Getting the Most out of Lightweight Transactions in ScyllaDB
![]()
This article was published in 2020
Lightweight transactions (abbreviated as LWT) appeared in Cassandra back in 2012 when it was a revolutionary feature. Since that time we have seen various comparable implementations in other NoSQL databases and a new protocol for consensus, Raft. So how is Scylla adding LWT now relevant to you?
Well, for one, Cassandra’s implementation of LWT hasn’t necessarily worked as intended. There are many issues with the implementation the Cassandra team has admitted they won’t fix. As well, Cassandra requires four round trips to process each query using LWT, which generally causes poor performance and can throw timeout exceptions.
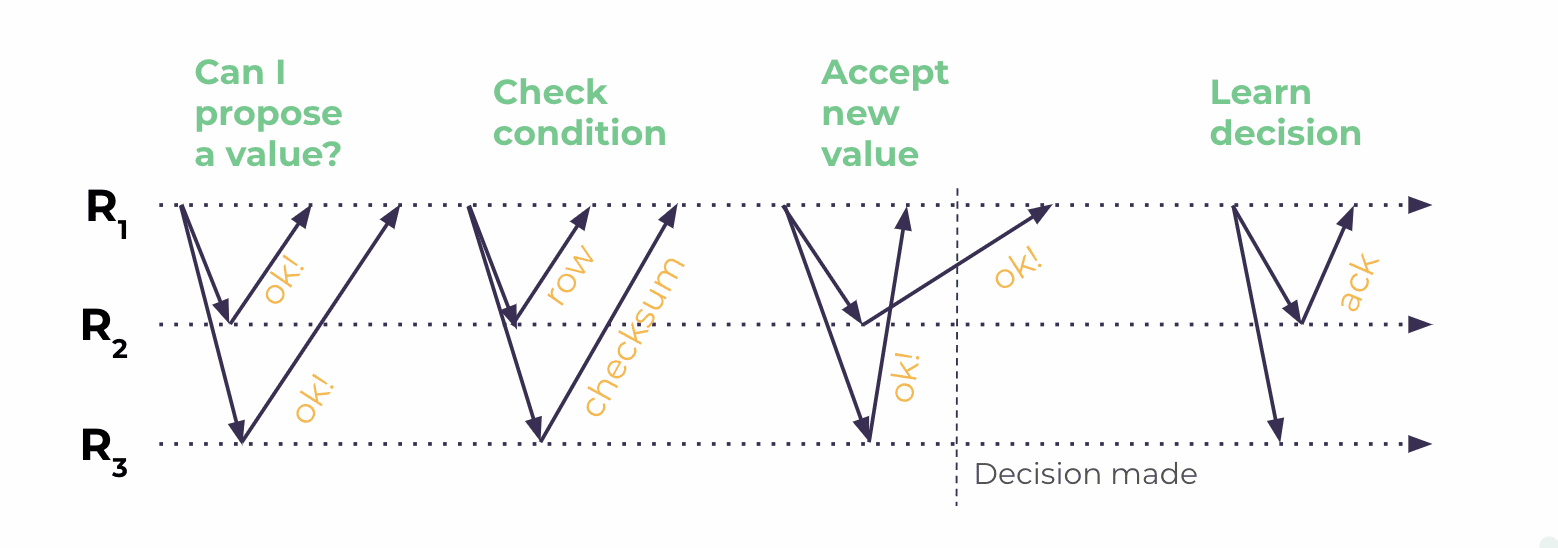
Cassandra’s implementation of LWT requires four round trips to conduct a single transaction.
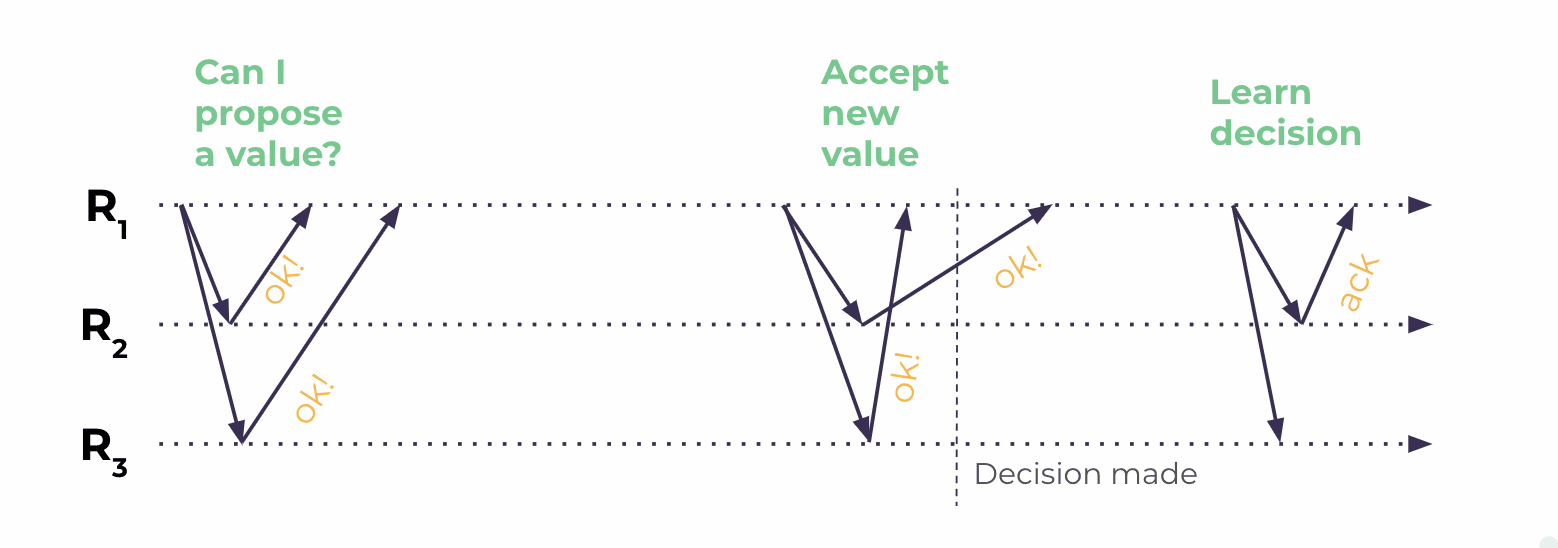
Scylla’s implementation of LWT requires only three round trips, making it more efficient than Cassandra’s LWT.
