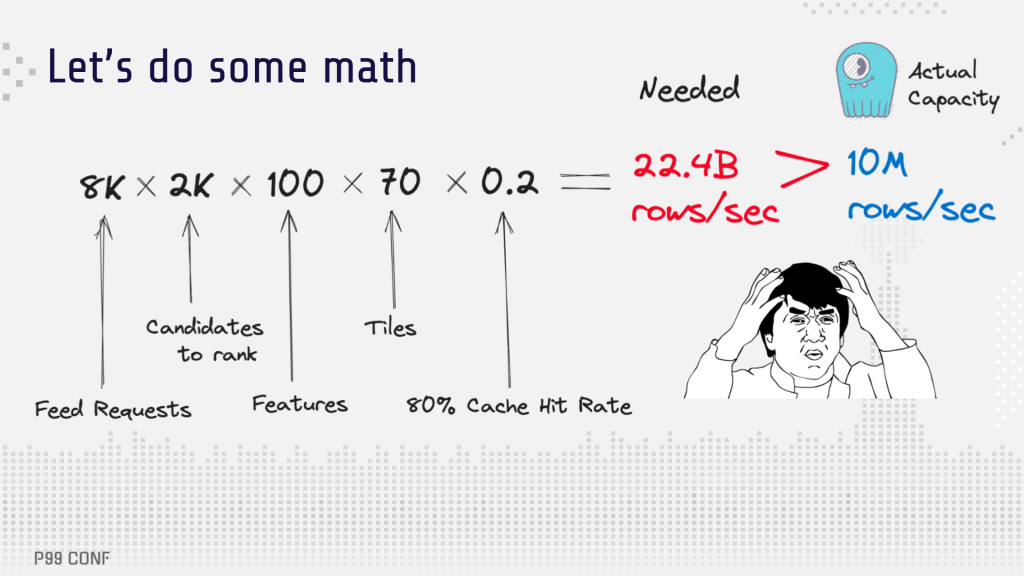
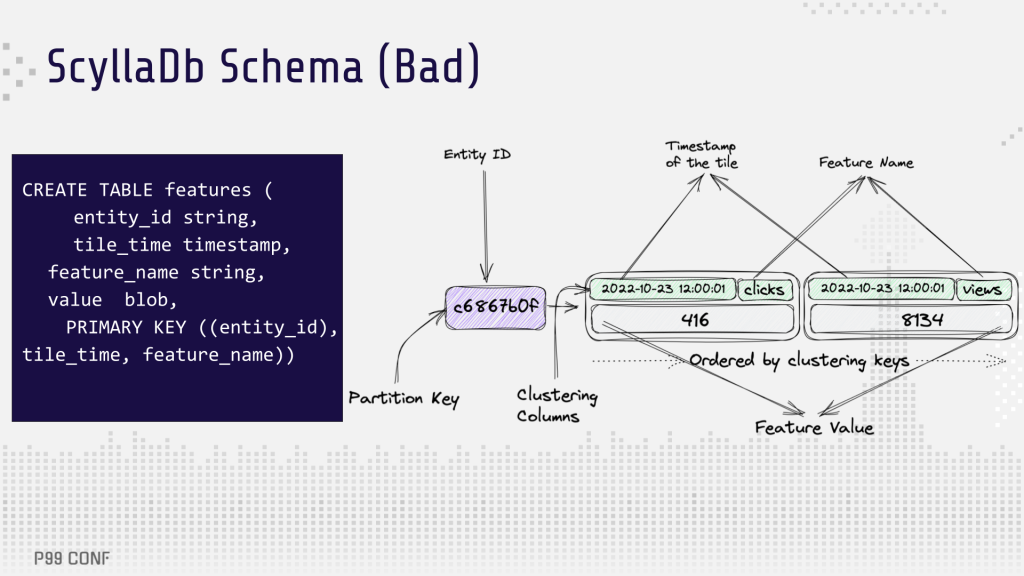
The initial database schema and tiling configuration led to scalability problems. Originally, each entity had its own partition, with rows timestamp and feature name being ordered clustering columns. [Learn more in this NoSQL data modeling masterclass]. Tiles were computed for segments of one minute, 30 minutes and one day. Querying one hour, one day, seven days or 30 days required fetching around 70 tiles per feature on average.
