Building Event Streaming Architectures on ScyllaDB and Confluent with Kafka at Numberly

Recently I had the privilege to host a webinar with some very good friends of ScyllaDB, including Numberly’s CTO Alexys Jacob and Chief Data Officer Othmane El Metioui, as well as Tim Berglund, the Senior Director of Developer Relations at Confluent. They were joined by my colleague Maheedhar “Mahee” Gunturu, our Director of Technical Alliances.
Numberly: Combining the Power of Scylla and Kafka
Mahee turned the session over to Alexys Jacob of Numberly, who described the French AdTech company’s current architecture and its constituent components.
“At Numberly we run both Scylla and Confluent Kafka on premises on bare metal machines. This means that this is our own hardware, network and automation at play. The key thing here to remember is that we run both technologies on an active-active multi-datacenter topology because they are mission critical to us.”
Alexys was quick to clarify, “Running on-premise does not mean we are hermetic to cloud deployments. We actually have a hybrid approach with direct connections between our datacenter backbones and some cloud providers such as AWS.”
“Running your own multi-datacenter infrastructure level requires skills and dedication that many would find better spent in developing their products. We can afford it after more than 20 years of experience and knowhow, but I find it important to say that you have to know where to spend your own energy.”
“Both Scylla and Confluent have high quality cloud offerings providing a robust response to your technology needs.”
Based on Numberly’s experience with other vendors Alexys admitted that was not always the case, “with cloud providers often lagging behind versions and offering poor observability, especially on highly optimized technologies such as Scylla and Kafka. So when choosing who’s going to run and operate your Scylla and Kafka in the cloud, my standpoint is to trust the people behind the technology, because they know better and their interest is always aligned with yours. This is especially important when things go wrong, and they will someday, believe me.”
Numberly’s Stack
Alexys then took the audience through a walkthrough of how they deployed Scylla and Confluent side-by-side in their environment.

“On the Scylla side we have what I think should be a standard for anyone serious about Scylla deployment using Scylla Manager and Scylla Monitoring Stack. One thing that I want to highlight is that we do use data expiration a lot. On almost all our data stored in Scylla TTL expiration is very important and powerful to deal with legality — our data retention constraints — especially in Europe.”
“On the Confluent Kafka side we use Kafka Connect, Streams and KSQL supervised through a schema registry and homemade control center interface and Grafana dashboards.”
Numberly had to originally make this configuration work using their own tooling. When they started combining Scylla and Kafka the powerful Scylla CDC Source Connector was not available. “So we wrote Kafka streams and Python pipelines to synchronize Scylla tables and Kafka topics.”
“We were monitoring the Scylla CDC advancement within anticipation of joy. Because now that Scylla has a certified Confluent CDC connector we will be evaluating which pipelines and streams could be replaced with it when appropriate. We anticipate that this will greatly help us simplify our topology.”
Numberly’s Scylla + Kafka Use Cases
With that, Alexys introduced Othmane, who provided more details by explaining Numberly’s production use cases, while detailing the limitations they faced and how they overcame them.
Use Case #1: Remote State Store for Kafka Pipelining
The first deep dive Numberly provided was how they had chosen to deploy Scylla in a rather unique way: as a low-latency remote state store for Kafka streaming pipelines. Which meant that Scylla was not just a source, or a destination, for their Kafka pipelines, but sat as a middle ground between upstream providers and downstream consumers. Othmane noted this was “one of our core pipelines to feed real time behavioral data to downstream business processes.”
First Iteration: Beanstalk + RabbitMQ
In their original topology, Othmane described how as a user navigated through websites their activities flowed through Numberly’s tracking API which was then queued locally in Elastic Beanstalk and then shipped into a RabbitMQ exchange. “From there we had Python programs that had two main purposes. The first purpose of the program was to consume RabbitMQ to build ID matching tables and then save them into Scylla using the right model.

“The second purpose was to enrich tracking data coming in, by using an ID matching table that was built previously and then push them so downstream business processes could benefit from it. This process was used for four years, until we decided to test out a new solution to simplify our pipelines and reduce latency.”
Second Iteration: Redis + Confluent Kafka
“We decided to replace our web front end local queuing system from Beanstalk to Redis to improve performance. Then we integrated Kafka to log our incoming events and to build our ID matching tables. These ID matching tables were then sync’ed to Kafka as compacted topics in a compact-topic-using connector. The Kafka stream application was in charge of matching and enriching incoming events using KStreams and a KTable JOIN. Just keep in mind that all our applications were and are still running on Kubernetes without any persistent storage.”
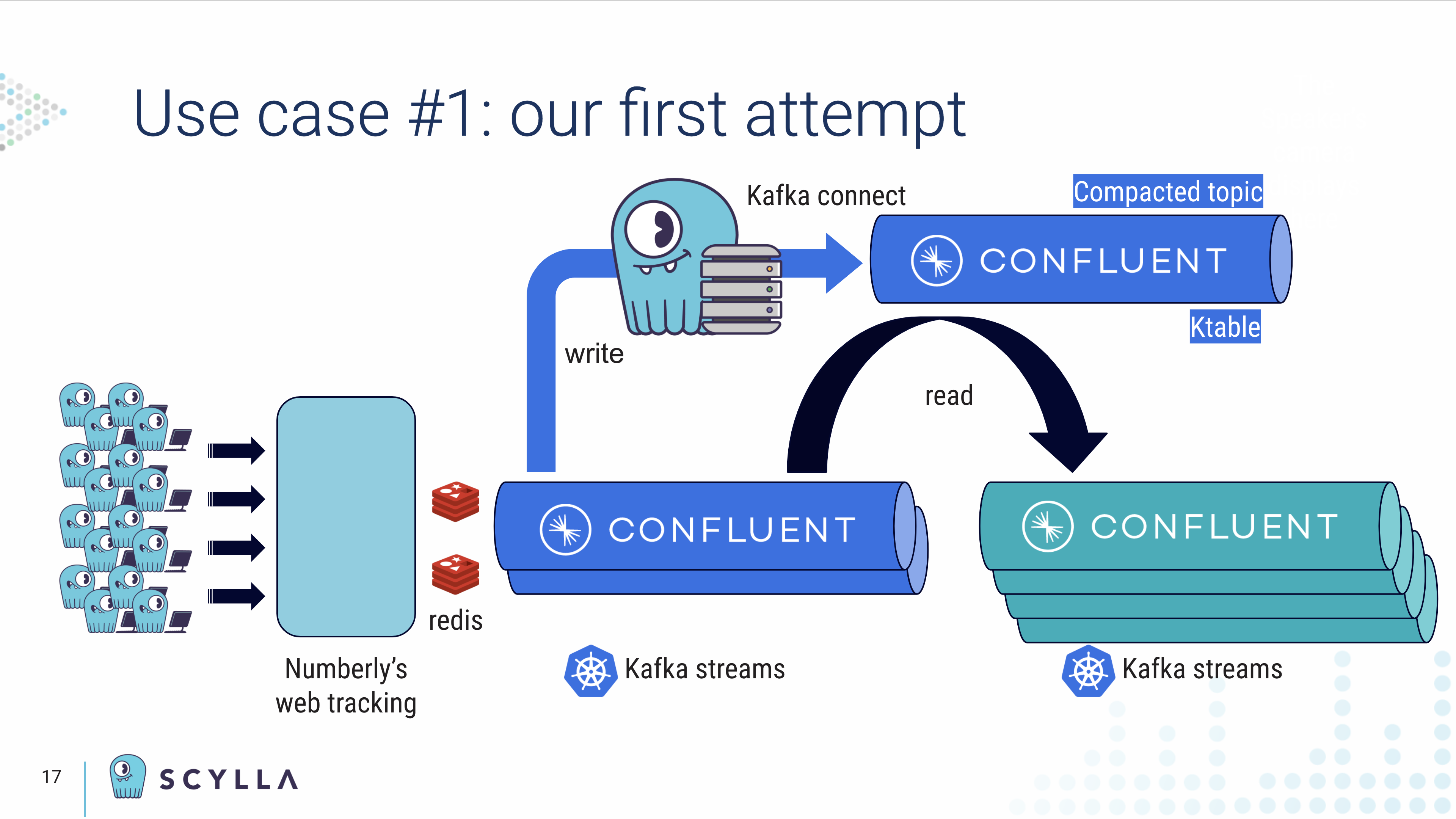
“What I just presented worked like a charm on our staging platform, but as soon as we moved to production we faced some limitations on Kafka streams. The first limitation was that retention for ID matching tables with a long data retention policy generated state stores from 150 gigabytes to 1.2 terabytes.”
