ScyllaDB Cloud Goes Serverless
At ScyllaDB Summit 2023 audiences were given the first glimpse of ScyllaDB Cloud’s Database-as-a-Service (DBaaS) serverless implementation.
Why Serverless?
Serverless computing liberates developers from the infrastructure underlying their managed Software-as-a-Service (SaaS) systems. While traditional managed services relieve some levels of administrative burden, serverless implementations further abstracts the back end hardware and operating system details, allowing developers to fully focus on their application code.
For service providers, serverless implementations allow them to uncouple the user interface and developer experience from the infrastructure layer, enabling more seamless methods to innovate, provision and upgrade their services.
ScyllaDB’s Road to Serverless
ScyllaDB CEO Dor Laor broke the news of the serverless implementation in the title of his keynote address, “To Serverless and Beyond.” After recapping all of the innovation that has gone into ScyllaDB’s evolution, Dor focused on the “Future of Fast Data” — components of which require further innovation in the core of ScyllaDB and its serverless implementation.
WATCH DOR LAOR’S SCYLLADB SUMMIT KEYNOTE
“We’re switching from instances and servers to units of virtual CPUs,” Dor noted. “Forget what you know about instance types, about server sizes… With serverless the building block is the virtual CPU (vCPU).”
This also means that ScyllaDB will decouple, to an extent, storage from compute. For now, it will still rely upon NVMe — though ScyllaDB CTO Avi Kivity also hinted at an upcoming feature for tiered storage, using a cloud object storage option.
WATCH AVI KIVITY’S SCYLLADB SUMMIT KEYNOTE
Yaniv Kaul, ScyllaDB’s VP of R&D, took the audience into the details of the serverless implementation of ScyllaDB Cloud, revealing how it is already available in beta. Currently in ScyllaDB Cloud every tenant gets dedicated VM instances, which means provisioning is only granular to the instance level. Today if you wish to scale, you need to add an entire instance. In fact, because ScyllaDB typically runs with a replication factor of three, you have to add three instances to the cluster. With ScyllaDB’s serverless implementation, the goal is to allow users to increment growth on the individual vCPU basis.
WATCH YANIV KAUL’S SERVERLESS SCYLLADB CLOUD PRESENTATION
Serverless Trial on ScyllaDB Cloud: Available Now!
