NoSQL Summer Blockbusters: From Wrangling Rust to HA Trial by Fire

With summer blockbusters returning in full force this year, maybe you’re on a bit of a binge-watching, popcorn-munching kick? If your tastes veer towards the technical, we’ve got a marquee full of on-demand features that will keep you on the edge of your seat:
- Escaping Jurassic NoSQL
- Wrangling Rust
- Daring database engineering feats
- High availability trial by fire
- Breaking up with Apache Cassandra
Here’s an expansive watchlist that crosses genres…
ScyllaDB Engineering
Different I/O Access Methods For Linux, What We Chose For ScyllaDB, And Why
When most server application developers think of I/O, they consider network I/O since most resources these days are accessed over the network: databases, object storage, and other microservices. However, the developer of a database must also consider file I/O.

In this video, ScyllaDB CTO Avi Kivity provides a detailed technical overview of the available choices for I/O access and their various tradeoffs. He then explains why ScyllaDB chose asynchronous direct I/O (AIO/DIO) as the access method for our high-performance low latency database and reviews how that decision has impacted our engineering efforts as well as our product performance.
Avi covers:
- Four choices for accessing files on a Linux server: read/write, mmap, Direct I/O (DIO) read/write, and asynchronous direct I/O (AIO/DIO)
- The tradeoffs among these choices with respect to core characteristics such as cache control, copying, MMU activity, and I/O scheduling
- Why we chose AIO/DIO for ScyllaDB and a retrospective on that decision seven years later

Understanding Storage I/O Under Load
There’s a popular misconception about I/O that (modern) SSDs are easy to deal with; they work pretty much like RAM but use a “legacy” submit-complete API. And other than keeping in mind a disk’s possible peak performance and maybe maintaining priorities of different IO streams there’s not much to care about. This is not quite the case – SSDs do show non-linear behavior and understanding the disk’s real abilities is crucial when it comes to squeezing as much performance from it as possible.
Diskplorer is an open-source disk latency/bandwidth exploring toolset. By using Linux fio under the hood it runs a battery of measurements to discover performance characteristics for a specific hardware configuration, giving you an at-a-glance view of how server storage I/O will behave under load. ScyllaDB CTO Avi Kivity shares an interesting approach to measuring disk behavior under load, gives a walkthrough of Diskplorer and explains how it’s used.
With the elaborated model of a disk at hand, it becomes possible to build latency-oriented I/O scheduling that cherry-picks requests from the incoming queue keeping the disk load perfectly Balanced. ScyllaDB engineer Pavel Emelyanov also presents the scheduling algorithm developed for the Seastar framework and shares results achieved using it.

ScyllaDB User Experiences
Eliminating Volatile Latencies: Inside Rakuten’s NoSQL Migration
Patience with Apache Cassandra’s volatile latencies was wearing thin at Rakuten, a global online retailer serving 1.5B worldwide members. The Rakuten Catalog Platform team architected an advanced data platform – with Cassandra at its core – to normalize, validate, transform, and store product data for their global operations. However, while the business was expecting this platform to support extreme growth with exceptional end-user experiences, the team was battling Cassandra’s instability, inconsistent performance at scale, and maintenance overhead. So, they decided to migrate.
Watch this video to hear Hitesh Shah’s firsthand account of:
- How specific Cassandra challenges were impacting the team and their product
- How they determined whether migration would be worth the effort
- What processes they used to evaluate alternative databases
- What their migration required from a technical perspective
- Strategies (and lessons learned) for your own database migration

Real-World Resiliency: Surviving Datacenter Disaster
Disaster can strike even the most seemingly prepared businesses. In March 2021, a fire completely destroyed a popular cloud datacenter in Strasbourg, France, run by OVHcloud, one of Europe’s leading cloud providers. Because of the fire, millions of websites went down for hours and a tremendous amount of data was lost.
One company that fared better than others was Kiwi.com, the popular European travel site. Despite the loss of an entire datacenter, Kiwi.com was able to continue operations uninterrupted, meeting their stringent Service Level Agreements (SLAs) without fail.
What was the secret to their survival while millions of other sites caught in the same datacenter fire went dark?
Watch this video to learn about Kiwi.com’s preparedness strategy and get best practices for your own resiliency planning, including:
- Designing and planning highly available services
- The Kiwi.com team’s immediate disaster response
- Long-term recovery and restoration
- Choosing and implementing highly resilient systems

NoSQL Trends and Best Practices
Beyond Jurassic NoSQL: New Designs for a New World
We live in an age of rapid innovation, but our infrastructure shows signs of rust and old age. Under the shiny exterior of our new technology, some old and dusty infrastructure is carrying a weight it was never designed to hold. This is glaringly true in the database world, which remains dominated by databases architected for a different age. These legacy NoSQL databases were designed for a different (nascent) cloud, different hardware, different bottlenecks, and even different programming models.
Avishai Ish-Shalom shares his insights on the massive disconnect between the potential of a brave new distributed world and the reality of “modern” applications relying on fundamentally aged databases. This video covers:
- The changes in the operating environment of databases
- The changes in the business requirements for databases
- The architecture gap of legacy databases
- New designs for a new world
- How the adoption of modern databases impacts engineering teams and the products you’re building

