ScyllaDB Elasticity: Demo, Theory, and Future Plans

Watch a demo of how ScyllaDB’s Raft and tablets initiatives play out with real operations on a real ScyllaDB cluster — and get a glimpse at what’s next on our roadmap.
If you follow ScyllaDB, you’ve likely heard us talking about Raft and tablets initiatives for years now. (If not, read more on tablets from Avi Kivity and Raft from Kostja Osipov) You might have even seen some really cool animations. But how does it play out with real operations on a real ScyllaDB cluster? And what’s next on our roadmap – particularly in terms of user impacts?
ScyllaDB Co-Founder Dor Laor and Technical Director Felipe Mendes recently got together to answer those questions. In case you missed it or want a recap of the action-packed and information-rich session, here’s the complete recording:
In case you want to skip to a specific section, here’s a breakdown of what they covered when:
- 4:45 ScyllaDB already scaled linearly
- 8:11 Tablets + Raft = elasticity, speed, simplicity, TCO
- 11:45 Demo time!
- 30:23 Looking under the hood
- 46:19: Looking ahead
And in case you prefer to read vs watch, here are some key points…
Double Double Demo
After Dor shared why ScyllaDB adopted a new dynamic “tablets-based” data replication architecture for faster scaling, he passed the mic over to Felipe to show it in action. Felipe covers:
- Parallel scaling operations (adding and removing nodes) – speed and impact on latency
- How new nodes can start servicing increased demand almost instantly
- Dynamic load balancing based on node capacity, including automated resharding for new/different instance types
The demo starts with the following initial setup:
- 3-node cluster running on AWS i4i.xlarge
- Each node processing ~17,000 operations/second
- System load at ~50%
Here’s a quick play-by-play…
Scale out:
- Bootstrapped 3 additional i4i.large nodes in parallel
- New nodes start serving traffic once the first tablets arrive, before the entire data set is received.
- Tablets migration complete in ~3 minutes
- Writes are at sub-millisecond latencies; so are read latencies once the cache warms up (in the meantime, reads go to warmed up nodes, thanks to heat-weighted load balancing)
Scale up:
- Added 3 nodes of a larger instance size (i4i.2xlarge, with double the capacity of the original nodes) and increased the client load
- The larger nodes receive more tablets and service almost twice the traffic than the smaller replicas (as appropriate for their higher capacity)
- The expanded cluster handles over 100,000 operations/second with the potential to handle 200,000-300,000 operations/second
Downscale:
- A total of 6 nodes were decommissioned in parallel
- As part of the decommission process, tablets were migrated to other replicas
- Only 8 minutes were required to fully decommission 6 replicas while serving traffic
A Special Raft for the ScyllaDB Sea Monster
Starting with the ScyllaDB 6.0 release, topology metadata is managed by the Raft protocol. The process of adding, removing, and replacing nodes is fully linearized. This contributes to parallel operations, simplicity, and correctness.
Read barriers and fencing are two interesting aspects of our Raft implementation. Basically, if a node doesn’t know the most recent topology, it’s barred from responding to related queries. This prevents, for example, a node from observing an incorrect topology state in the cluster – which could result in data loss. It also prevents a situation where a removed node or an external node using the same cluster name could silently come back or join the cluster simply by gossiping with another replica.