Further, Othmane observed, “We also had to perform successive JOINs on the different tables resulting in huge state stores inside our applications. Since we’re running on Kubernetes we faced some out of memory issues.” Plus their applications lost their states. “Rebuilding our state after an application crash was a nightmare and costly, due to users’ standby replicas.”
Third Iteration: Scylla + Confluent Kafka
“At this stage we realized we had to change our approach, as it was clear to the team that the issue was the state store. So, going back to the original need we needed a highly available database with low latency read-write and a key value store. So naturally we looked at Scylla.”
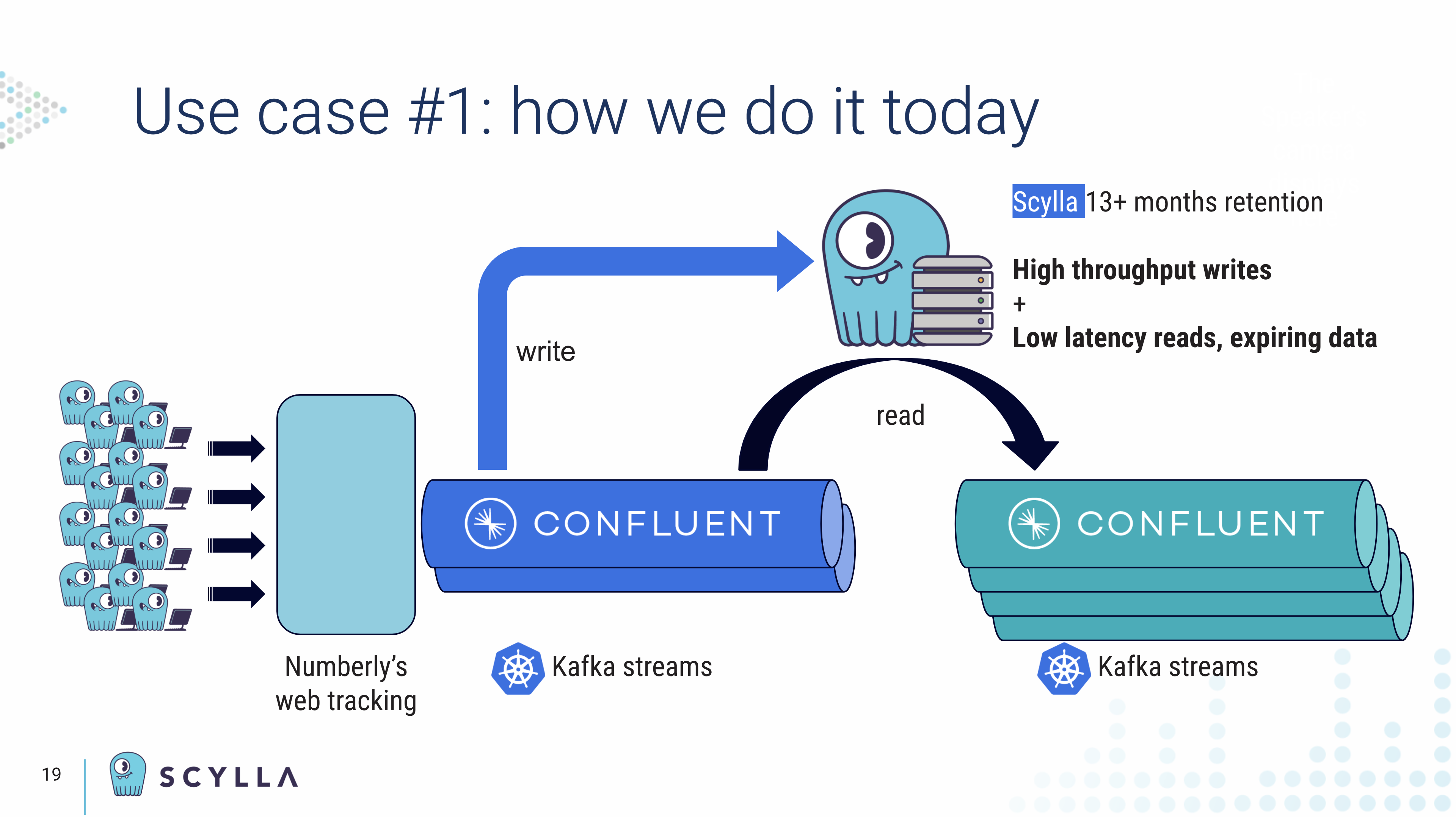
“Today, we do not sync matching tables to Kafka anymore. Instead JOINing between KTable and KStream is replaced with optimized CQL prepared statements to look up data and enrich our pipeline from Scylla. And finally, the ID matching tables are now exclusively hosted in Scylla.”
Use Case #1 Takeaways
“What are the takeaways from this use case?” Othmane rhetorically asked.
- Metrics — “And I say ‘metrics, metrics, metrics!’ Because, without metrics there is no successful tuning.
- Prometheus client — Part of the Scylla Monitoring Stack, Othmane recommended it to the audience, describing how it will ease their monitoring.
- Tuning — “Tuning is important in such a pipeline. Size the number of partitions regarding your query. That’s important.”
- Time-to-Recovery — “Mind your time to recovery.”
- Max Throughout — “Capacity should be able to have at least three times the average of your throughput.”
