Cobli’s Journey from Cassandra to ScyllaDB: Dissecting a Real-Life Migration Process

Editor’s note: This is the second blog in a series; part 1 was Cobli’s Drive From Cassandra to ScyllaDB. Cobli’s blogs were originally published on Medium in Portuguese.
In part 1 , we got the green light for the migration. Next, it was time to “rally the troops” and put our brains together to outline a strategy.
When I say “rally the troops,” I mean customer support teams, sales, management, finance, tech teams… No, we didn’t create a meeting with 100 people. Our team tackled this through deliberate interactions with the other teams, exchanging ideas, negotiating budgets and downtimes, collecting feedback, etc.
It is important that the entire company is aligned and engaged for a change that can ultimately impact everyone.
But, since this blog series is primarily technical, let’s leave politics aside and dive into the logistical details.
Disclosure: The migration plan research and development process was much less linear than this post makes it out to be. We reorganized events for clarity here, but it is important to keep in mind that the process of technical discovery and internal alignments followed a much more organic path.
The ScyllaDB Approach
The migration proposal suggested by ScyllaDB is detailed in their documentation. I’ll simplify the steps here:
- Create your database schema in ScyllaDB (as we did in part 01 ).
- Configure applications for dual writing (i.e., any insert/delete/update goes to both Apache Cassandra and ScyllaDB).
- Take a snapshot of all Apache Cassandra data (generating SStable files).
- Load SSTables to ScyllaDB using the sstableloader tool (which will essentially read a bunch of files in binary format, convert them into actual CQL queries, and write against the new database).
- Wait for the validation period: write and read from both databases, with ScyllaDB as the source of truth. Compare reads and write (via metric or log) whenever there are inconsistencies.
- When it’s been a while (to be defined on a case-by-case basis) since inconsistencies surfaced in the metrics or logs, remove Apache Cassandra from any read/write processes.
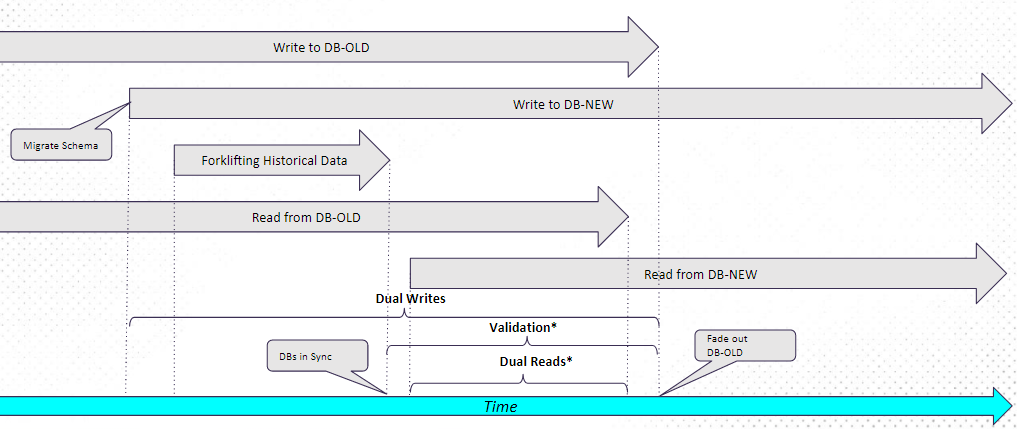
Migration strategy suggested by ScyllaDB
There’s no panacea
Despite being a safe, generalist approach and delivering a migration without downtime, the path suggested by ScyllaDB is quite laborious. It is certainly a good path for many cases, but in our case, there were some obstacles. In particular:
- We have a fairly large number of client systems for this database. Among them, nearly 20 independent streaming data processing jobs (made in Apache Flink). Everything would need to be changed and deployed 3 times to change the read/write schemes.
- Also due to Flink’s characteristics — during the time of dual writes — we would have to “level down” the availability and latency of our service. That is, we would have the worst time of the two databases and be down if either of them is unavailable.
- We had time constraints — about 2 months — to get the cost-reduction impacts within the cycle and beat our Key Results.
- We would need to keep both databases at production scale for a longer time (from the procedure’s steps 2 to 5), which would surely increase migration costs and decrease the project’s ROI (also affecting our cost reduction Key Results).
We had strong reasons to try a more “courageous” approach.

