Real-Time Machine Learning with ScyllaDB as a Feature Store
What ML feature stores require and how ScyllaDB fits in as fast, scalable online feature store
In this blog post, we’ll explore the role of feature stores in real-time machine learning (ML) applications and why ScyllaDB is a strong choice for online feature serving. We’ll cover the basics of features, how feature stores work, their benefits, the different workload requirements, and how latency plays a critical role in ML applications. We’ll wrap up by looking at popular feature store frameworks like Feast and how to get started with ScyllaDB as your online feature store.
What is a feature in machine learning?
A feature is a measurable property used to train or serve a machine learning model. Features can be raw data points or engineered values derived from the raw data. For instance, in a social media app like ShareChat, features might include:
- Number of likes in the last 10 minutes
- Number of shares over the past 7 days
- Topic of the post
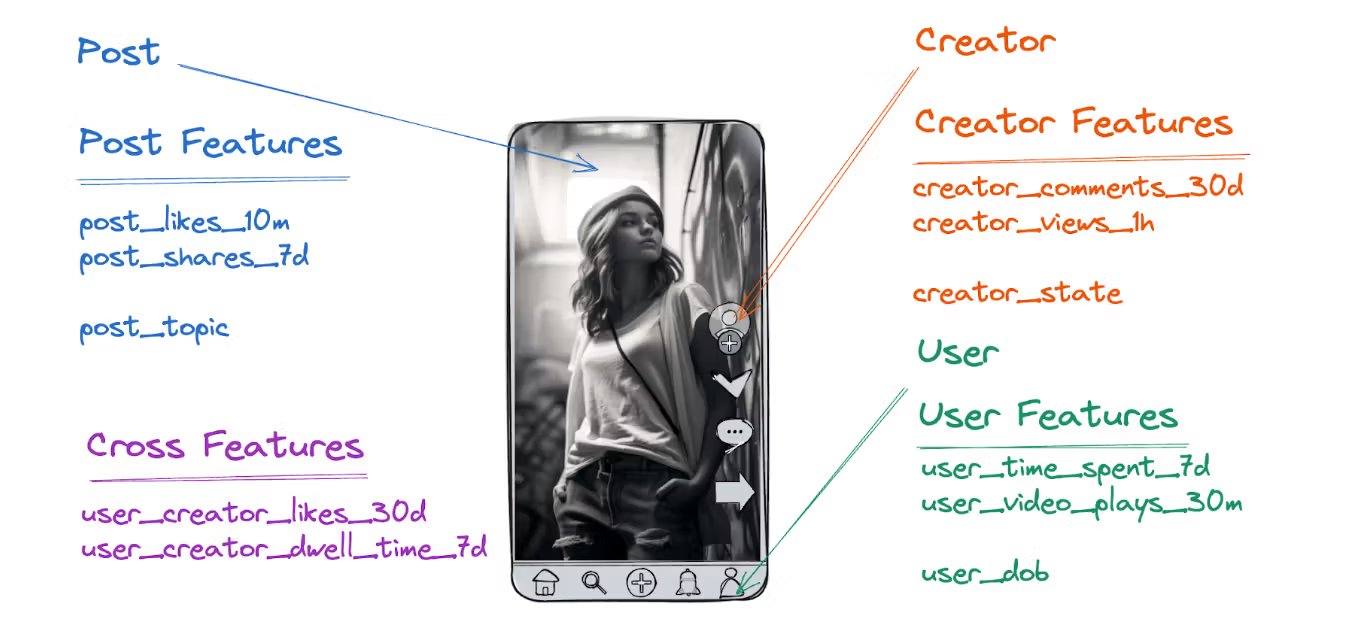
Image credit: Ivan Burmistrov and Andrei Manakov (ShareChat)
These data points help predict outcomes such as user engagement or content recommendation.