We believe we solved how to do LWTs far more efficiently in Scylla. If you have been using Cassandra’s LWTs as-is, you may find performance under Scylla to be a breath of fresh air. If you avoided using LWTs because of poor performance, you may want to reconsider them now.
Lightweight transactions in Scylla are not just for the sake of Cassandra compatibility. Our product has its own unique voice with focus on performance, observability and also — versatility. SERIAL mode is the backbone of Scylla’s DynamoDB compatible interface, known as Alternator, and will serve internally as a building block for many upcoming features.
What is a Lightweight Transaction?
While users familiar with Apache Cassandra may be familiar with the term, let’s make sure to define what a “lightweight transaction” is so we’re all on the same page. In a traditional SQL RDBMS a “transaction” is a logical unit of work — a group of tasks. It comes along with an entire set of expectations, which have become known as ACID properties. In Scylla, as in Cassandra, lightweight transactions are limited to a single conditional statement, which allows an “atomic compare and set” operation. That is, it checks if a condition is true, and if so, it conducts the transaction. If the condition is not met, the transaction does not go through.
They were called “lightweight” since they do not truly lock the database for the transaction. Instead, it uses a consensus protocol, in this case Paxos, to ensure there is agreement between the nodes to commit the change.
While there are many long discussions on whether LWTs for Cassandra and Scylla make them a “true” ACID-compliant database, for a user, the most important thing is the capacity to do conditional updates. And that is what we will focus on in this blog post.
A Practical Example: An LWT Banking App
Is transaction support necessary when working with Scylla? After all, Scylla QUORUM writes are pretty durable, and QUORUM reads guarantee monotonicity.
Let’s take a look at an example. Rumour has it, ACID transactions are required for financial applications, so I’ll write a small banking application if only to see if it’s true or not. Besides, many apps for businesses with lower regulatory demands have a similar data model: a cryptocurrency exchange, an online game, a mobile operator customer portal. My application will be extremely scalable: both in transactions per second and the number of client accounts.
At the core of the app will reside an account ledger — a registry of accounts of all existing clients and all of the transactions associated with each account. It can be difficult to partition horizontally, since no matter how it is partitioned, most transactions will require changes at multiple database nodes:
CREATE TABLE lightest.accounts (
bic TEXT, -- bank identifier code
ban TEXT, -- bank account number within the bank
balance DECIMAL, -- account balance
pending_transfer UUID, -- will be used later
pending_amount DECIMAL, -- will be used later
PRIMARY KEY((bic, ban))
)As you can see, I chose to partition the ledger by both Bank Identification Code (BIC) and Bank Account Number (BAN) — bank and account identifiers. I could have chosen the bank identifier alone. The choice impacts the ratio of transfers which use a single partition, and thus require a single lightweight transaction, vs transfers between partitions, possibly residing on different data nodes, which require multiple lightweight transactions.
The fewer columns are used in a partition key, the larger each partition can become. Scylla isn’t particularly in love with oversized partitions, since they can lead to imbalance in load distribution among shards. Lightweight transactions don’t play well with them either. When a partition is highly contended (i.e. used by a lot of concurrent requests) a statement may have to retry to obtain a quorum of promises. Even with small partitions the real world transactions may surprise us, e.g. a single player or organization may participate in most transactions, and thus become a hotspot. I’ll try to look into this scenario as well, by generating an appropriate transaction distribution. This will highlight some dark corners of LWT design.
The supporting code for the app is available at https://github.com/kostja/lightest. It’s a Go app, and I chose Go for its excellent support for concurrency. It is also using Scylla’s shard-aware GoCQL driver, which performs much better for any kind of Scylla workload, including LWT. Whatever you tell lightest to do it will do using a lot of workers — as many workers as there are cores, multiplied by four. lightest aims at being close to a real world workload, part of which is using a normal random distribution for the data and queries it generates. The central test implemented by lightest is money transfers between two accounts, especially if they reside on different partitions. But I will begin with some simpler tests.