If you do the math, it becomes clear why it failed. The system needed to handle around 22 billion rows per second. However, the database capacity was only 10 million rows/sec.
Initial optimizations
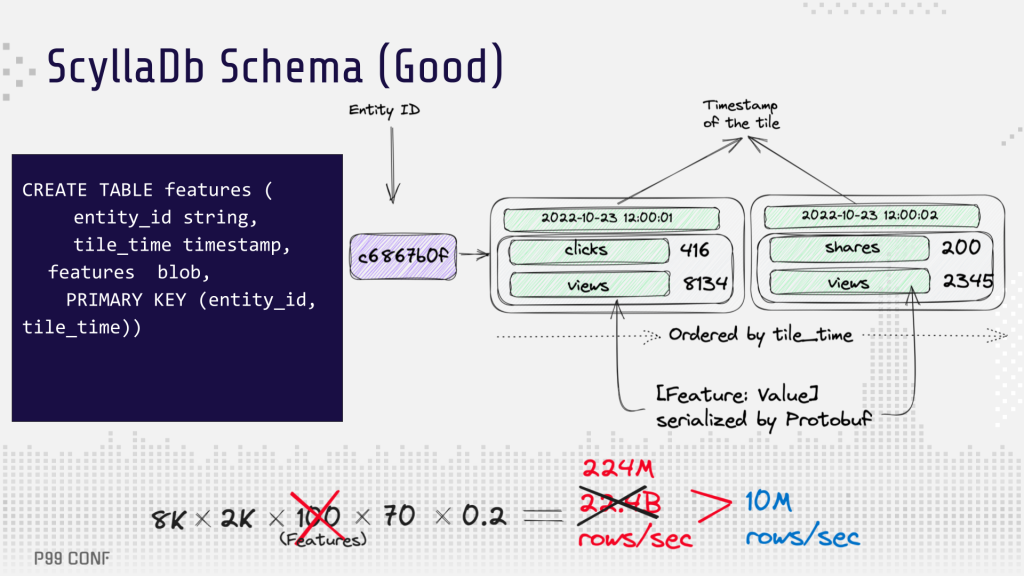
At that point, the team went on an optimization mission. The initial database schema was updated to store all feature rows together, serialized as protocol buffers for a given timestamp. Because the architecture was already using Apache Flink, the transition to the new tiling schema was fairly easy, thanks to Flink’s advanced capabilities in building data pipelines. With this optimization, the “Features” multiplier has been removed from the equation above, and the number of required rows to fetch has been reduced by 100X: from around 2 billion to 200 million rows/sec.
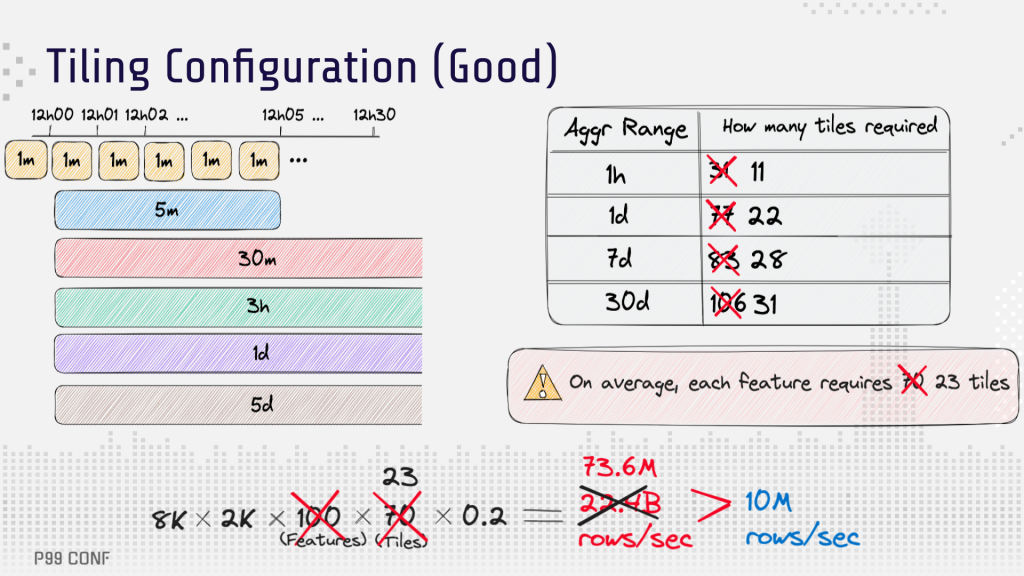
The team also optimized the tiling configuration, adding additional tiles for five minutes, three hours and five days to one minute, 30 minutes and one day tiles. This reduced the average required tiles from 70 to 23, further reducing the rows/sec to around 73 million.