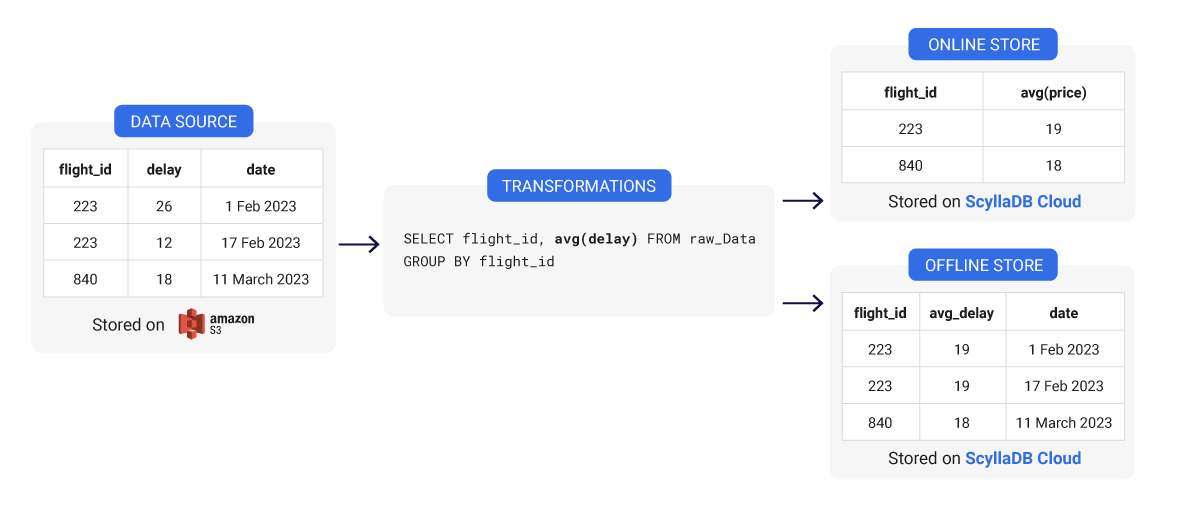
A feature vector is simply a collection of features related to a specific prediction task. For example, this is what a feature vector could look like for a credit scoring application.
| zipcode | person_age | person_income | loan_amount | loan_int_rate (%) |
|---|---|---|---|---|
| 94109 | 25 | 120000 | 10000 | 12 |
Selecting relevant data points and transforming them into features takes up a significant portion of the work in machine learning projects. It is also an ongoing process to refine and optimize features so the model being trained becomes more accurate over time.
Feature store architectures
In order to efficiently work with features, you can create a central place to manage the features that are available within your organization. A central feature store enables:
- A standard process to create new features
- Storage of features for simplified access
- Discovery and reuse of features across teams
- Serving features for both model training and inference
Most architectures distinguish between two stores/databases:
- Offline store for model training (bulk writes/reads)
- Online store for inference (real-time, low-latency writes/reads)
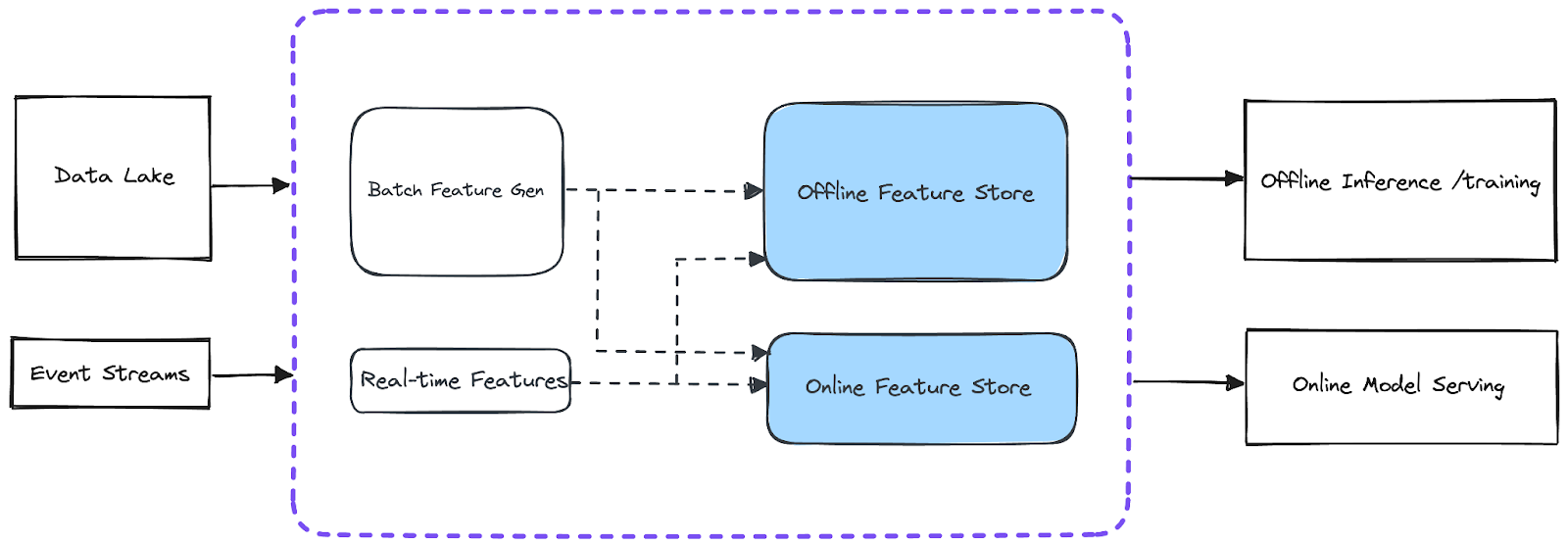
A typical feature store pipeline starts with ingesting raw data (from data lakes or streams), performing feature engineering, saving features in both stores, and then serving them through two separate pipelines: one for training and one for inference.