First, let’s populate the ledger by registering accounts. To register an account lightest uses the following conditional insert:
INSERT INTO accounts (bic, ban, balance, pending_amount)
VALUES (?, ?, ?, 0) IF NOT EXISTSThe words IF NOT EXISTS make this command different from a standard tunable consistency insert. Before such insert is applied, Scylla reads existing data and evaluates a condition against it, in our case, checks if the row is not yet present. This ensures that an existing row is never overwritten. If you’re curious why the standard INSERT doesn’t behave in the same way, please watch my talk at the Scylla Summit, where I discuss how eventual consistency complements log structured merge trees to provide best write throughput.
IF clause is the magic phrase which makes this statement conditional. That’s why lightweight transactions are also known as conditional statements. The latter name I personally find more telling since, as it will be seen, a lightweight transaction isn’t that lightweight after all. But they are powerful enough, and also massively scalable, as you can see if you check lightest pop(ulate) output (which I am running here on 3 AWS EC2 i3.8xlarge machines):
$ ./lightest pop --host db1 -n 1000000
Creating 1000000 accounts using 384 workers on 96 cores
0.76% done, RPS 7577, Latency min/max/med: 0.002s/0.141s/0.013s
3.11% done, RPS 23562, Latency min/max/med: 0.002s/0.119s/0.010s
…
99.98% done, RPS 676, Latency min/max/med: 0.002s/0.026s/0.002s
100.00% done, RPS 174, Latency min/max/med: 0.002s/0.003s/0.002s
Inserted 1000000 accounts, 13 errors, 1637283 duplicates
Total time: 122.042s, 8193 inserts/secWe can get more work done if we increase the number of workers:
$ ./lightest pop --host db1 -n 1000000 -w 2000
Creating 1000000 accounts using 2000 workers on 96 cores
0.74% done, RPS 7401, Latency min/max/med: 0.002s/0.186s/0.026s
7.30% done, RPS 65647, Latency min/max/med: 0.003s/0.150s/0.024s
...The key difference between conditional and standard statements is that conditional statements implement more natural semantics: despite a huge number of workers, if a record is already present in the database, it’s not re-inserted. This semantic is an example of what is known as being linearizable.
Linearizability means being able to process requests in a strict sequential order. Basically, Scylla takes a stream of concurrent writes and orders it into a single sequential history. Which is important, because you have to check the conditions are true and complete each request before beginning processing the next; otherwise underlying data may change (and thus the condition no longer be true). This is also why client statement timestamps are not permitted in conditional statements: each write gets a unique server timestamp which is automatically assigned when/if the write is actually stored.
Dealing with Failure
The client has a way to find out if a statement is not applied because the associated condition was false:
cqlsh:lightest> INSERT INTO accounts (bic, ban, balance, pending_transfer) VALUES (...) IF NOT EXISTS;
[applied] | bic | ban | balance | pending_amount | pending_transfer
-----------+-----+-----+---------+----------------+------------------
False | ... | ... | 0 | null | nullDuring population, my goal is to insert a lot of random accounts, which are then used to perform payments. I’d like to avoid having to load the accounts from the database during the payment workload, so instead I save the pseudo-random generator seed, which is then reused during payments to generate the same pseudo-random data. This approach has a caveat: since populate runs with hundreds of workers, all using the same seed, a chance of collision on account identifier is quite high. The collision rate gets even higher as we approach the end of the benchmark, since all workers choose their pseudo-random account numbers from a finite set.
As you can observe in lightest output, thanks to deduplication of concurrent inserts, there were more queries than inserted rows, and the transaction throughput fell significantly towards the end of the test. The number of skipped statements is present in the LWT dashboard for Scylla Monitoring Stack, a chart for cas_condition_not_met:
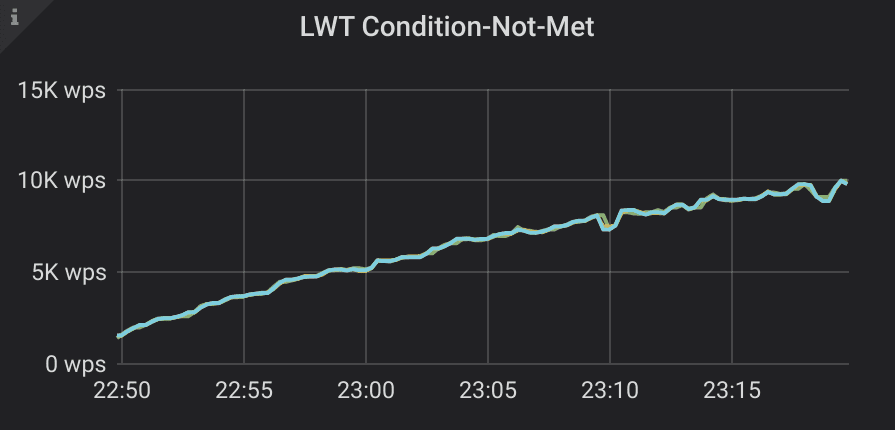
OK, it’s clear that we need to try another account, if we get a duplicate key error, but what shall we do if we get an error? Should we retry with the current or a new account?