Learning Rust the Hard Way for a Production Kafka + ScyllaDB Pipeline
Numberly operates business-critical data pipelines and applications where failure and latency means “lost money” in the best-case scenario. Most of their data pipelines and applications are deployed on Kubernetes and rely on Kafka and ScyllaDB, with Kafka acting as the message bus and ScyllaDB as the source of data for enrichment. The availability and latency of both systems are thus very important for data pipelines. While most of Numberly’s applications are developed using Python, they found a need to move high-performance applications to Rust in order to benefit from a lower-level programming language.
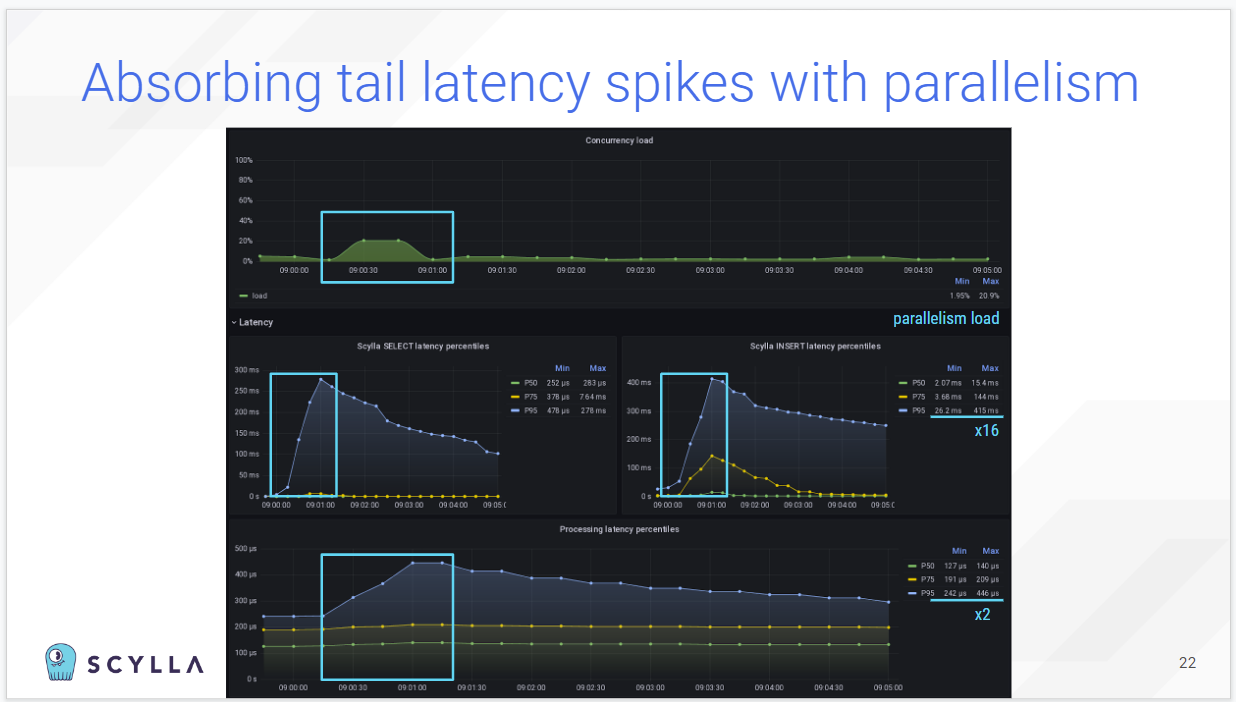
Learn the lessons from Numberly’s experience, including:
The rationale for selecting a lower-level language
Strategies for developing using a lower-level Rust code base
Observability and analyzing latency impacts with Rust
Tuning everything from Apache Avro to driver client settings
How to build a mission-critical system combining Apache Kafka and ScyllaDB
Feedback from 6 months of Rust in production

Latency and Consistency Tradeoffs in Modern Distributed Databases
Just over 10 years ago, Dr. Daniel Abadi proposed a new way of thinking about the engineering tradeoffs behind building scalable, distributed systems. According to Dr. Abadi, this new model, known as the PACELC theorem, comes closer to explaining the design of distributed database systems than the well-known CAP theorem.

Watch this video to hear Dr. Abadi’s reflections on PACELC ten years later, explore the impact of this evolution, and learn how ScyllaDB Cloud takes a unique approach to support modern applications with extreme performance and low latency at scale.
