Epic Games & Unreal Engine: Where ScyllaDB Comes Into Play
How Epic Games uses ScyllaDB as a binary cache in front of NVMe and S3 to accelerate global distribution of large game assets used by Unreal Cloud DDC
From running Fortnite to building distant worlds for StarTrek: Discovery, Unreal Engine boldly takes real-time 3D graphics where none have gone before. Epic Games’ Unreal Engine is a sprawling multi-tool development environment for creating games and other real-time 3D content. For creators, the possibilities are virtually endless. But so are the technical complexities of supporting this massive, highly distributed community of creators.
Joakim Lindqvist, Senior Tools Programmer at Epic Games, recently shared the inside perspective on what’s involved in supporting the rapidly-growing ranks of developers across their community at ScyllaDB Summit 23. This article shares his take on what game development involves under the hood, and how Epic Games architected a system for fast, cost-efficient caching to accelerate the global distribution of large game assets for Unreal Engine.
Share your database experiences at ScyllaDB Summit and join a rather impressive list of past speakers: Epic Games, Discord, Disney+ Hotstar, Zillow, Strava, ShareChat, Expedia, Palo Alto Networks, Ticketmaster… to name just a few.
Become a ScyllaDB Summit Speaker
The Complexity of Building 3D Real-Time Graphics
Lindqvist starts by explaining that all the realistic 3D graphics in the games we’ve come to know and love essentially come down to two core ingredients. First, there’s the source code that’s used in the game and in the framework of tools around it (like the Unreal Editor runtime). Then, there’s various “game assets”: mesh 3D models, textures describing the surface of an object, sound, music, specialized particle systems, and so on. These assets vary wildly in size, from KBs to GBs.
It’s not unusual to have over 500 people producing assets for a single game. Before 2020, these people were typically concentrated in various studios with on-premise infrastructure supporting their teams. However, the COVID-19 pandemic brought a rapid shift to developers primarily working from home or in much smaller studios around the world. As a result, all the game assets required for a single game, including some extremely large assets, need to be readily available to people around the world. It’s not enough to ensure that each developer can access the latest assets when they log in each morning. Each time a collaborator adds or changes something throughout the day, the associated assets need to be immediately propagated out across the team.
For an idea of what’s involved here, consider this image of how the Unreal Editor is used to build a trivial 3D scene:
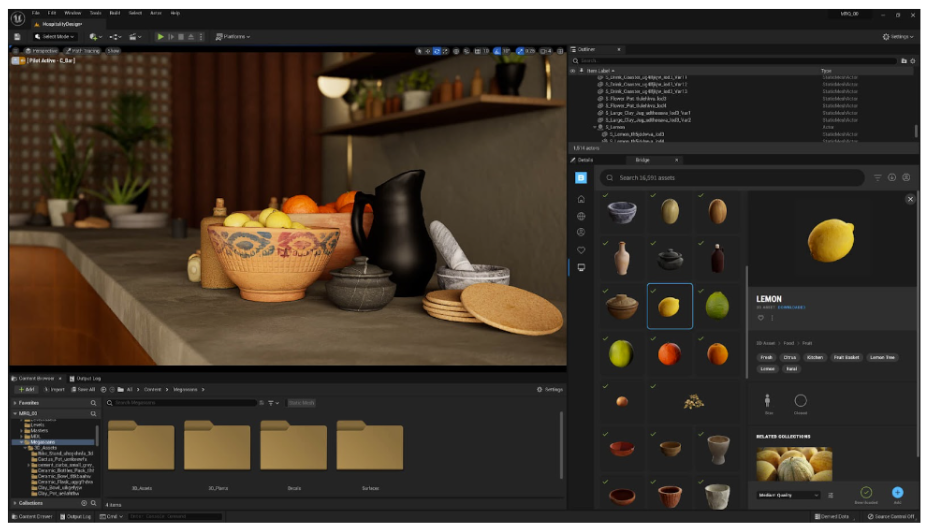
Something as seemingly simple as the lemon actually consists of multiple assets. There’s lemon mesh, multiple textures, a shader, etc. And that’s just one small part of the scene. Consider all the details that go into creating immersive virtual worlds, and you can imagine how the number and range of these game assets quickly spirals out of control.
Adding to the complexity, these assets are initially saved in the highest possible quality format – which unfortunately does not allow them to be rendered in an editor or a game. Before they can be used, these assets need to undergo a data transformation process called “cooking.”
Cooking and Caching
Lindqvist explains, “These game assets are typically submitted into source control in a generic format, and need to be converted into formats that work for a specific platform (XBox, PlayStation, etc.) through file format conversions, compression, compilation etc.” This conversion process is called “cooking.” The cooking process doesn’t really understand which assets are needed ahead of time (dependencies are discovered as parent assets are processed). Cooking requires fast response times and high throughput access to all the required files.
Enter caching. The cache is used to accelerate game cook time. Just as you might have a cache for code compilation, Epic Games frequently relies on caching of these transformations in what is called the DDC (derived data cache). “Users have a local DDC that contains copies of assets they have converted in the past (with some cleanup rules) and also shared caches,” Lindqvist continued. “Historically, these shared caches relied on on-prem network filesystems to share content between users. This was always a headache as teams moved to multiple locations. However, with team members working from home, it became unusable because this system can fetch a lot of data – and doing so over a VPN is just painfully slow.” Even with this caching, cooking across the now-distributed teams was taking up to 24 hours – which is hardly ideal for fast-paced development and collaboration.