People are used to transactions having either of the two outcomes: success or failure. The case of failure is hard to come by in a staged setting and there is a strong temptation to ignore it.
To simulate potential real-world errors, when running my test I tweaked the cluster by sending STOP and CONTINUE signals to server processes. Database users commonly think errors have no impact, i.e. do not change the database state. Indeed, aren’t we using transactions to achieve atomic, all or nothing semantics?
query failure != transaction failure
A common misconception coming from using non-distributed databases is that a failure always has to mean a transaction failure, which in turn always ends with a transaction rollback. For an embedded database like SQLite, error of any other type has no occasion to happen. Even for most popular client-server databases like MySQL or PostgreSQL, a connection failure after a transaction commit is an extremely rare event, so applications simply ignore it.
Scylla, as a distributed database, executes a transaction at multiple nodes, some of which are allowed to fail. With CL=SERIAL, just like with CL=QUORUM, as long as the majority of replicas succeed, the transaction is committed even if the node which initiated the transaction fails. A failure doesn’t have to be even a node crash or network error: the client query can simply time out.
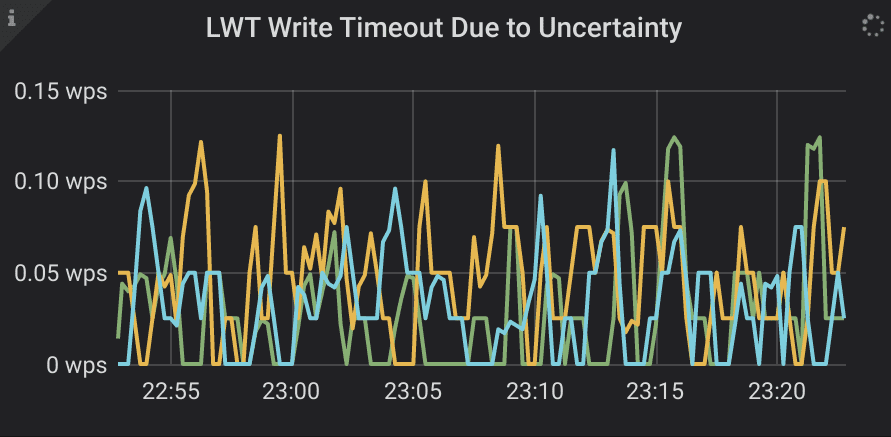
lightest is well aware of this property. When an INSERT fails, be it because of a timeout, lack of quorum, or contention, lightest re-tries, and a retry can then fail, apply, or find an existing record. Luckily, IF predicate makes the LWT statement safe to retry. As a result, some of the failures actually stand for successful account registrations, and re-tries of these transactions do not satisfy IF condition and thus do not apply.
Note: if the statement condition doesn’t become false after a statement is applied, re-trying it may lead to double apply. In such cases instead of re-trying, one can read the latest data back, and check if it is actually updated. SELECT statement then must use SERIAL consistency level, to guarantee it returns the most recently committed data. Scylla made an effort to make SERIAL SELECTs really linearizable, having fixed issue CASSANDRA-12126, still open in Cassandra.
Let’s check how much overhead SERIAL consistency incurs by running lightest populate with QUORUM consistency:
$ ./lightest pop --host db1 -n 3000000 -c QUORUM -w 8000
Creating 3000000 accounts using 8000 workers on 96 cores
1.70% done, RPS 51048, Latency min/max/med: 0.000s/0.415s/0.002s
11.30% done, RPS 287915, Latency min/max/med: 0.000s/0.045s/0.001s
..
Inserted 3000000 accounts, 0 errors, 0 duplicates
Total time: 19.766s, 151774 t/sec
Latency min/max/avg: 0.000s/0.415s/0.002s
Latency 95/99/99.9%: 0.007s/0.025s/0.180sThe throughput is nearly 4x! Where is the LWT overhead coming from?
The way Paxos achieves many of its properties is by introducing a concept of a ballot – an effectively unique identifier associated with each transaction. In Scylla, a ballot is a 128-bit UUID based on 64-bit clock reading, a random bit sequence and the machine id. This makes all ballots unique and chronologically orderable. Paxos ballots are tracked independently for each partition key. It is both a strength and a weakness: absence of coordination between transactions against different partitions increases the overall throughput and availability, but provides no mutual order, so transactions cannot span across partitions.
Ballots, as well as other protocol state, are stored in a local system table, system.paxos at all replicas. When a transaction is complete, most of this state is pruned away. If a transaction fails mid-way, however, the state is kept for gc_grace_seconds (set to 10 days by default), and DBAs are expected to run nodetool repair before it expires.
The node which is performing the transaction, also known as the coordinator, begins by creating a new ballot and asking the nodes owning data for the respective token range to store it. Replicas refuse to store the ballot if it is older than the one they already know, while the coordinator refuses to proceed if it doesn’t have a majority of responses from replicas. This majority rule ensures only a single transaction is modifying the data at a time, and that the coordinator gets up to date with the most recent changes before it suggests a new one. Remember I mentioned that an LWT statement first reads the data from the table, and only then executes an update? So Scylla actually does two things at the same time: reads the conditioned row from the majority of replicas, and, by storing the ballot, extracts a promise from replicas to accept a new value only from a higher ballot (not from a lower ballot) when/if it comes along.