- Add Query Caching — “But no more than your query time to maximize consistency.”
- Shard-Aware Drivers — ‘Make sure you use a shard-aware client for Scylla.”
About this last point, if you haven’t read the two-part blog from Alexys Jacob on making a shard-aware Python driver, it’s worth a look. Part One covers the reasons to make a driver shard-aware, and Part Two shows the implementation details and performance benefits.
Use Case #2: Synapse
“Synapse is our core marketing segmentation engine leveraging Kafka and Scylla. In brief, we gather different data flows that are resources in Kafka. We then use a set of Synapse microservices to be able to apply business rules while data is moving.”
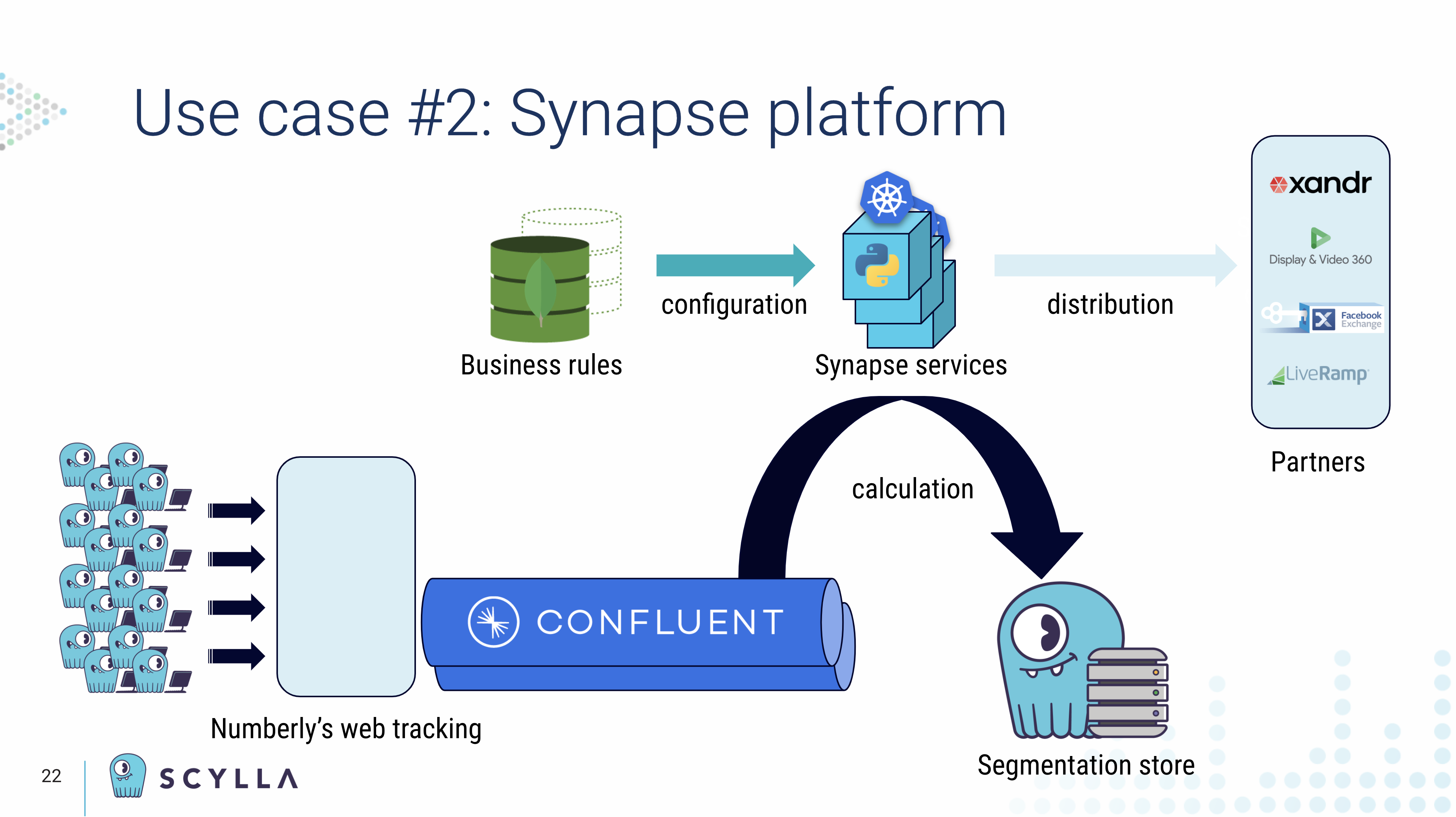
“Whenever data matches a business rule, the information is persisted in Scylla with a mandatory TTL, of course for GDPR and also to ensure that, if there is no update, the data is deleted and the individual is removed from the segments — automatically, of course.”
“On our first iteration we tried a workaround on an existing connector. At that time results were not as expected, so we rolled back to a custom microservice to sync from Kafka to Scylla. With the brand new certified connector now available we’ll give it a second look.”
“The second usage is distribution. Whenever a sync with an external platform is triggered by business,” such as Xandr or LiveRamp, “Synapse services consume segments from the data within Scylla and make it available in a Kafka topic.”
Kafka & Scylla: A Complementary Match
“Looking at the use case I previously explained, we can see that Kafka and Scylla are complementary to one another and here’s why:
“We choose Scylla over native Kafka since we have a large number of tables, which will impact our number of topics if you had to use Kafka natively. You would end up with 10,000 or more compacted topics to be created. TTL management on Kafka compacted table adds custom processing logic and complexity and, of course, also propagating Scylla expired data still adds complexity. So of course we crave support for expiration events in CDC, which is still an open issue. And we’re really waiting for it.” (See Github #8380)
Furthermore, Numberly appreciates Scylla’s consistent low latency and capability to consume and enrich data at scale.
“But of course no technology is perfect. So we ended up with some limitations using Scylla. We had some OLAP processing inside this platform that had to perform some counting on high cardinality data.” While Numberly at first looked at Scylla, Othmane explained the limitations they found.
“When you have a user (here our partition key on Scylla) they are part of multiple segments which represent the cluster key — counting is okay. We can do it through Scylla. A segment which is used as a partition key when it has a large number of users — used as a clustering key — this gives us large partitions. Those large partitions are hard on Scylla. So we ended up using Kafka streams to compute those statistics on the fly.”
Use Case #2 Takeaways
“So what are the takeaways of this use case?
- Match Table Models to Queries — “First, define your table models in Scylla to suit your queries. This is really important.”
- Forecast Data Volume — “Forecast your data volume on your models. Does it suit your volume? Will it suit your use case? Will it work on production? It is important before you go live.”
- Mind Large Partitions — “Because this can and will damage your cluster performance if you don’t.
- Kafka Streams — “Kafka Streams turn out really great for on-the-fly aggregations.”
- Persist Aggregations to External Data Store — “Those aggregations should be persisted on an external store to give you the ability to go and do multiple time span lookups. Kafka Streams are great, but on real time ‘hot’ data.”