All right… This is kinda like “self-help” books. But it is true self-help, before it became hype – Hehe
As the technical breakthroughs unfolded, we had been talking to the entire company about a migration window. We reached a certain consensus: 6 hours of unavailability on a Sunday morning would be feasible without causing major impacts on the business.
So, we started to plan the possibility of the great…
“Stop-the-world” migration
In a fleet monitoring system, moments are crucial: knowing where the car was at each moment, at what moment it exceeded the speed limit, at what moment it made a stop, and so on.
You can imagine that questions like “what stops did this vehicle make between 8:00 and 12:00 yesterday, sorted by date/time” are quite common around here.
No wonder most of our large tables contain “time-series-like” data. In Cassandra, the implementation of time series tables is done with the clustering key — a special index responsible for ordering the data saved in the database — filled with the time associated with that data point. This allows you to filter data by time intervals and sort it by time very efficiently.
Example of time-series data: “trips completed” by vehicles monitored over time
Ah, another interesting aspect of our big tables: they are immutable. Inserted lines are not updated (ok, there are a few cases, but we rarely change lines that are more than a month old).
Well, what does all this have to do with migration? Simple: this makes it possible for us to migrate data based on time blocks. “Oh, I want to migrate all the data from last year” — easy! Fetching data in the old database for periods of time is “cheap” and the data comes “automatically consistent” (since it is immutable).
All this imbroglio to arrive at an extremely simple migration strategy…
- Migrate in the background (without impacting systems) part of the data from the time series tables — basically from the “first row” to the time of migration (I’ll call it “D-day” from now on).
- On D-day, stop all services, migrate the missing data as quickly as possible, and start all services again.

It seems so, but not without the famous and necessary…
Criticism time
So far I’ve talked about the pros and cons of ScyllaDB’s proposed migration. Nothing is fairer than outlining the pros and cons (advantages and disadvantages) of the new strategy applied to our case.
Pros:
- Consistency assurance: Historical data comes in the first wave, and as it is immutable, it is automatically consistent on the new database. On D-day, we ensure that no new data is written during the backup/restore process. When uploading services, the data will be consistent.
- Simple and punctual operating procedure — at no time do two databases run in production at the same time; on D-day, we just need to stop and start all services at once.
- Deterministic migration over time — tests with partial migrations can give a good estimate of how long the forklifting of historical data and the remaining data will take during D- day.
Cons:
- High cost of D-day — in my view, the worst con of this scenario. This cost involved: leaving customers without access to the system for hours; developing a detailed plan and tools to reduce downtime as much as possible; allocating staff outside normal working hours; internal and external communication work for the downtime window; implementation of a maintenance page operated by feature flags (which we didn’t have until then)
The possibility of D-day failure should be added here, which would replicate part of these costs, in addition to the cost of keeping the two databases “up” for a longer time. That was not our case, luckily.
- Low post-migration visibility — we’ll know how the new database will handle the production load only when we flip the switch; this is a very considerable risk that we have decided to take.
It is possible to mitigate this risk in several ways, from a simple performance comparison with some queries to a replay of queries from the production environment. As already mentioned in part 01 , we did the basics and ended up encountering post-migration problems, which could be a topic for another series of posts.
- Scylla-migrator did not allow data filtering — the Spark job copied entire tables without any filter options, which prevented time-lapse copies; this con was quickly remedied with a small contribution to the project.
It was not a simple decision, but the predictability in terms of migration time and cost weighed heavily, in addition to the greater operational security that we had with the new strategy.
The migration is planned to be completed in about 1 month. If we went for the solution proposed by ScyllaDB, just the changes and the numerous deploys of our jobs in Flink would easily eat up that time.
Show time!
No, Elvis didn’t write the songs he sang. And 100 out of 100 memes with that phrase are unfair to the real authors
Now that we have a plan, it’s time to put it into practice. In the next post we’ll dig through the bits and bytes and the lot of learning we’ve had in the process.
See you soon!