To handle more rows/sec on the database side, they changed the ScyllaDB compaction strategy from incremental to leveled. [Learn more about compaction strategies]. That option better suited their query patterns, keeping relevant rows together and reducing read I/O. The result: ScyllaDB’s capacity was effectively doubled.
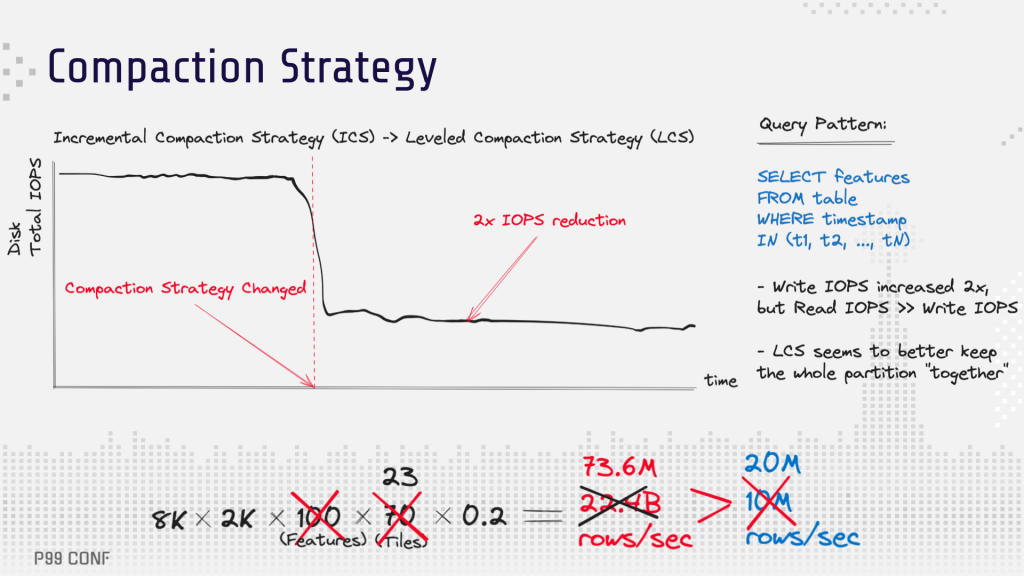
The easiest way to accommodate the remaining load would have been to scale ScyllaDB 4x. However, more/larger clusters would increase costs and that simply wasn’t in their budget. So the team continued focusing on improving the scalability without scaling up the ScyllaDB cluster.