For Numberly, the bottom line was that Kafka and Scylla “play very well together.”

Scylla’s Change Data Capture (CDC) Implementation
With that Othmane handed back the session to Mahee, who presented on how Scylla implemented CDC. For those who hadn’t used it before, Mahee explained that Change Data Capture “allows you to query the history of changes made to the database.”
“While querying a database gives you a static view into your data, with CDC you get more of a temporal view into your data. It is a log of all the modifications, as they happen, to your data in the database. Once you enable CDC Scylla will start capturing the changes to your data, and you will be able to access them asynchronously and do whatever you want with them.”
“Now let’s try to understand some use cases where CDC can be used. Any application which requires a group of microservices to work in tandem with each other. Where the state needs to be propagated from one service to another. CDC can be useful there. Some examples here are applications based on IoT — like smart automation — or in retail like point of sales and inventory-based applications, just to name a few.”
“If you are an ETL developer, you know how new data arrives in your landing zones and you have run a series of data pipelines to transform your data. Now, with CDC your life becomes much easier. As we present the new data, along with the change log, which provides an s3 data lineage for your application.”
“With CDC you can also enable various integrations. If your application needs search, now you can stream the data incrementally to Elasticsearch. Or if you need to migrate or mirror your data from one database to another. Or if you need to periodically populate your long term storage like Hadoop or Snowflake or Redshift. Then you can stream the state incrementally to these destinations oftentimes via Kafka.”
“Kafka is a very integral part of our CDC offering. Tim is going to speak a bit more about this, the next part of the presentation. For now, let’s take a peek into how it is implemented. In Scylla the features can be enabled by table, which then creates a CDC log table underneath. That is co-located with the base table. The rows are ordered by timestamp and the modification order ID.”
“Columns are mirrored from the original base table and each row is mirrored for the pre-, post-, and delta images. Every record contains some modifications and the TTLs of the data being written. The default TTL of the CDC data is around 24 hours, but this is configurable. This is mainly to reduce risk of uncontrolled buildup and prevent any overflow.”
Scylla’s CDC Write Path
“When you normally write into a Scylla table the client sends CQL to the coordinator node which processes it, and then RPC calls are made to the replica nodes. Writing to a CDC enabled table is pretty much the same thing, but the requests get intercepted and pre-processed at the coordinator, and we optionally issue pre-image reads to get data for pre- or post- image generation.”
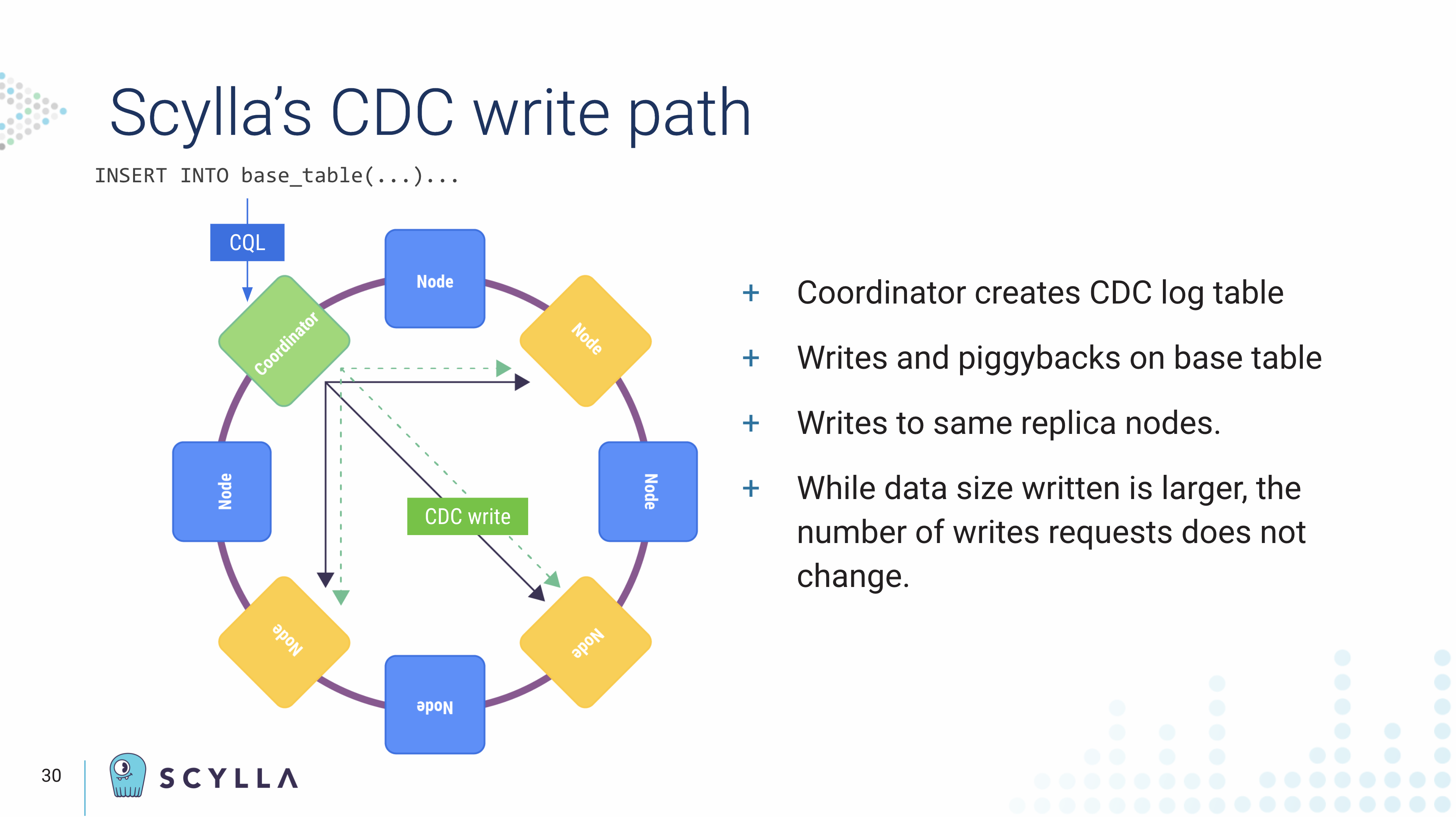
“Then the CDC mechanism will piggyback the writes to the log table to the original mutations which are going to the same replica nodes. So we don’t generate more writes, but we do generate more data. This is important to understand. So the payloads increase, and we have to size appropriately to account for the additional CDC enabled tables.”
“Every mutation sent to a CDC enabled table generates one or more rows and the CDC log table, there are certain key elements to the CDC log tables.”
These include:
- Row Keys
- Changes per non-key columns (deltas) — optional
- Pre-image (prior state data) — optional
- Post-image (current state of row) — optional
Mahee noted that CDC tables are using the same consistency level as the base table, “so you get the same guarantees as the base table.”