After the coordinator gets a majority of promises to accept a new value, it evaluates the lightweight transaction condition and sends a new row to replicas. Finally, when a majority of replicas accept and persist the new row in their system.paxos table, the coordinator instructs them to apply the change to the base table. At any point some of the replicas may fail, and even in absence of failure replicas may refuse a ballot because they have made a promise to a different coordinator. In all such cases the coordinator retries, possibly with a new ballot. After all steps are complete, the coordinator requests the participants to prune system.paxos from intermediate protocol state. The pruning is done as a background task.
In total, Scylla performs 3 foreground and 1 background write for each Paxos transaction at each replica. While this is better than the current Cassandra implementation (here’s a good summary of differences between Scylla and Cassandra), it is still 4x more than an average QUORUM write. What’s more, each LWT write in Scylla flushes the commit log to disk, regardless of the commitlog_sync setting, to ensure LWT writes are truly durable.
Why does Scylla have to make all these rounds? Isn’t it possible to reduce the algorithm to a single round per transaction on average? Let’s look at why each phase is important.
- Step 1, the prepare phase, is necessary to ensure there is only one coordinator making the change. We could avoid selecting a coordinator independently for each transaction. However, it would require maintaining a record of the current leader for each partition key, which is a lot of additional metadata. On the positive side, Scylla LWT availability does not depend on a single leader, and node failures have low impact on cluster availability.
- Step 2, storing the interim result in system.paxos is necessary to work well with eventually consistent reads and writes. Scylla can’t assume people will not be using
QUORUMreads and writes of the same data along with LWT, even though it’s not recommended. So a transaction should not be visible for these until it’s committed, and this is why it’s first made durable insystem.paxos. We could have avoided this step by not permitting eventually consistent and conditional writes of the same data. That would break compatibility with Cassandra, so we decided not to do it. Cassandra perhaps followed the same reasoning originally and wanted to simplify adoption of lightweight transactions in existing eventually consistent apps. - Step 3 moves the data from
system.paxosto the base table after a transaction is known to have succeeded. This one can’t be avoided
- Step 4, the pruning step, is distinct to Scylla. We’ve heard a lot of complaints from Cassandra users that
system.paxoscan grow out of control. There are no nodetool operations for repairing or pruning LWT state, so at least we make an effort to keep it small. Besides, keepingsystem.paxossmall reduces its write amplification during compaction, and hence speeds up LWT performance quite a bit.
But let’s continue with the banking application. Not only INSERTSs, but also UPDATEs and DELETEs support conditions. I will jump right to the core of my app, making a stab at implementing a money transfer between two accounts.
A transfer, naturally, needs to subtract an amount from the source account and add it to the destination account. The transaction shouldn’t proceed if the source account would be overdrawn — even if it is debited concurrently. A transfer must never be partial — if we debit the source, we must ensure we credit the destination. Finally, the application has to deal with failures, i.e. retry on error. Let me sum this up. A transfer routine must:
- never lead to an overdraft; the client should get an error about possible overdraft
- change source and destination accounts atomically
- be safe to re-try, for example, re-trying should be a no-op if the transfer is already done.
One could observe that with a classical ACID transaction an atomic transfer procedure would seem to be trivial to write:
BEGIN
UPDATE accounts
WHERE bic=$bic AND ban=$src_ban
SET balance = $balance - $amount
UPDATE accounts
WHERE bic=$bic AND ban=$dst_ban
SET balance = balance + $amount
COMMIT (*)Note: one would still need to take care of a possible overdraft and, more importantly, making the transaction safe to re-try. The default transaction isolation level is virtually never SERIAL, so this also has to be taken into account.
In Scylla, since each account resides on its own partition, we’ll need to use multiple conditional statements. It may console you that a real world ledger rarely resides in a single database. Besides, modifying it may require accessing a physical device, like a tape printer, which is hardly aware of the concept of “rollback”. In all such cases wrapping a transfer into a single transaction is impossible as well.
Adding transfer history
The technique to ensure we never make a partial or duplicate transfer despite the transfer procedure consisting of multiple steps is perhaps as old as clay tablets. However I will use a trendy name for it, derived from microservice architecture patterns: “event sourcing.”
Jokes aside, let’s add a history of all transfers, and make sure we register the intent first, to be able to carry out unfinished transfers reliably:
CREATE TABLE lightest.transfers (
transfer_id UUID, -- transfer UUID
src_bic TEXT, -- source bank identification code
src_ban TEXT, -- source bank account number
dst_bic TEXT, -- destination bank identification code
dst_ban TEXT, -- destination bank account number
amount DECIMAL, -- transfer amount
state TEXT, -- 'new', 'locked', 'complete'
client_id UUID, -- the client performing the transfer
PRIMARY KEY (transfer_id)
)With that, to start a transfer it’s enough to add it to the history. It’s now possible to return to the history record any time and retrieve the transfer state. Eventually we may prune the history from completed transfers — just like Paxos algorithm prunes system.paxos from completed lightweight transactions.