Improved cache locality
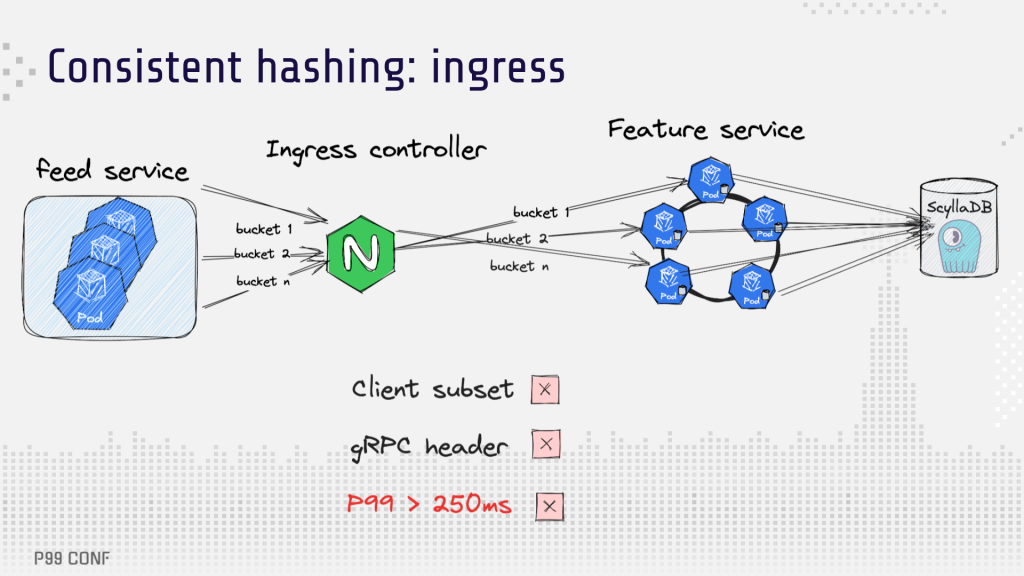
One potential way to reduce the load on ScyllaDB was to improve the local cache hit rate, so the team decided to research how this could be achieved. The obvious choice was to use a consistent hashing approach, a well-known technique to direct a request to a certain replica from the client based on some information about the request. Since the team was using NGINX Ingress in their Kubernetes setup, using NGINX’s capabilities for consistent hashing seemed like a natural choice. Per NGINX Ingress documentation, setting up consistent hashing would be as simple as adding three lines of code. What could go wrong?
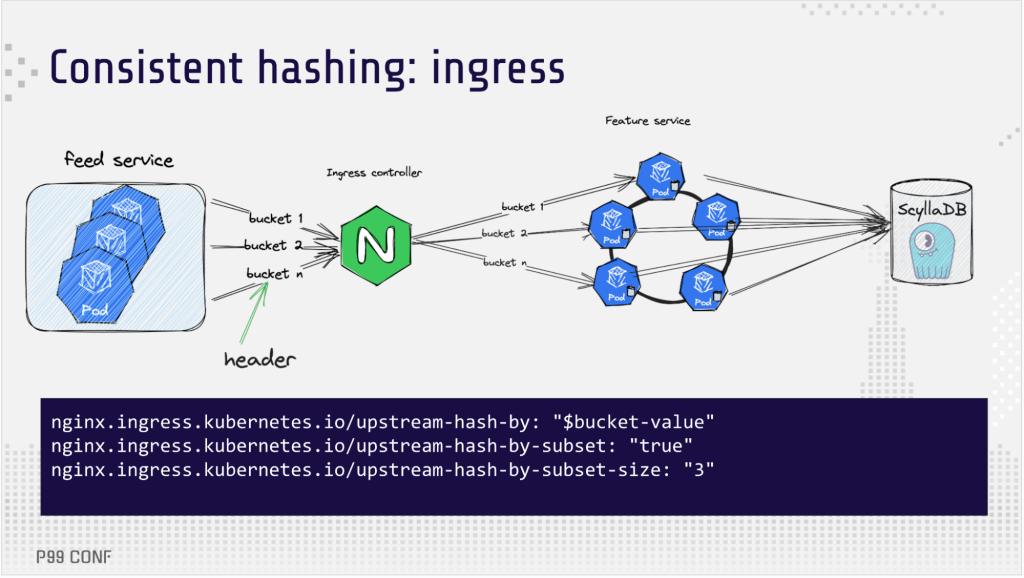
A bit. This simple configuration didn’t work. Specifically:
- The client subset led to a huge key remapping – up 100% in the worst case. Since the node keys can be changed in a hash ring, it was impossible to use real-life scenarios with autoscaling. [See the ingress implementation]
- It was tricky to provide a hash value for a request because Ingress doesn’t support the most obvious solution: a gRPC header.
- The latency suffered severe degradation, and it was unclear what was causing the tail latency.