“The CDC log is read through normal CQL statements, which is quite cool. As now, you can access a whole bunch of information via CQL and what we call streams, which gives you more information about the metadata of various changes and also the data lineage of the current state of the database. The data is replicated but deduplicated and can be read through regular CQL. Not just the post-image, but also the deltas and the pre-image.”
“You can consume all this data without knowing a whole bunch of distributed systems magic, which we know is not trivial. The core functionality is very simple, but it allows you to build more advanced things on top of it.”
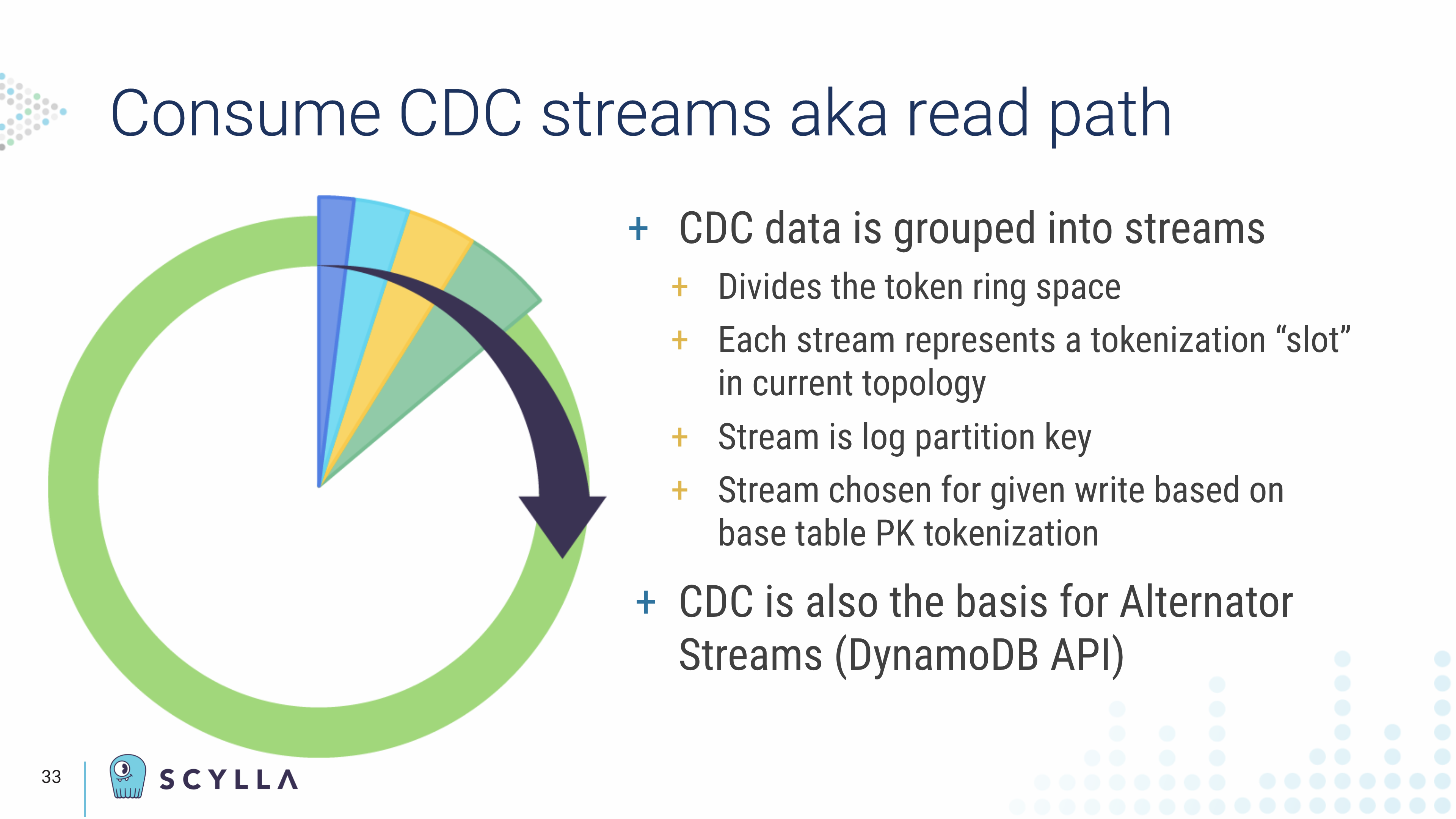
“The CDC log is partitioned into what we call streams. This divides the entire token ring space of the cluster and each stream represents a slot in the token ring. This is the partition key of the CDC log table. The client reads the data in the CDC log table in a round-robin fashion and traverses through the token range. This is very useful because it allows the client to read the CDC log without doing any cross node queries, which is a very expensive operation. It allows you to view a single partition group at a time and get a clear timeline view of the data.”
“A lot of these details are abstracted out if you are simply using the shard-aware client driver for these operations. As long as you’re using the shard-aware connector most of these details won’t even be visible to you.
Mahee also noted that we will roll out more functionality into our DynamoDB compatible API, because CDC is the basis for our implementation of Alternator Streams.
The Power of Confluent and Scylla CDC
This presentation was followed by Tim Berglund, who showcased the capabilities and configuration of the newly certified Scylla CDC Source Connector.
Tim began by talking about how Kafka works noting, “It’s been a little bit of a substrate to other architectural components in the discussion, which is a role that Kafka often finds itself in. But I think it’s worth a little bit of time to just remind ourselves of the fundamentals and dig into Kafka Connect a little bit,” because that is the part of Kafka that enables the consumption of CDC data.
Tim laid out Confluent’s goal to create an event streaming platform based on Apache Kafka that can serve at the heart of every company. “We believe that event driven architecture is a generational paradigm. This is the way that people are beginning to build systems. And probably twenty five years from now, it will have become the entrenched legacy. And maybe in twenty five years there’ll be some new idea that’s pushing it out of the way, but it will be a real part of the future.”
“We do that with an on-premise platform called the Confluent Platform that builds on Apache Kafka. And also a fully-managed service called Confluent Cloud. Confluent Cloud runs a hosted version of Kafka and Kafka Connect, and ksqlDB for stream processing and a number of other features.”
Reminder: Kafka is a Log
Each person who comes to Kafka brings their own perspective, as Tim observed. Some think of it as a log. Others think of it as a queue. However, Tim suggested those who call it a queue should “put a rubber band on your wrist and maybe snap it lightly every time you do to train yourself out of that habit.” Tim confirmed: Kafka is a log. “And as messages get written, they stay there.”
In comparison, Tim noted, “queues are usually ephemeral things, where an event goes into the queue and then it’s consumed and it’s gone from the queue. In Kafka you have a configurable durability — a configurable retention period — on each topic, so they really function as logs.”
“And to scale we split them into pieces and we can distribute those pieces among multiple brokers in the cluster. So topics can become really arbitrarily large. They could handle all kinds of events. We’re talking today about CDC but anything that one can conceive of as an event that one might want to store in an immutable and ordered way — that’s data that can go into a log.”