INSERT INTO transfers
(transfer_id, src_bic, src_ban, dst_bic, dst_ban, amount, state)
VALUES (?, ?, ?, ?, ?, ?, 'new')
IF NOT EXISTS</codeThanks to using conditions this INSERT satisfies all our requirements: it’s atomic, safe to retry, and, as we’ll see in a second, it doesn’t lead to an overdraft.
Inserting a history record doesn’t guarantee that the transfer is or will ever be carried out: this is why besides the transfer details we have a transfer state column, and the initial state is “new”. If funds are sufficient, which will be known once we fetch the source balance, the algorithm will proceed with the withdrawal, otherwise it’ll cut the party short by changing the state to ‘complete’. Otherwise the state will change to ‘complete’ only when the funds are transferred.
The next step is to change debit and credit accounts. To ensure it’s safe in presence of client failure I’ll make sure all algorithm steps are idempotent – are safe to carry out more than once. A simple trick to make a series of LWT statements idempotent is to condition each next statement on the results of the previous one. This will allow any client to resume a transfer even if the client that started it fails. To avoid multiple clients from working on the same transfer, we will register the client responsible for the transfer in the history:
UPDATE transfers USING TTL 30
SET client_id = ?
WHERE transfer_id = ?
IF amount != NULL AND client_id = NULL</codeThis update is TTLed: as long as the transfer is not being worked on, any client should be able to take it. It ensures the transfer doesn’t deadlock if the client that started it disintegrates. If TTL is set on the original INSERT, it will expire the entire transfer, that’s why I use a separate update. When TTL expires, Scylla will “cover” our UPDATE with a DELETE (also known as a tombstone) which has the same timestamp. Using the original timestamp is a good idea, since it guarantees nothing but the UPDATE itself is erased: if two mutations have the same timestamp, DELETE trumps UPDATE. With LWT, each write gets a unique monotonically growing timestamp, so no other mutation is at risk.
For correctness, we need to guarantee that the transfer procedure never lasts longer than TTL — otherwise two clients could compete for the same transfer. Scylla’s default request timeout is only 1 second. Most modern systems have a functioning NTP daemon, so clock skew is very unlikely to grow beyond 10-15 seconds. Based on this, 30 seconds should be more than enough — but perhaps a larger value could be used in production.
Now we can prepare source and destination accounts, by setting a pending transfer against them:
UPDATE accounts
SET pending_transfer = ?, pending_amount = ?
WHERE bic = ? AND ban = ?
IF balance != NULL AND pending_amount != NULL AND pending_transfer = NULLThe statement does nothing if there is a transfer which is already in progress. Note, the pending amount is actually negative for the debit account, since funds are withdrawn from it.
I use a != NULL check against balance and pending_amount for a couple of reasons:
- It ensures the account is not accidentally created if it doesn’t exist
- In Scylla, it returns back the previous balance and pending amount, which saves one query:
cqlsh:lightest> UPDATE accounts
SET pending_transfer = b22cfef0-9078-11ea-bda5-b306a8f6411c,
pending_amount = -24.12
WHERE bic = 'DCCDIN51' AND ban = '30000000000000'
IF balance != NULL AND pending_amount != NULL
AND pending_transfer = NULL;
[applied] | balance | pending_amount | pending_transfer
----------+---------+----------------+------------------
True | 42716 | 0 | nullNotice the change in the output when I run the same query one more time:
cqlsh:lightest> UPDATE accounts
SET pending_transfer = b22cfef0-9078-11ea-bda5-b306a8f6411c,
pending_amount = -24.12
WHERE bic = 'DCCDIN51' AND ban = '30000000000000'
IF balance != NULL AND pending_amount != NULL
AND pending_transfer = NULL;
[applied] | balance | pending_amount | pending_transfer
----------+---------+----------------+-------------------------------------
False | 42716 | -24.12 | b22cfef0-9078-11ea-bda5-b306a8f6411c(In Cassandra I would have to make a separate SELECT to query these fields after the update above is applied).
This seals the debit and credit accounts from concurrent work. I will touch upon what should be done if any of the two above steps find a competing transfer in a second.
For now let’s see how the transfer is completed if this improvised locking succeeds. First of all, since the locking statement returns the previous row, we can check if the source account has sufficient funds. If not, we could segue to setting the transfer to ‘complete’. Otherwise, we need to prepare for updating the balances:
UPDATE transfers
SET state = 'locked'
WHERE transfer_id = ?
IF amount != NULL AND client_id = ?Notice the same trick with != NULL to not accidentally insert a transfer if it’s already finished and removed. Changing the state to 'locked' helps us avoid moving the money for the same transfer twice if it is resumed after only one of the two statements below succeed:
-- run for both debit and credit accounts
UPDATE accounts
SET pending_amount = 0, balance = ?
WHERE bic = ? AND ban = ?