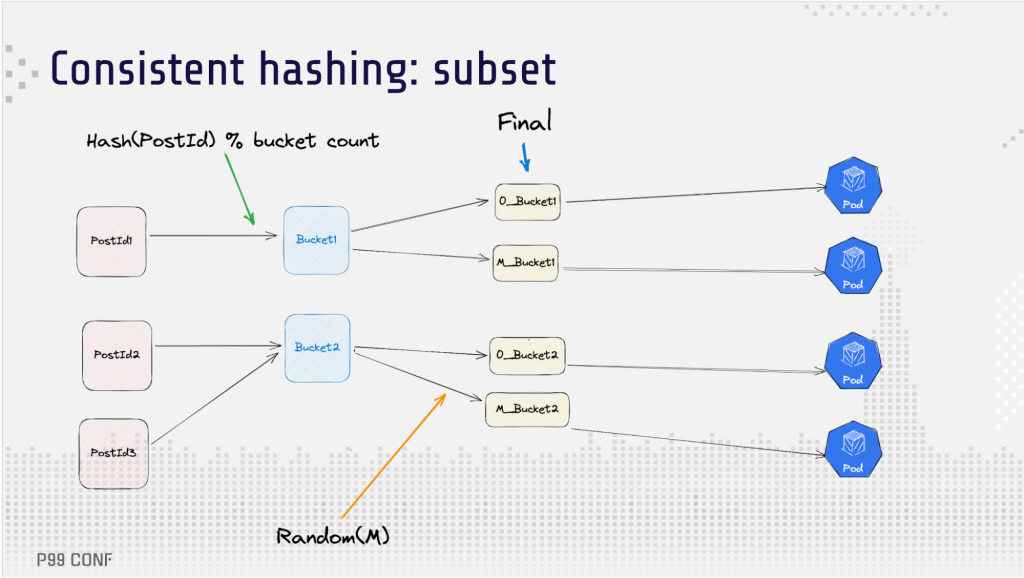
To support a subset of the pods, the team modified their approach. They created a two-step hash function: first hashing an entity, then adding a random prefix. That distributed the entity across the desired number of pods. In theory, this approach could cause a collision when an entity is mapped to the same pod several times. However, the risk is low given the large number of replicas.

Ingress doesn’t support using gRPC header as a variable, but the team found a workaround: using path rewriting and providing the required hash key in the path itself. The solution was admittedly a bit “hacky” … but it worked.
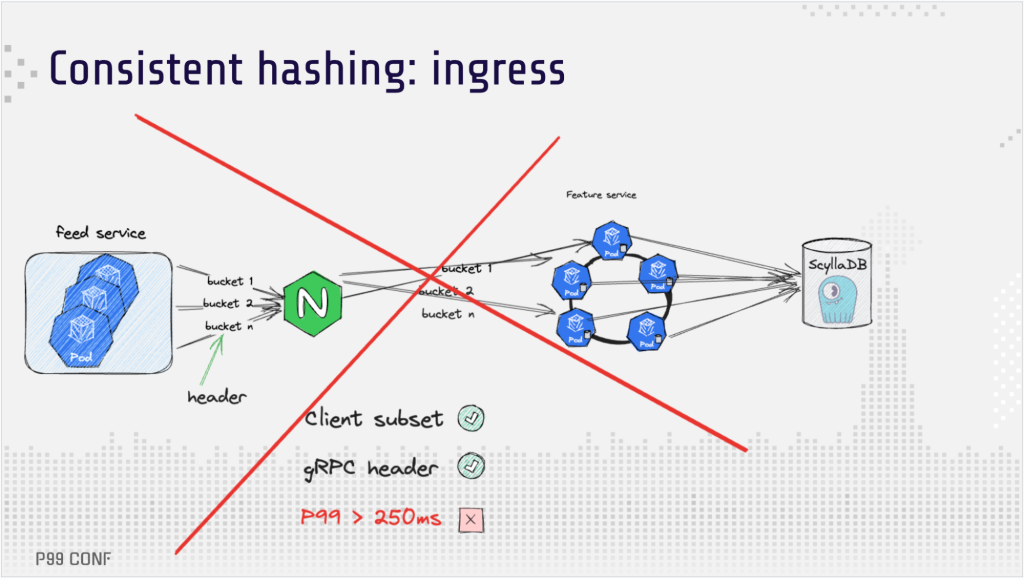
Unfortunately, pinpointing the cause of latency degradation would have required considerable time, as well as observability improvements. A different approach was needed to scale the feature store in time.