“It’s a little more difficult to read than to write. We have that partitioned topic, right? This log that’s broken up into pieces. And I can deploy a thing called a consumer easily enough that reads from those partitions and, in this case, you can actually have multiple consumers.”
“Again, you know if you think of a queue — which as we’ve said Kafka is not — a queue, really, once you consume the thing is gone and implicitly you don’t want anybody to be able to see it again. But a log I can have one consumer read from that log and another consumer read from that log. Because I might have two separate applications, two separate concerns, that are doing processing on that data. And I can stand those applications up and they read from that log in orthogonal ways without influencing one another.”
“Now they’ll get all the messages. Messages inside a partition are strictly ordered, of course, between partitions they’re not strictly ordered because of the laws of logic. It just doesn’t happen. So you know: by partitioning a topic, you lose global ordering, but that usually doesn’t matter, interestingly. Usually just within a partition is what you want.”
“And this is cool, but remember I said partitions could get really big? So we might, at times, need to scale one. I might have more computation to do. I might want fault tolerance. I might just have a lot of messages because I’m doing CDC from some really high volume table in Scylla. So we can see if I deploy additional instances of a given consumer, then the partitions get automatically reassigned to those instances. So reading is a horizontally scalable thing.”
“Now there’s a fairly long and detailed story to tell about how all that works. In its particulars and where the gotchas are and so forth, but this is built into Kafka. Just by being a thing that reads from Kafka I’ve got this Horizontal scalability built into my application. So that’s the basic structure of writing and reading.”
Kafka Connect
“Now we’ll look at some other components in the ecosystem. And given today’s discussion of Change Data Capture, Kafka Connect is a key component. This emerged — I think Kafka was about five years old in 2015 — and what the Community discovered is that people were doing data integration. They wanted to get things into Kafka from non-Kafka sources, and then they did processing of that data in real time in Kafka. And then they wanted to get it out to some non-Kafka sink out in the world. And those things exist! There’s lots of reasons to have, say, a radically scalable NoSQL database like Scylla in your life. Or maybe you’ve got Salesforce.com, or you’ve got s3 or something like that. There are lots of reasons to integrate other systems with Kafka and that’s what Connect does.”
“Kafka Connect is a separate little distributed system that I stand up. I could have a single node Or I could have 2, 3, 5, 10 nodes if there’s a lot of work to do. But that’s this other system that really behaves as a producer writing into Kafka and a consumer reading from Kafka. And we can deploy pluggable connectors into Kafka Connect to talk to source systems and sink systems. There are literally hundreds of those — if you go look on Github there are hundreds of them.”
“We’re really focused on one particular connector today that is very well maintained and responsibly maintained and that’s the Scylla Connector. There’s a source and a sink connector. Again source connectors get data in, sink connectors get data out.”
Built on Debezium
The Scylla CDC Source Connector “is built on a foundation of a project called Debezium. Now if you know Kafka Connect and you ever talked to databases, you probably know what Debezium is. It’s the foundation for most of the free and open source Change Data Capture database connectors in the Kafka Connect world. And CDC is always a source concern, right?”

This is because “sinking into a database is pretty easy — you just write records out. But reading from a database is kind of tough. And we just went through the amazing Scylla features that make this so easy to do and connect.”
In comparison, Tim observed, “Some of the Debezium connectors for other databases? There’s work they have to do that is, we’ll say, ‘non-trivial.’ But being built on this foundation,” the Scylla CDC Source Connector “participates in the broader ecosystem of Kafka source connectors in a very healthy way.”
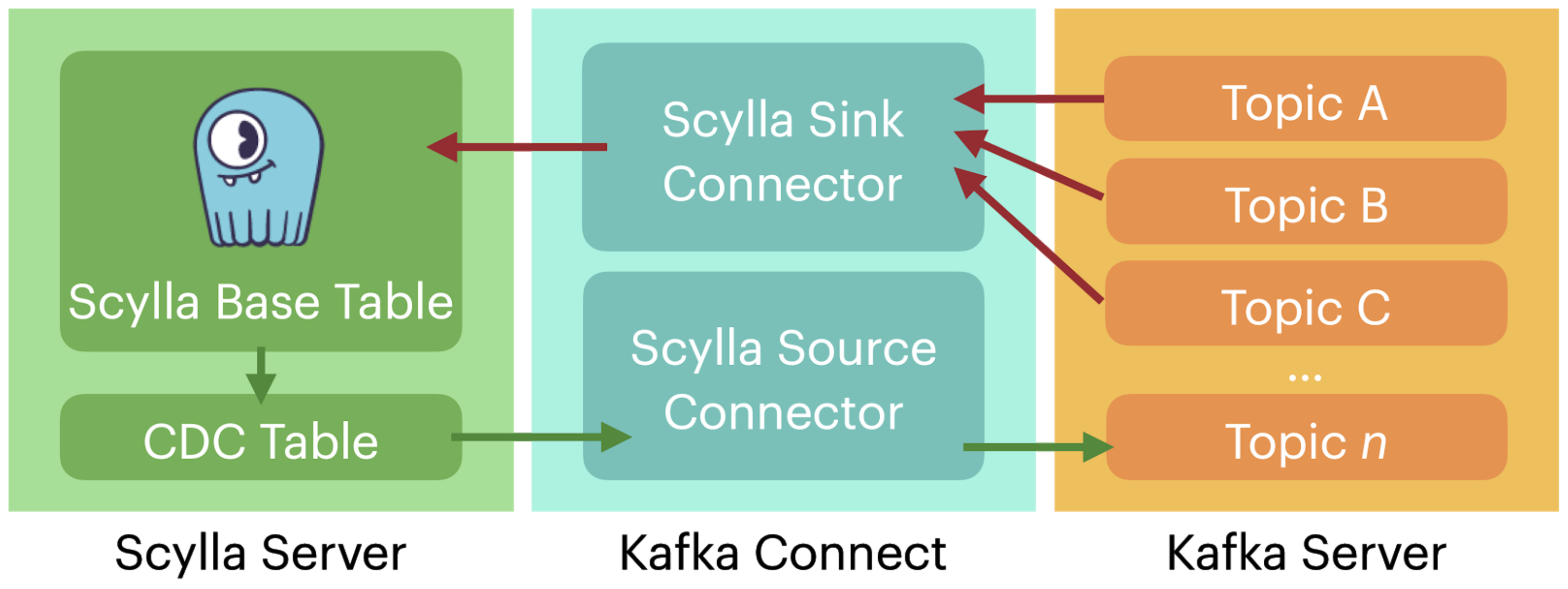
“Here is the canonical architecture diagram for Kafka Connect for the Scylla Source Connector. You’ve got the Scylla server in green, including the base table, and then the CDC table which we’ve just talked about how that works.”
“I hope, as you were digesting the details of that, you didn’t lose the forest for the trees. Because the fact that Scylla does this is just really cool.”