IF balance != NULL AND pending_transfer = ?If the source account has insufficient funds, or one of the accounts is missing, or any other pre-condition is violated, the above step is skipped. If we resume the transfer after only one of the accounts is modified, we do not debit or credit it twice, the current value of the pending_amount serves as a sentinel. Once both accounts are updated successfully, we can change the transfer state to complete:
UPDATE transfers
SET state = ‘complete’
WHERE transfer_id = ?
IF amount != NULL AND client_id = ?An updated transfer state indicates the money has been moved, so we won’t attempt to do it again if the transfer is resumed after one of the unlocking steps fails:
UPDATE accounts
SET pending_transfer = NULL, pending_amount = 0
WHERE bic = ? AND ban = ?
IF balance != NULL AND pending_transfer = ?Finally, once the transfer has been completed, its record can be removed from the transfer history.
Thanks to the power of lightweight transactions it’s safe to execute each step more than once, as well as repeat all steps as many times as we please, without risking breaking anything.
Error handling
The beauty of idempotency is that error handling is fairly straightforward: in most cases, we can simply retry from the first failed step. For example, if the transfer state is already ‘locked’, we proceed directly to updating the balance, and it’s safe to skip the update if we see the state is ‘complete’.
But what if we find that there is another transfer against one of the accounts, carried out by another client? Normally, we should let it finish, and then try again. All transfer preconditions, such as absence of overdraft, will need to be evaluated again. In a rare case when the client which initiated the transfer is gone (we can always consult with the transfers.client_id cell), we can carry out the transfer on its behalf, after all, this is what the record in the transfer history is for. Repairing an abandoned transfer uses the exact same steps as making our own. Alternatively, we could create a materialized view for abandoned transfers:
CREATE MATERIALIZED VIEW orphaned_transfers AS
SELECT * FROM transfers WHERE client_id=null
PRIMARY KEY (id);… and have a background process finishing them up.
There is one last thing to take care of. When trying to update the accounts table with our transfer UUID we may encounter a conflicting transfer making the exact opposite move: from credit to debit accounts. We mustn’t sleep then, otherwise the two transfers will deadlock. To avoid the situation altogether, lightest reorders the “locking” steps of the algorithm to always update accounts in lexicographical order. This makes sure deadlocks are impossible.
If you’re curious about the nitty-gritty details of deadlock detection and failed transfer recovery, it’s all implemented in lightest. You’re more than welcome to take a look.
- An additional challenge: there is a very improbable race if a transfer takes longer than 30 seconds. Drop me a message to kostja@scylladb.com if you guess what it is.
Let’s run a test workload to see how many transfers per second we could squeeze out of our cluster. This time I filled the database with 100,000,000 accounts, which took me ~90 minutes, mostly because of the high (~62%) fraction of duplicates .
Now let’s make 1,000,000 payments:
$ ./lightest pay -n 1000000 -w 200 --host db1
Total time: 384.056s, 2515 t/sec
Latency min/max/avg: 0.018s/46.906s/0.077s
Latency 95/99/99.9%: 0.120s/0.166s/0.221s
Errors: 0, Retries: 650, Recoveries: 274,
Not found: 41889, Overdraft: 23086The latency is much higher now: a single transfer translates into 8 LWT statements. a huge maximal latency suggests a few clients were racing to lock one or few hot accounts. The retries counter is another indicator of the same.
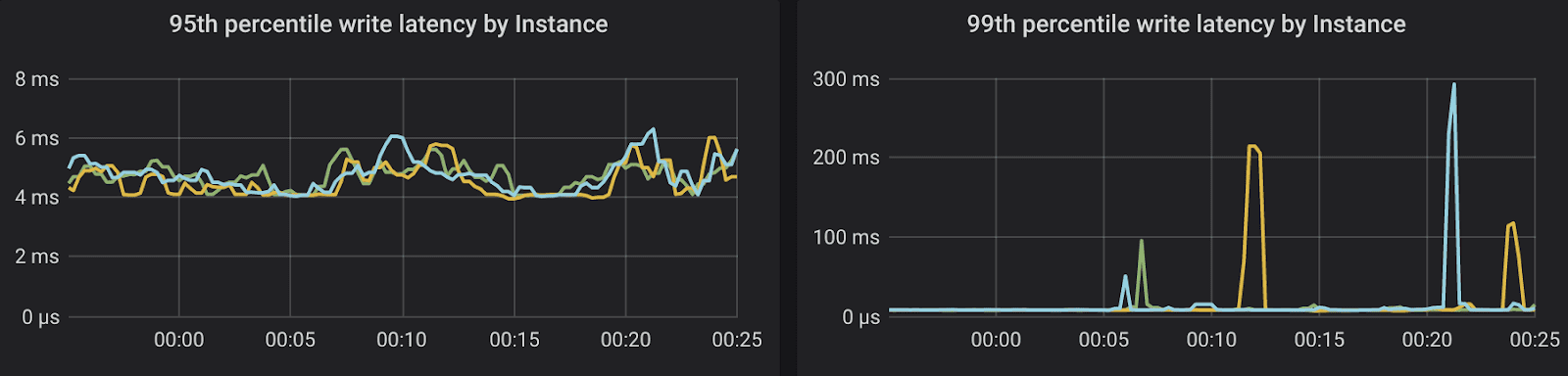
Let’s see how bad it could get if we change the account selection to a Zipfian distribution:
$ ./lightest pay -n 1000000 -w 4000 --host db1 --zipfian
Total time: 1443.835s, 693 t/sec
Latency min/max/avg: 0.009s/1327.792s/3.378s
Latency 95/99/99.9%: 1.072s/64.676s/551.144s
Errors: 0, Retries: 879726, Recoveries: 11150,
Not found: 178461, Overdraft: 19131The results are not pleasing to the eye, but this was the purpose of the exercise. The good part is that our transfer algorithm stands the test of contention and makes steady progress. The bad part is that thanks to a naive retry strategy it could take over 500 seconds to make a transfer for the most contended accounts. We should also be interested in Paxos metrics: how much of a performance penalty did we pay thanks to Paxos internal contention, and how much was it simply because the clients slept between repeating attempts to lock accounts?