Inside the Unreal Cloud DDC, Where ScyllaDB Comes into Play
To further accelerate the cooking process, Epic Games added another tier to their caching system: a DDC layer that’s in the cloud (hence the name Unreal Cloud DDC). This allowed Epic Games to quickly scale to new locations and have a good distribution of nodes around the world closer to where their users lived.
Lindqvist took us deeper into the architecture of Unreal Cloud DDC.
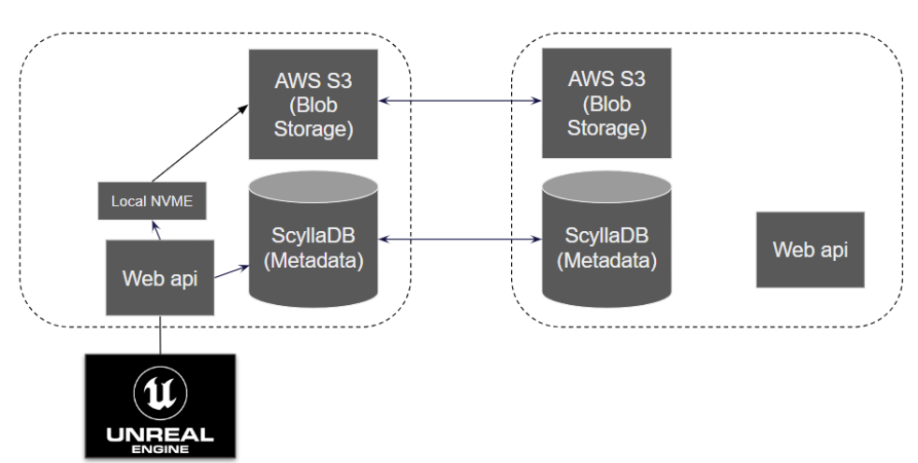
Architectural diagram of Unreal Cloud DDC; the box on the right shows replication
- Their API is running in multiple Kubernetes clusters around the world.
- Each node has a 7 TB attached NVMe drive for local caching of frequently-accessed payloads. This enables them to serve the “hot” large payloads quickly. But, it’s not large enough to store their entire data set.
- S3 is used to store most payloads (~50 TB per region for two months of game building) since it’s quite cost effective to keep content there. If the requested payload isn’t in the local NVMe cache, it’s fetched from S3.
- ScyllaDB NoSQL is primarily used as a binary cache for the metadata, sitting in front of the local NVMe and the S3 blob storage. A content hash, stored on ScyllaDB, is used to reference the saved blobs.
When a gaming asset object is uploaded, its metadata goes into ScyllaDB as a cache key. If the record is smaller than 64 KB (which many are), then the payload itself is stored in ScyllaDB. Large payloads go into S3 storage.
When an object is requested, that request goes through the API to ScyllaDB, which serves the metadata with sub-millisecond responses. ScyllaDB’s response details all the different files required to complete that request. The next step is to determine whether the associated payloads can be served from local NVMe, or if they need to be retrieved from S3.
Implementation Details
The objects cached in the DDC use a self-describing binary format called Compact Binary (conceptually similar to JSON or BSON, but with many custom features). Here’s an example:
{
“name”: “largeFile”,
“size” : 2480,
“attachment”: 9fffabc5e0a…1f084f8c5e
}
One critical custom feature, attachments, lets them store the large asset and its metadata in a single object, then control if and when the attached assets are downloaded. A single large cache object can have some attached assets streamed as needed, while others are downloaded from the start.
Lindqvist explains the logistics as follows: “These attachments are referenced by hash. We use a content addressing scheme (meaning the hash of the payload is used as the name of the asset) that allows us to quickly de-duplicate large attachments that might have different objects describing them. We also support arbitrary mapping from one key to an object (the input object to the resulting output produced) as is common for caches.”
If they discover that, for example, two cache records both reference the same texture, they will have the same asset hash, and they are treated as duplicates. “We don’t need to replicate it, we don’t need to store it twice,” Lindqvist continued. “There’s no need to have a client download something that’s already there, and there’s no need to upload something if the cache already references it. That results in some nice performance gains.”
Epic allows ScyllaDB to perform its replication across regions, but they actively opted out of S3’s internal replication. They prefer to self-manage the replication of the large assets in the S3 buckets as follows: “Whenever we upload new content, we write a journal of that into ScyllaDB, then we can follow that in other regions to replicate objects as they come in. We do this for multiple reasons: partially to have control over which blobs are actually replicated (right now we replicate everything, but we have future use cases that will require partial replication). Also, because we generally replicate it faster than S3 when we do this ourselves. Plus, it allows us to perform selective replication, which will become instrumental in future use cases.”
Why ScyllaDB?
How did Epic Games select ScyllaDB for this new caching layer? They originally used DynamoDB for their prototype, but soon started looking for faster and more cost-efficient alternatives. DynamoDB was simple to adopt, but they needed something more practical for their long-term goals. Looking at ScyllaDB, they found that the lower latency was a better match for their performance-sensitive workload, and the cost was much lower as well. Moreover, putting some elements of their roadmaps into play required a database that could be deployed across different cloud providers, as well as on-premises.
Lindqvist summed up, “This workload is quite performance sensitive, so getting quick responses from our database is key. This approach saves us plenty of headaches, and it performs really well. We’ve had this system deployed within Epic for over a year, and are working with licensees to get this deployed for them as well. It’s been serving us well to allow people to work much more efficiently. [Even as] assets continue to grow even larger, people can still work from home.”
For a deeper dive into how they implemented everything from the hashing to the replication of large assets in S3, watch the complete talk here:
Bonus: If you are keen to learn more about what Epic Games is working on, go to their GitHub (https://github.com/EpicGames), and look around. Maybe you’ll become a game developer yourself.