To meet the deadline, the team split the Feature service into 27 different services and manually split all entities between them on the client. It wasn’t the most elegant approach, but, it was simple and practical – and it achieved great results. The cache hit rate improved to 95% and the ScyllaDB load was reduced to 18.4 million rows per second. With this design, ShareChat scaled its feature store to 1B features per second by March.
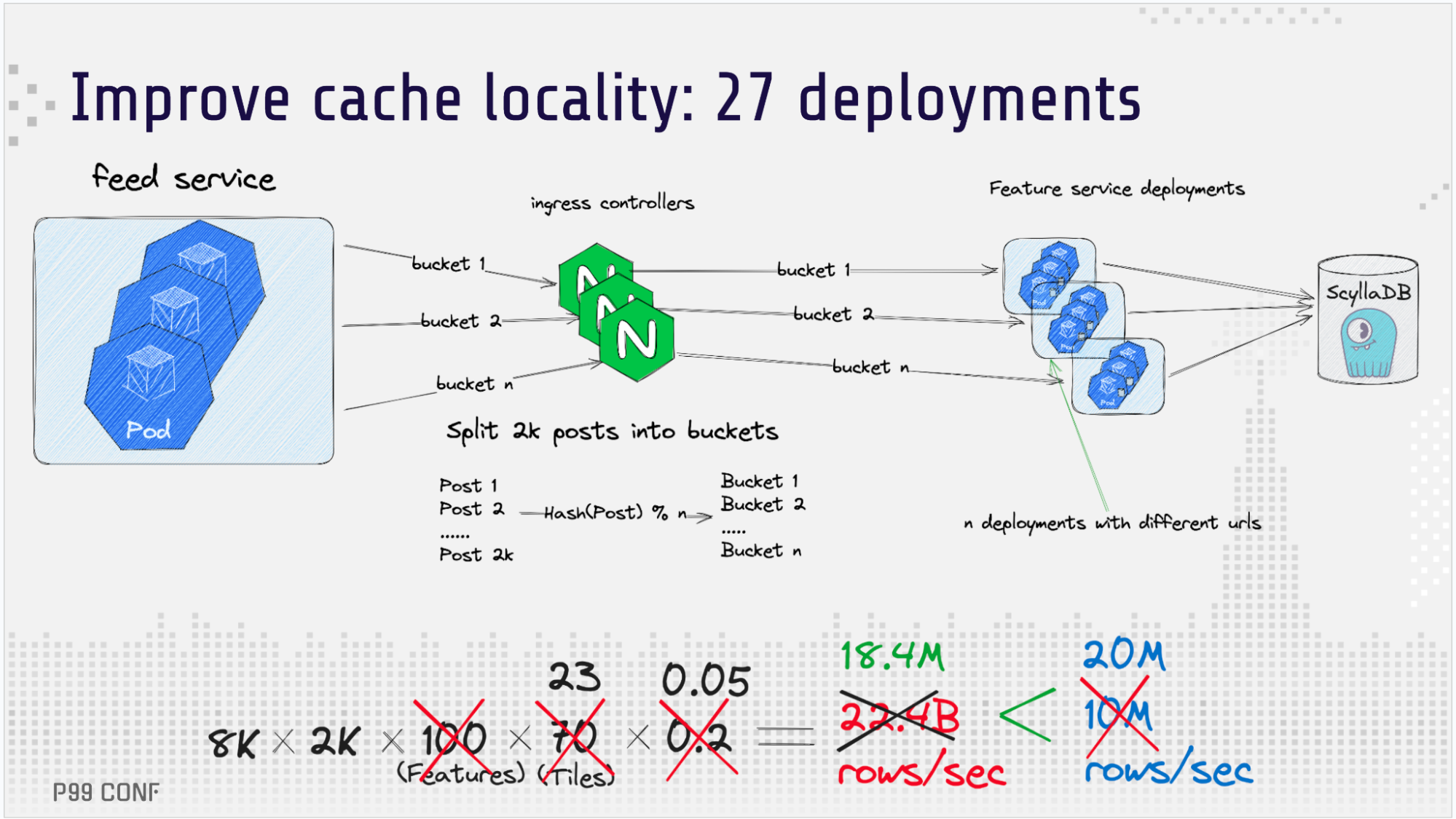
However, this “old school” deployment-splitting approach still wasn’t the ideal design. Maintaining 27 deployments was tedious and inefficient. Plus, the cache hit rate wasn’t stable, and scaling was limited by having to keep a high minimum pod count in every deployment. So even though this approach technically met their needs, the team continued their search for a better long-term solution.