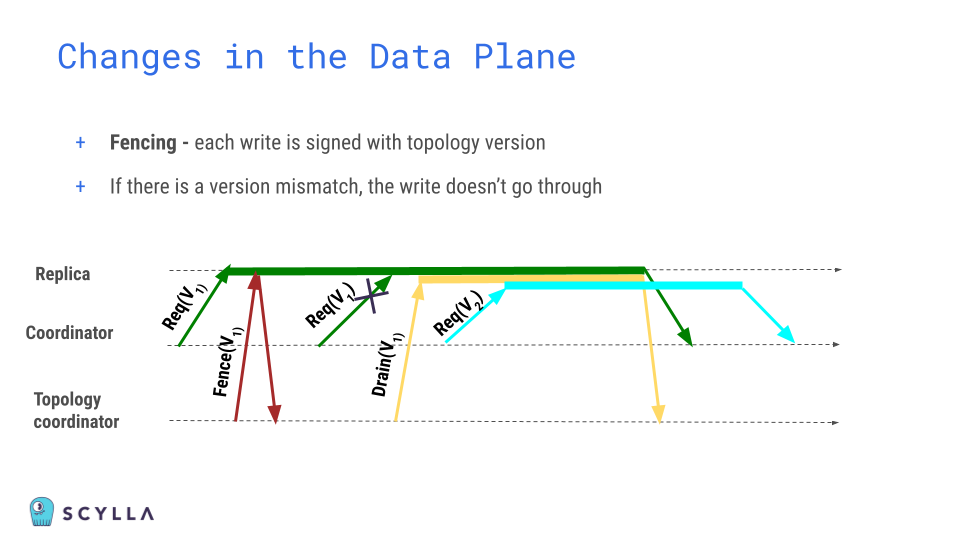
Another difference: Schema versions are now linearized, and use a TimeUUID to indicate the most up-to-date schema. Linearizing schema updates not only makes the operation safer; it also considerably improves performance. Previously, a schema change could take a while to propagate via gossip – especially in large cluster deployments. Now, this is gone.
TimeUUIDs provide an additional safety net. Since schema versions now contain a time-based component, ScyllaDB can ensure schema versioning, which helps with:
- Improved visibility on conditions triggering a schema change on logs
- Accurately restoring a cluster backup
- Rejecting out-of-order schema updates

Tablets relieve operational pains
The latest changes simplify ScyllaDB operations in several ways:
- You don’t need to perform operations one by one and wait in between them; you can just initiate the operation to add or remove all the nodes you need, all at once
- You no longer need to cleanup after you scale the cluster
- Resharding (the process of changing the shard count of an existing node) is simple. Since tablets are already split on a per-shard boundary, resharding simply updates the shard ownership
- Managing the system_auth keyspace (for authentication) is no longer needed. All auth-related data is now automatically replicated to every node in the cluster
- Soon, repairs will also be automated
Expect less: typeless, sizeless, limitless
ScyllaDB’s path forward from here certainly involves less: typeless, sizeless, limitless.
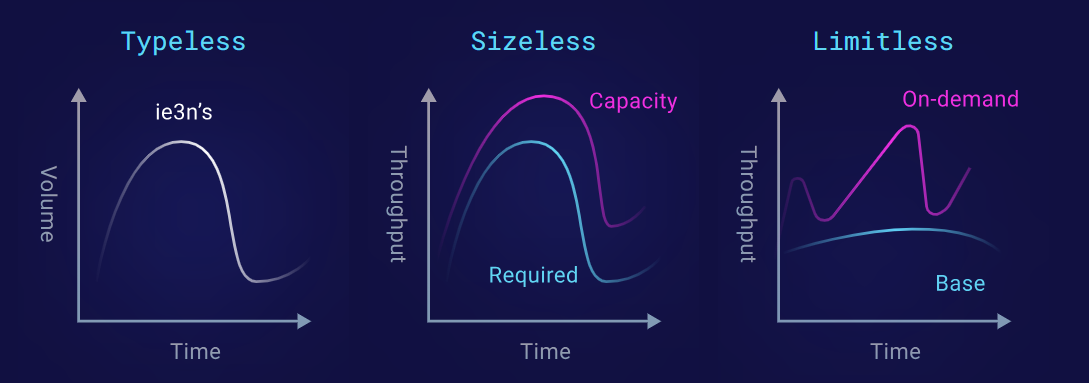
- You could be typeless. You won’t have to think about instance types ahead of time. Do you need a storage-intensive instance like the i3ens, or a throughput-intensive instance like the i4is? It no longer matters, and you can easily transition or even mix among these.
- You could be sizeless. That means you won’t have to worry about capacity planning when you start off. Start small and evolve from there.
- You could also be limitless. You could start off anticipating a high throughput and then reduce it, or you could commit to a base and add on-demand usage if you exceed it.