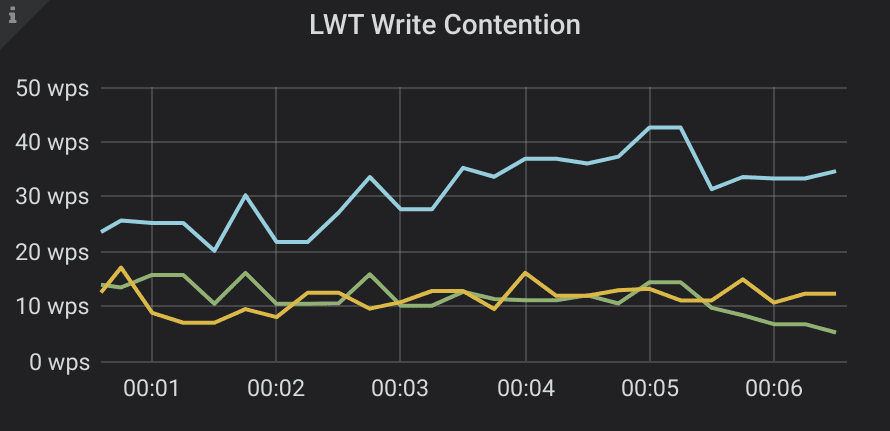
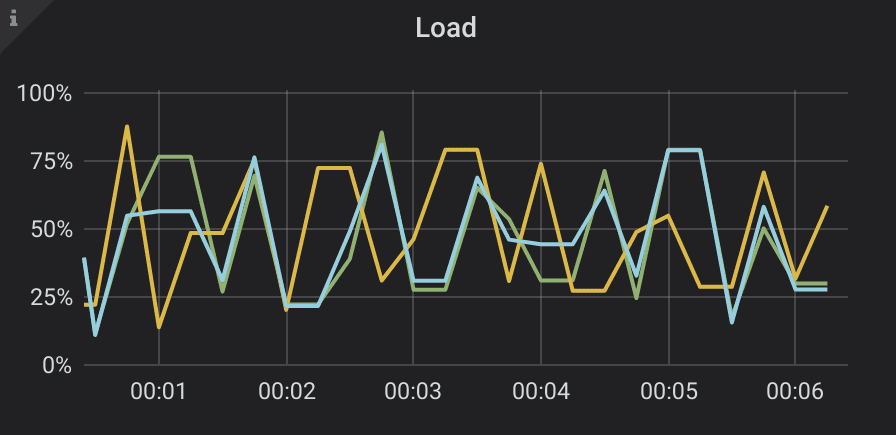
In issue #6259 Scylla extended Cassandra binary protocol to allow the driver to detect conditional statements at prepare, and direct them to the primary replica if it’s available. We also opened a corresponding Cassandra ticket. Additionally, when requests from different clients arrive at the same coordinator, they don’t contend with each other, but wait in a line. These optimizations helped reduce coordinator contention, a very unpleasant artefact of the straightforward Paxos algorithm. While these optimizations significantly improve the worst case performance, LWT is still not the best choice for highly contended workloads. Queued up requests take up memory, and still can timeout and then have to retry. This adds useless work and leads to performance jitter:
Conclusion
Lightweight transactions provide conditional updates through linearizability — a database system property similar to the widely known serializability. While linearizable statements are more expensive and may seem a bit harder to use than statements in classical serializable transactions, they are no less powerful. By using a leader-less architecture for LWT, the Scylla implementation provides unprecedented availability, at the cost of possibly lower throughput. When implementing LWT, Scylla engineering team made an effort to address some of the well known gotchas of Cassandra:
- Consistency of
SELECTstatements - Excessive contention issues and retries
- Uncontrolled growth of the Paxos table.
We also invested in making LWT durable out of the box, and less expensive, to the extent possible without breaking Cassandra semantics.
We also wanted to ensure that LWTs had strong visibility to users. We want you to be able to see how LWTs are impacting your system as you try them out. Scylla Monitoring Stack can be used to track any production issues with LWT.
Apart from high cost, a responsible implementation needs to be careful to not create hotspots.
If you want to provide feedback to us on our implementation of LWTs, please feel free to contact us directly, or drop in our Slack channel, or our email list and let us know what you think.