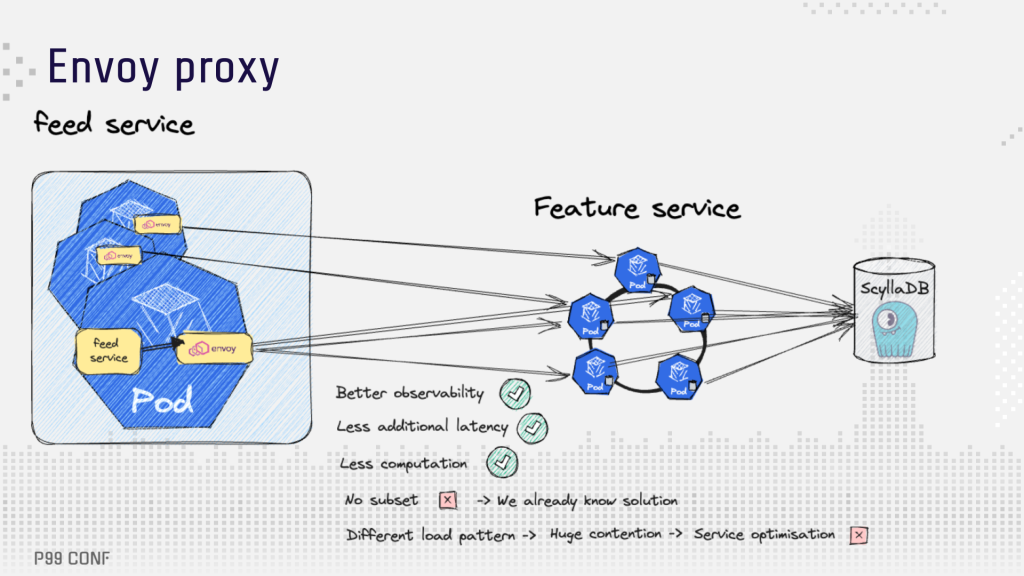
The next phase of optimizations: consistent hashing, Feature service
Ready for yet another round of optimization, the team revisited the consistent hashing approach using a sidecar, called Envoy Proxy, deployed with the feature service. Envoy Proxy provided better observability which helped identify the latency tail issue. The problem: different request patterns to the Feature service caused a huge load on the gRPC layer and cache. That led to extensive mutex contention.
The team then optimized the Feature service. They:
- Forked the caching library (FastCache from VictoriaMetrics) and implemented batch writes and better eviction to reduce mutex contention by 100x.
- Forked gprc-go and implemented buffer pool across different connections to avoid contention during high parallelism.
- Used object pooling and tuned garbage collector (GC) parameters to reduce allocation rates and GC cycles.