Benefits of a centralized feature store
Centralized feature stores offer several advantages:
- Avoid duplication: teams can reuse existing features
- Self-serve access: data scientists can generate and query features independently
- Unified pipelines: even though training and inference workloads are vastly different, they can still be queried using the same abstraction layer
This results in faster iteration, more consistency, and better collaboration across ML workflows.
Different workloads in feature stores
Let’s break down the two very distinct workload requirements that exist within a feature store: model training and real-time inference.
1. Model training (offline store)
In order to make predictions you need to train a machine learning model first. Training requires a large and high-quality dataset. You can store this dataset in an offline feature store. Here’s a run down of what characteristics matter most for model training workloads:
- Latency: Not a priority
- Volume: High (millions to billions of records)
- Frequency: Infrequent, scheduled jobs
- Purpose: Retrieve a large chunk of historical data
Basically, offline stores need to efficiently store huge datasets.
2. Real-time inference (online store)
Once you have a model ready, you can run real-time inference. Real-time inference takes the input provided by the user and turns it into a prediction. Here’s a look at what characteristics matter most for real-time inference:
- Latency: High priority
- Volume: Low per request but high throughput (up to millions of operations/second)
- Frequency: Constant, triggered by user actions (e.g. ordering food)
- Purpose: Serve up-to-date features for making predictions quickly
For example, consider a food delivery app. The user’s recent cart contents, age, and location might be turned into features and used instantly to recommend other items to purchase. This would require real-time inference – and latency makes or breaks the user experience.
Why latency matters
Latency (in the context of this article) refers to the time between sending a query and receiving the response from the feature store. For real-time ML applications – especially user-facing ones– low latency is critical for success.
Imagine a user at checkout being shown related food items. If this suggestion takes too long to load due to a slow online store, the opportunity is lost. The end-to-end flow from
- Ingesting the latest data
- Querying relevant features
- Running inference
- Returning a prediction
must happen in milliseconds.

Choosing a feature store solution
Once you decide to build a feature store, you’ll quickly find that there are dozens of frameworks and providers, both open source and commercial, to choose from:
- Feast (open source): Provides flexible database support (e.g., Postgres, Redis, Cassandra, ScyllaDB)
- Hopsworks: Tightly coupled with its own ecosystem
- AWS SageMaker: Tied to the AWS stack (e.g., S3, DynamoDB)
- And lots of others
Which one is best? Factors like your team’s technical expertise, latency requirements, and required integrations with your existing stack all play a role. There’s no one-size-fits-all solution.
If you are worried about the scalability and performance of your online feature store, then database flexibility should be a key consideration. There are feature stores (e.g. AWS SageMaker, GCP Vertex, Hopsworks etc.) that provide their own database technology as the online store. On one hand, this might be convenient to get started because everything is handled by one provider. But this can also become a problem later on.
Imagine choosing a vendor like this with a strict P99 latency requirement (e.g., <15ms P99). The requirement is successfully met during the proof of concept (POC). But later you experience latency spikes – maybe because your requirements change or there’s a surge of new users in your app or some other unpredictable reason. You want to switch to a different online store database backend to save costs.
The problem is you cannot… at least not easily. You are stuck with the built-in solution. It’s unfeasible to migrate off just the online store part of your architecture because everything is locked in.
If you want to avoid these situations, you can look into tools that are flexible regarding the offline and online store backend. Tools like Feast or FeatureForm allow you to bring your own database backend, both for the online and offline stores. This is a great way to avoid vendor lock-in and make future database migrations less painful in case latency spikes occur or costs rise.
ScyllaDB as an online feature store
ScyllaDB is a high-performance NoSQL database that’s API compatible with Apache Cassandra and DynamoDB API. It’s implemented in C++, uses a shard-per-core architecture, and includes an embedded cache system, making it ideal for low-latency, high-throughput feature store applications.
Why ScyllaDB?
- Low latency (single-digit millisecond P99 performance)
- High availability and resilience
- High throughput at scale (petabyte-scale deployments)
- No vendor lock-in (runs on-prem or in any cloud)
- Drop-in replacement for existing Cassandra/DynamoDB setups
- Easy migration from other NoSQL databases (Cassandra, DynamoDB, MongoDB, etc)
- Integration with the feature store framework Feast
ScyllaDB shines in online feature store use cases where real-time performance, availability, and latency predictability are critical.