“Again, from a Connect standpoint, this is hard to do with a lot of databases. When we dig into how each connector has to do this, there are just these vastly implementation-dependent different edge cases and hard things. Well, Scylla just makes that table. It says ‘here are the mutations, please read them!’ in this trivial and partition friendly way. So that’s really cool.”
“You’ve got the Scylla table. It’s creating its own CDC table. So in the middle there, the Kafka Connect source connector, all it has to do is just read records from that table. That’s the easiest kind of database read there is. So that’s a very cool thing.”
“Then from there that connector writes those records into one or more topics in the Kafka cluster. Those topics again themselves can be partitioned.” Because of how Kafka operates internally, “all those details work themselves out because of the functionality of those layers.”
“There’s also the sink connector.” For example Tim posited that perhaps, “you want to run some ksqlDB queries on it. Do some real time stream processing on that data and then write it back into Scylla for access by your applications. That sink connector is going to consume from topics and then write those into the table.”
He also reminded the audience that for sinking, of course, there’s no Change Data Capture to do on the sink side. “You’re just taking messages from topics. When a new message shows up, you insert that row into the table in Scylla and nobody gets hurt.”
“And again there doesn’t have to be processing in there, I may just literally read from one table, you know, source from one cluster and sink into another. Or I may add value to those messages in between.”
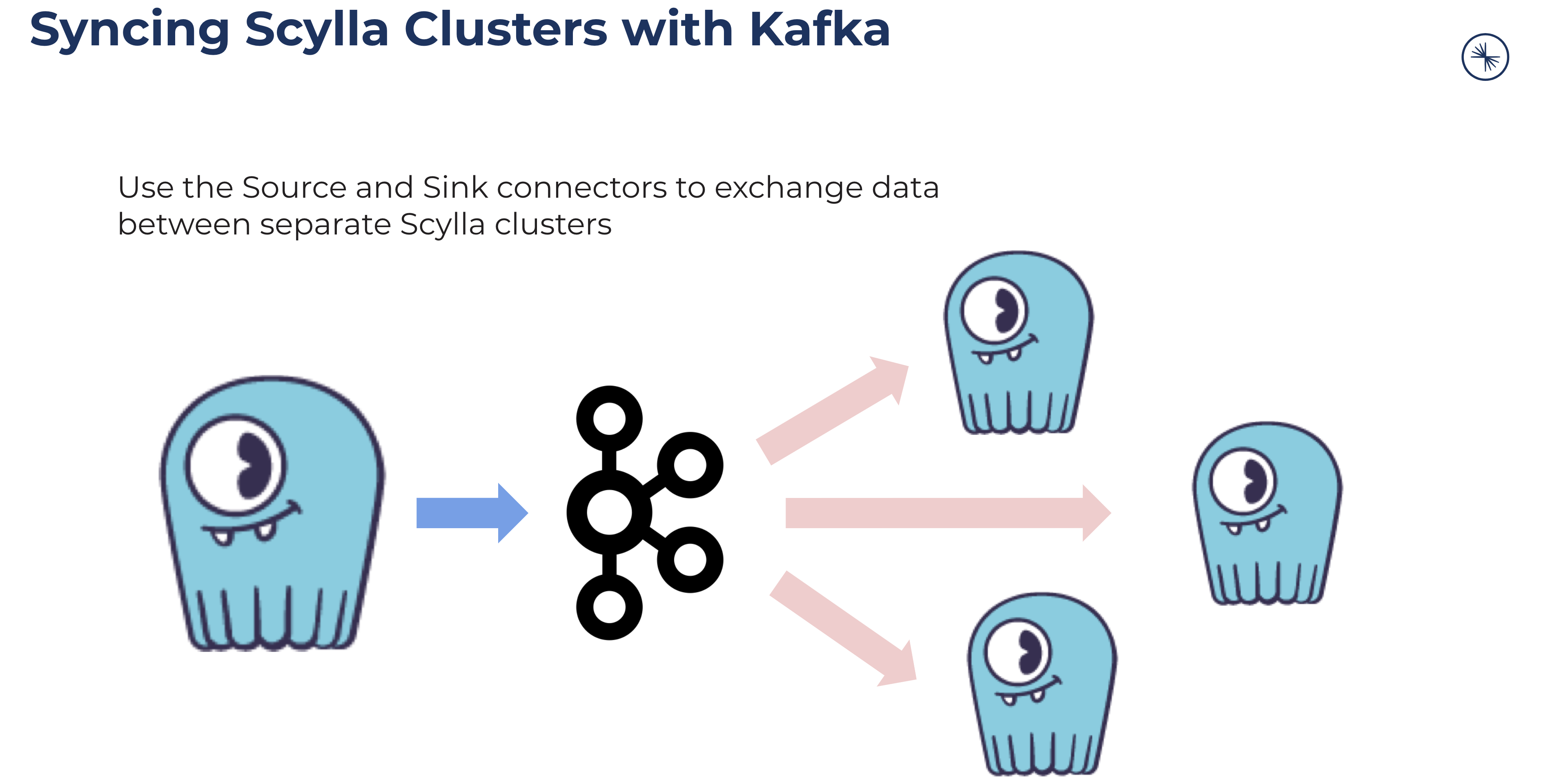
“So here’s that simple pipeline use case. I’ve got the big cluster over there on the left. I will CDC Source Connect that into topics in my Confluent Cloud cluster or my local Kafka cluster. Then I can sink those into other clusters.”
Tim noted this wouldn’t replace Scylla’s built-in multi-datacenter replication capabilities. “You wouldn’t use this for solving a multi-region connectivity problem. It’s more you want to think of this as a data integration tool. I’ve got a cluster here and there are some tables in there, that I have things happening, and I want them to happen in that different cluster over there also. You can use Kafka as that kind of integration pipeline.”
While users could write that sort of code for themselves, “the nice thing about doing this with Kafka is you get all the scaling properties of Kafka Connect, the scaling properties of Kafka itself, the durability of the log and, as always happens when you’ve got a pipeline, it starts dumb and then it realizes it needs to be smart and so you need to start layering in stream processing in the middle.”
Configuring Scylla and Kafka Connect
Tim then walked through the steps to setup a Scylla table with CDC, populate it, and read the results from the related CDC table. First he set up a simple keyspace ks.
Then he created within that the base table ks.t, that enables CDC by ending the CQL statement WITH cdc = { 'enabled' = true}.

“It’s got a primary key and a couple of columns and I’m enabling CDC — that magical Scylla feature where it just does all the work for me and I don’t even say thank you. It just does it and asks for nothing in return.”
Tim then showed a typical configuration for the Scylla CDC Source Connector, which only ran 16 lines long.