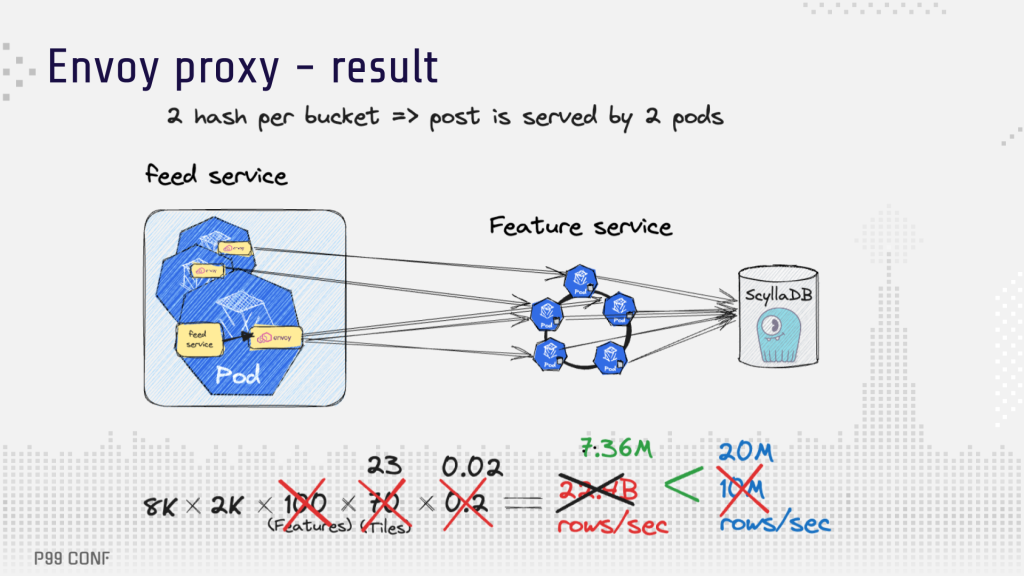
With Envoy Proxy handling 15% of traffic in their proof-of-concept, the results were promising: a 98% cache hit rate, which reduced the load on ScyllaDB to 7.4M rows/sec. They could even scale the feature store more: from 1 billion features/second to 3 billion features/second.
Lessons learned
Here’s what this journey looked like from a timeline perspective:
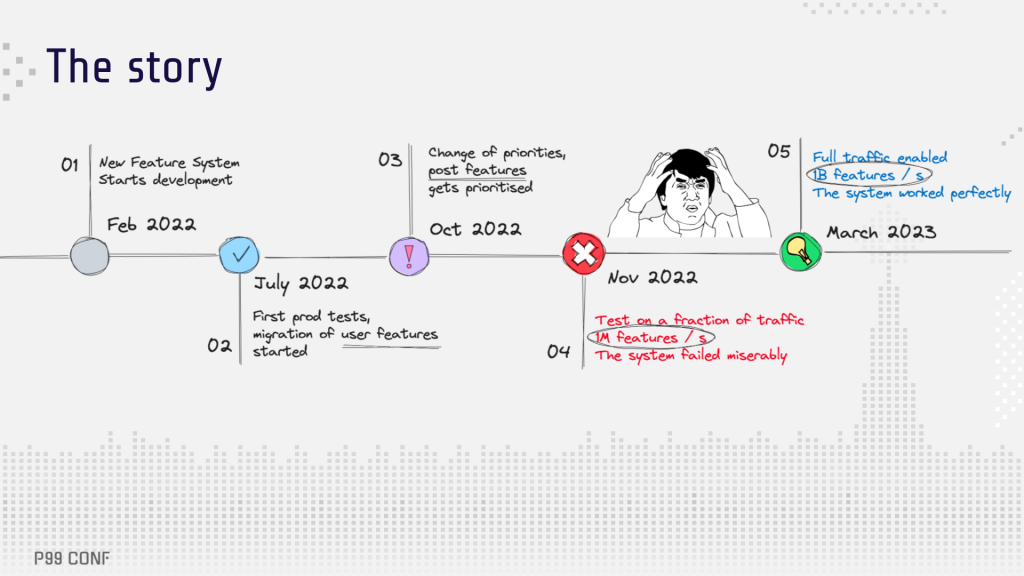
To close, Andrei summed up the team’s top lessons learned from this project (so far):
- Use proven technologies. Even as the ShareChat team drastically changed their system design, ScyllaDB, Apache Flink and VictoriaMetrics continued working well.
- Each optimization is harder than the previous one – and has less impact.
- Simple and practical solutions (such as splitting the feature store into 27 deployments) do indeed work.
- The solution that delivers the best performance isn’t always user-friendly. For instance, their revised database schema yields good performance, but is difficult to maintain and understand. Ultimately, they wrote some tooling around it to make it simpler to work with.
- Every system is unique. Sometimes you might need to fork a default library and adjust it for your specific system to get the best performance.