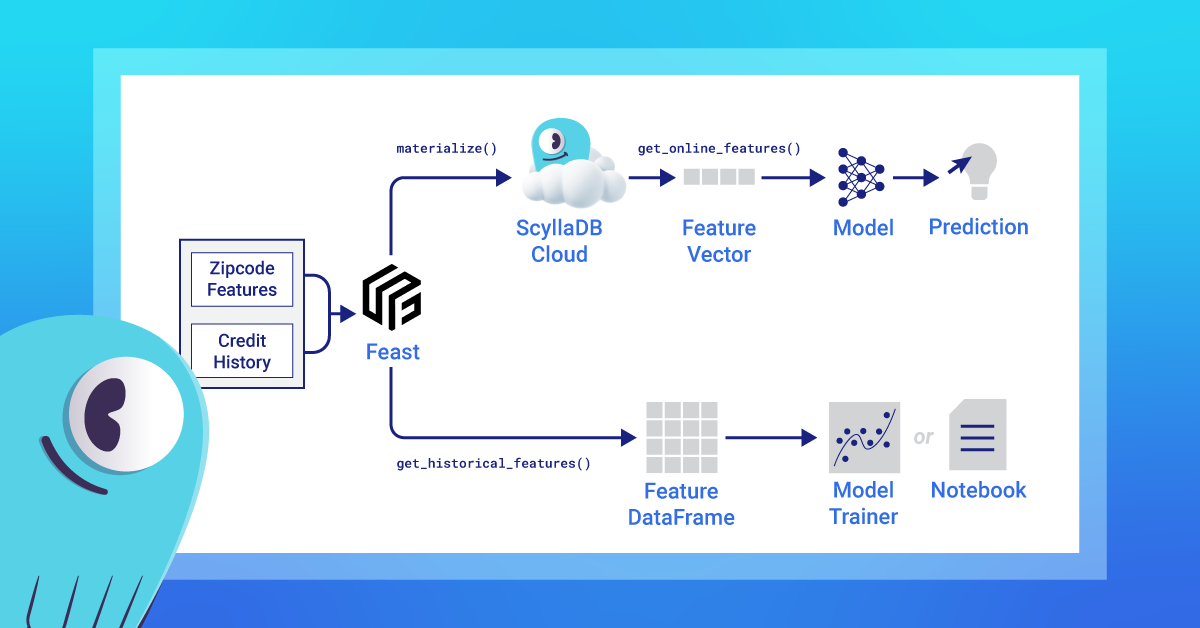
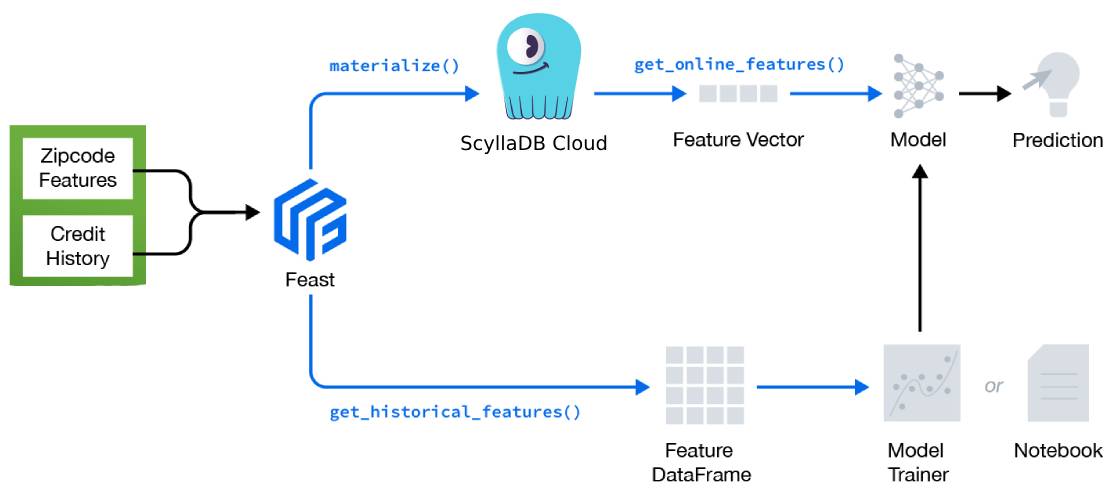
ScyllaDB + Feast integration
Feast is a popular open-source feature store framework that supports both online and offline stores. One of its strengths is the ability to plug in your own database sources, including ScyllaDB. Read more about the ScyllaDB + Feast integration in the docs.
Get started with a feature store tutorial
Want to try using ScyllaDB as your online feature store? Check out our tutorials that walk you through the process of creating a ScyllaDB cluster and building a real-time inference application.
Tutorial: Price prediction inference app with ScyllaDB
Tutorial: Real-time app with Feast & ScyllaDB
Feast + ScyllaDB integration
GitHub: ScyllaDB as a feature store code examples
Have questions or want help setting it up? Submit a post in the forum!