Users who want to try out ScyllaDB Cloud’s serverless experience can register now and spin up a serverless free trial. This free trial requires no credit card.
SIGN UP FOR SCYLLADB CLOUD NOW
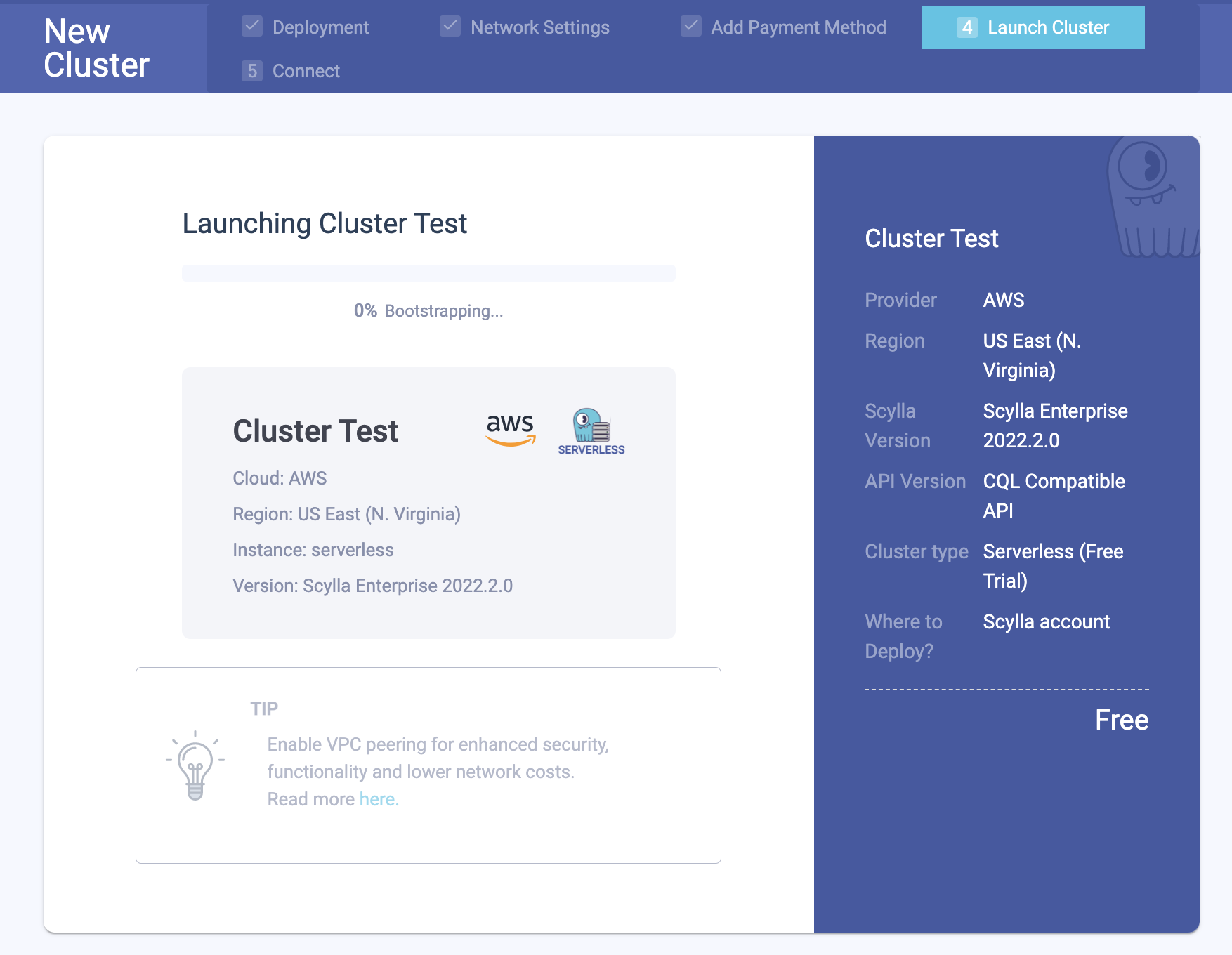
ScyllaDB Cloud currently supports a serverless trial on triple-replicated 1 vCPU cluster with over 200 GB storage. Users can connect to the cluster and familiarize themselves with ScyllaDB in action. They have full functionality of the CQL interface and operations.
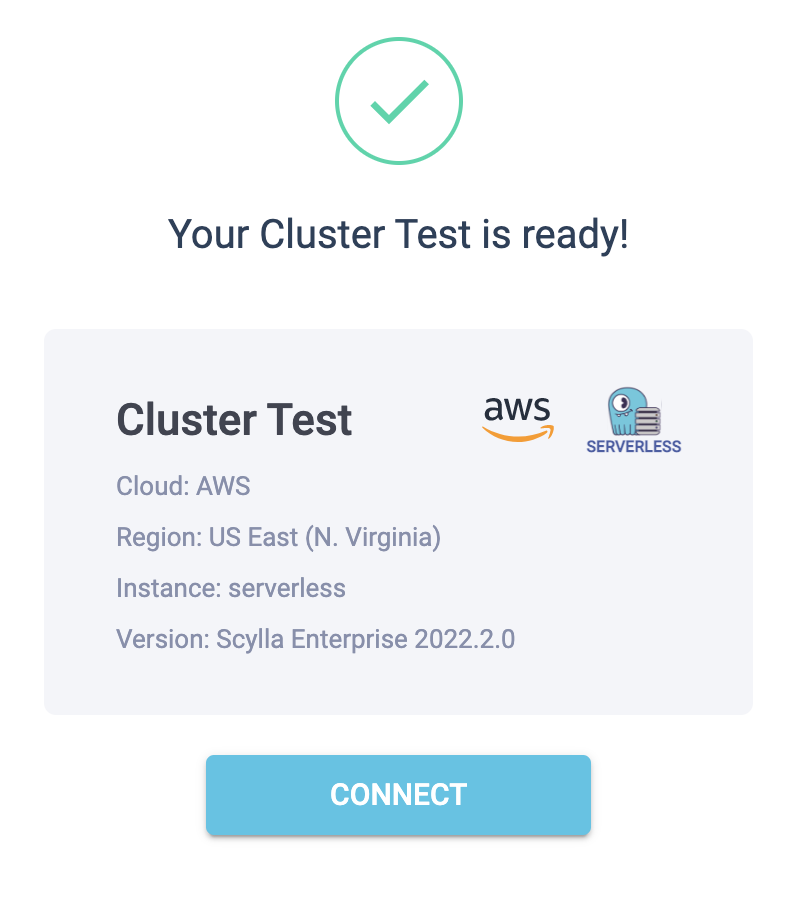
Once the cluster is provisioned you can then download the Connection Bundle, which is a yaml file containing information and credentials for login, and can connect via cqlsh — the CQL shell — as well as use any of the ScyllaDB shard-aware drivers, such as Java, Go or Python.
What’s Behind the Curtain?
Yaniv also explained to the audience the back end efforts required to make the serverless experience work. This includes enhancements to ScyllaDB’s Kubernetes operator for use in the control plane for ScyllaDB Cloud. Since ScyllaDB Cloud already supports multiple cloud providers, including AWS, AWS Bring Your Own Account (BYOA) and Google Cloud Platform, treating serverless as another cloud flavor was an easy extension of the underlying control plane.