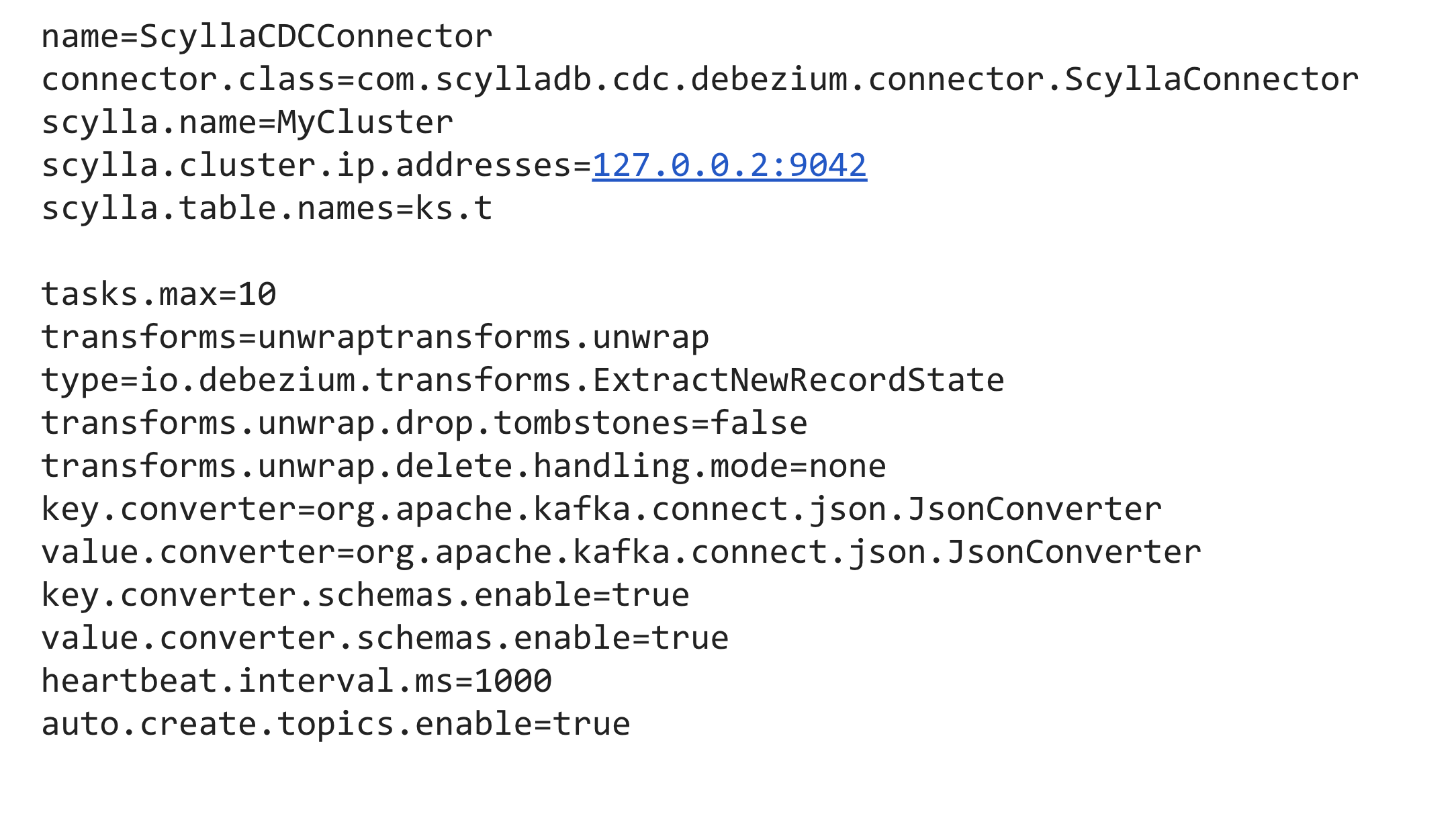 He noted “this is not intended for you to memorize, but I want you to have this just get your eyes on this. This is the basic size of the configuration stuff you have to throw at the connector. Connectors are declarative. That’s the whole point of Kafka connectors. You’re not writing the connector code — somebody’s done that for you. But you do have to configure. So you deploy the connector and you throw some config at it.”
He noted “this is not intended for you to memorize, but I want you to have this just get your eyes on this. This is the basic size of the configuration stuff you have to throw at the connector. Connectors are declarative. That’s the whole point of Kafka connectors. You’re not writing the connector code — somebody’s done that for you. But you do have to configure. So you deploy the connector and you throw some config at it.”
“Normally in a distributed mode, this would be a little piece of JSON. But this is a super easy way to read it. It fits on the slide nicely. Post that little piece of json to a REST endpoint. That connector would wake up and start doing its thing.”
“Now then, of course, you’d want to insert some data,” ironically Tim noted the simplicity of the example, “Scylla is a radically scalable NoSQL database so we’re going to throw two rows at it.”

“Then we get to look at what’s happening in the CDC log. You see the stream ID, a timestamp, sequence number, is it a delete and then the actual changes that happened. In this case, those insert mutations being captured in the CDC log.”
“Of course, the connector is reading these rows directly. We don’t ever need to see these rows because the connector queries them for us. What we see is JSON that shows up in our topic.”

Tim noted it could be transformed into any of Kafka’s other supported data formats. “We could make it protobuf. We could make it Avro. You could make it comma separated values if you just want to watch the world burn — you know that’s an option. But it is automatically now deposited in your topic as a JSON message describing the change that has happened. You’ve got this change log built in Kafka with just about no effort at all.”
Get Started with Scylla and Confluent Today
Tim noted that as of the time of his speaking (June 17, 2021) the Scylla CDC Source Connector only supported the deltas, and that future versions would support the pre-image and post-image data. If you are interested in learning about the open issues, future plans and latest changes, you can follow the project in Github.
Tim also invited the audience to learn Kafka at https://developer.confluent.io/. Similarly, we’d love to invite you to sign up for our free online Scylla University.
If the combined capabilities of Scylla and Confluent have piqued your interest, or if the use cases presented by our friends at Numberly have sparked your imagination for what you can do with your own big data, there’s no time like the present to get started.
- Get Scylla — If this is the first time you’ve ever tried your hand at Scylla you have two options. If you’re a self-starter that would love to run it in your own laptop via Docker to learn how it works, you can download Scylla Open Source. Or if you wish to have professional support and prefer we set up and manage the cluster for you, feel free to create an account on Scylla Cloud.
- Get the Confluent Platform — similarly you can get started on the Confluent Platform or Confluent Cloud. Kafka Connect is included as a component.
- Get the Scylla Kafka Connectors — To get these systems to play together, head straight to the Confluent Hub where, depending on your needs, you can download the Scylla Sink Connector, or the Scylla CDC Source Connector for Kafka, or both!
- Download a Shard-Aware Driver — To noodle around with Scylla itself, outside of the Kafka Connect context, you’ll probably want a Scylla shard-aware driver. Fortunately, we have a number of them, as well as a list of other 3rd party CQL-compatible drivers.
Lastly, if you want to get some great hands-on experience, we have a full, free, instructor-led session on using Scylla and Kafka at the upcoming Scylla University LIVE Summer School, held this July 28-29th, with separate schedules for EMEA/APAC and the Americas. Sign up for a seat!