For tenant deployment, ScyllaDB’s Kubernetes operator deploys a complete cluster, including a triple-replicated server cluster, a ScyllaDB Manager automated backup and repair agent, ScyllaDB Monitoring Stack for observability, and shard-aware ScyllaDB drivers using SNI proxy.
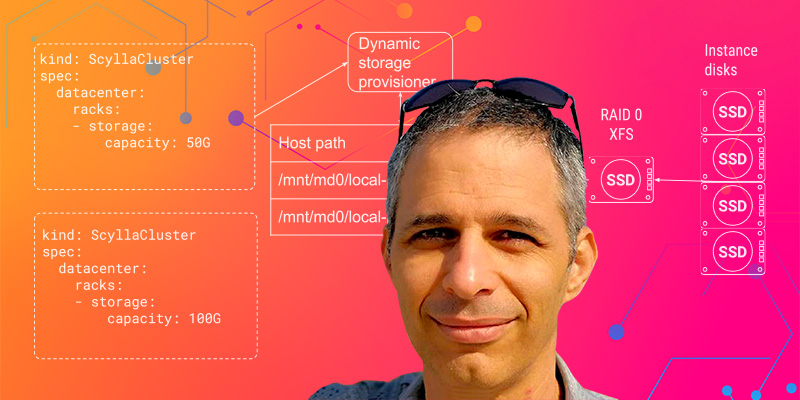
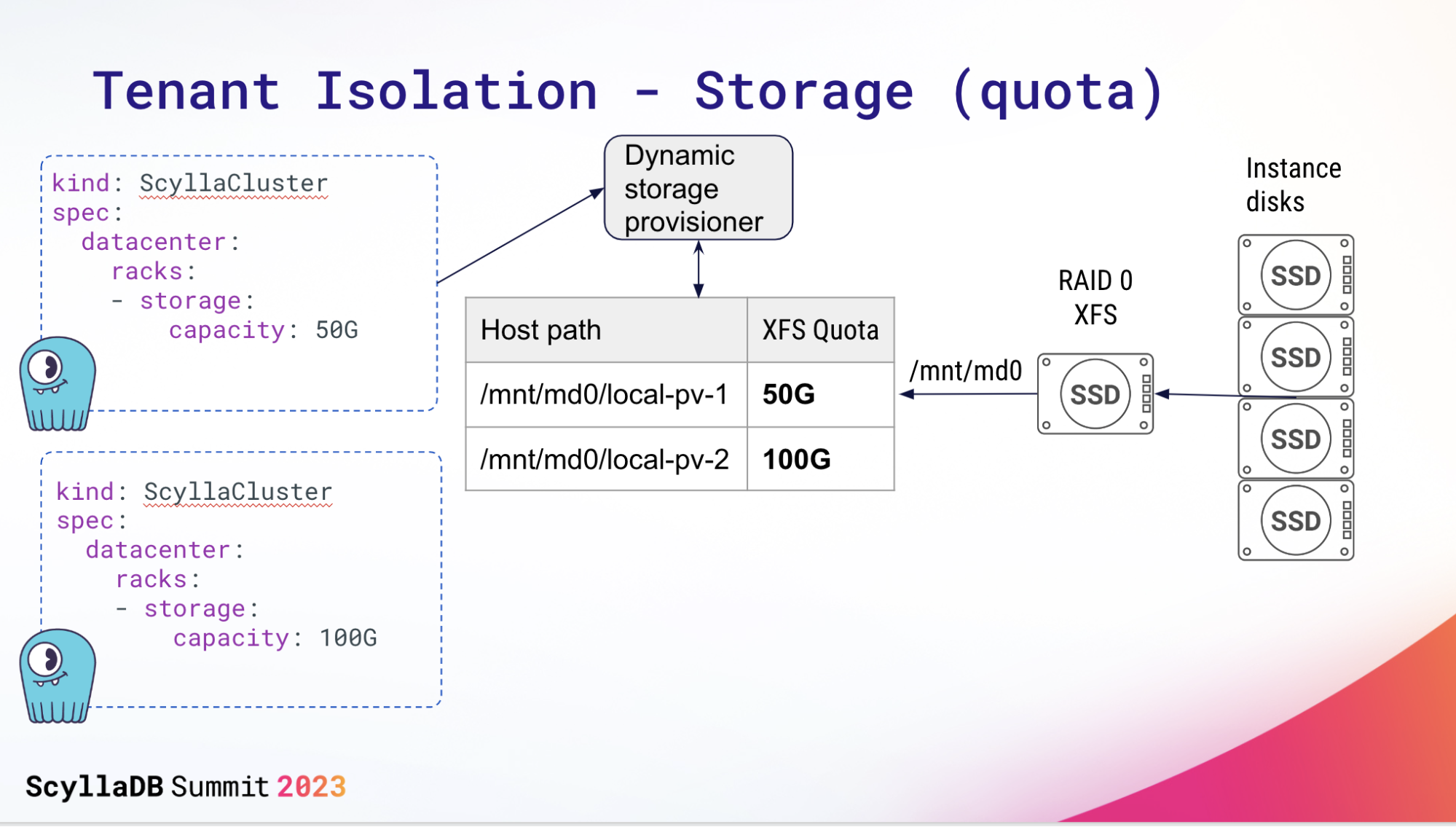
These tenants (pods) are assigned their own isolated memory, CPU, and disk allocations. ScyllaDB Cloud relies on an internal dynamic storage provisioner to assign XFS quotas.
On the connection side, ScyllaDB Cloud implemented Server Name Indication (SNI), an extension of the Transport Layer Security (TLS) protocol. Implementing SNI before ScyllaDB Cloud allows ScyllaDB shard-aware clients to connect to the right vCPU on the back end without having to know the individual IP addresses of the servers where those vCPUs reside.
There are going to be more announcements for ScyllaDB Cloud’s serverless evolution throughout 2023 and beyond. If you have questions or feedback on how you can implement your next generation of serverless applications on ScyllaDB Cloud, feel free to contact us or post on our user forum.