ScyllaDB’s Path to Strong Consistency: A New Milestone
In ScyllaDB 5.2, we made Raft generally available and use it for the propagation of schema changes. Quickly assembling a fresh cluster, performing concurrent schema changes, updating node’s IP addresses – all of this is now possible.
And these are just the beginning of visible user changes for Raft-enabled clusters; next on the list are safe topology changes and automatically changing data placement to adjust to the load and distribution of data. Let’s focus on what’s new in 5.2 here, then we’ll cover what’s next in a follow up blog.
Why Raft?
If you’re wondering what the heck Raft is and what it has to do with strong consistency, strongly consider watching these two tech talks from ScyllaDB Summit 2022.
Making Schema Changes Safe with Raft
The Future of Consensus in ScyllaDB 5.0 and Beyond
But if you want to read a quick overview, here it goes…
Strong vs Eventual Consistency
Understanding a strongly consistent system is easy. It’s like observing two polite people talking: there is only one person talking at a time and you can clearly make sense of who talks after who and capture the essence of the conversation. In an eventually consistent system, changes such as database writes are allowed to happen concurrently and independently, and the database guarantees that eventually there will be an order in which they all line up.
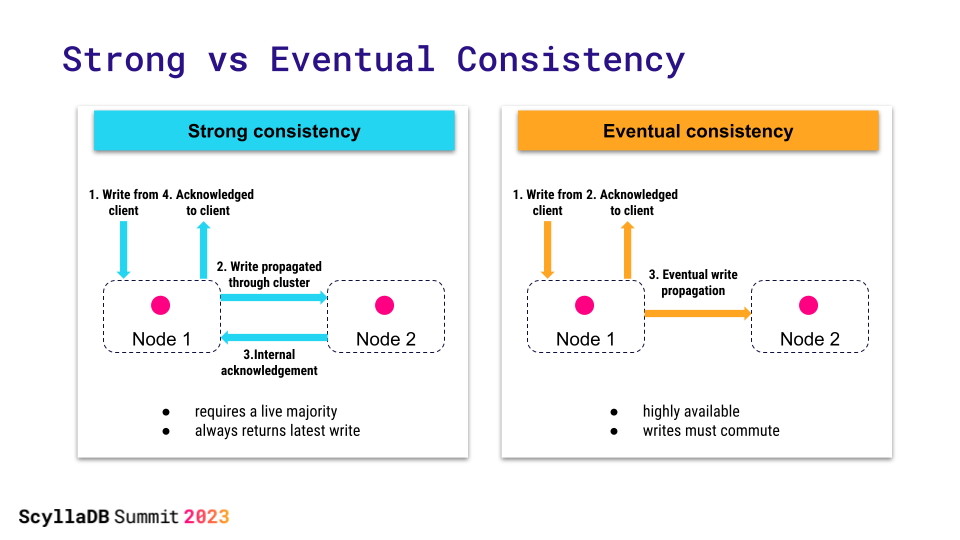
Eventually consistent systems can accept writes to nodes that are partitioned away from the rest of the cluster. Strongly consistent systems require a majority of the nodes to acknowledge an operation (such as the write) in order to accept it. So, the tradeoff between strong and eventual consistency is in requiring the majority of the participants to be available to make progress.
ScyllaDB, as a Cassandra-compatible database, started as an eventually consistent system, and that made perfect business sense. In a large cluster, we want our writes to be available even if a link to the other data center is down.
Metadata Consistency
Apart from storing user data, the database maintains additional information about it, called metadata. Metadata consists of topology (nodes, data distribution) and schema (table format) information.
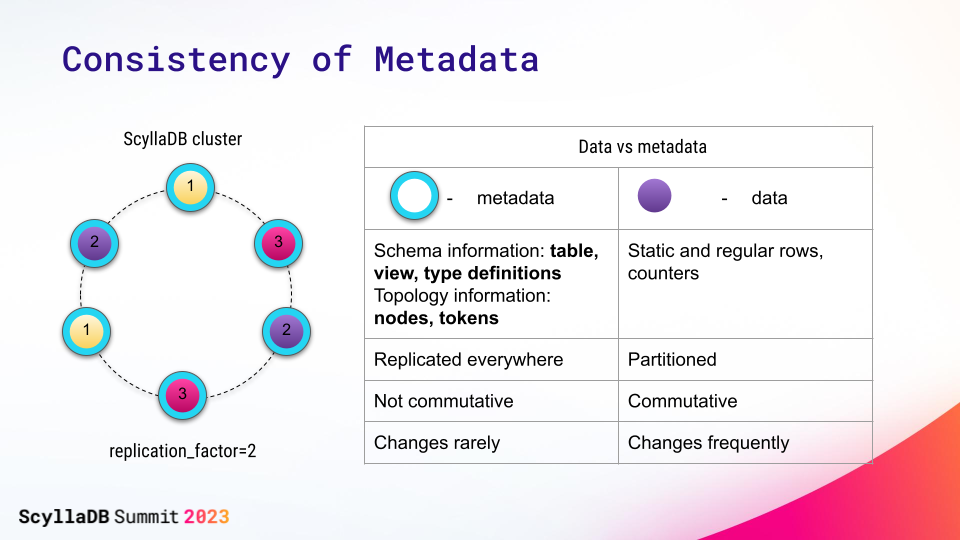
A while ago, ScyllaDB recognized that there is little business value in using the eventually consistent model for metadata. Metadata changes are infrequent, so we do not need to demand extreme availability for them. Yet, we want to reliably change the metadata in an automatic mode to bring elasticity, which is hard to do with the eventually consistent model underneath.
Raft for Metadata Replication
This is when we embarked on a journey that involved Raft: an algorithm and a library we implemented to replicate any kind of information across multiple nodes.
Here’s how it works.
Suppose you had a program or an application that you wanted to make reliable. One way to do that is to execute that program on a collection of machines and ensure they all execute it in exactly the same way. A replicated log can help to ensure that these state machines (programs or applications that take inputs and produce outputs) execute exactly the same commands.
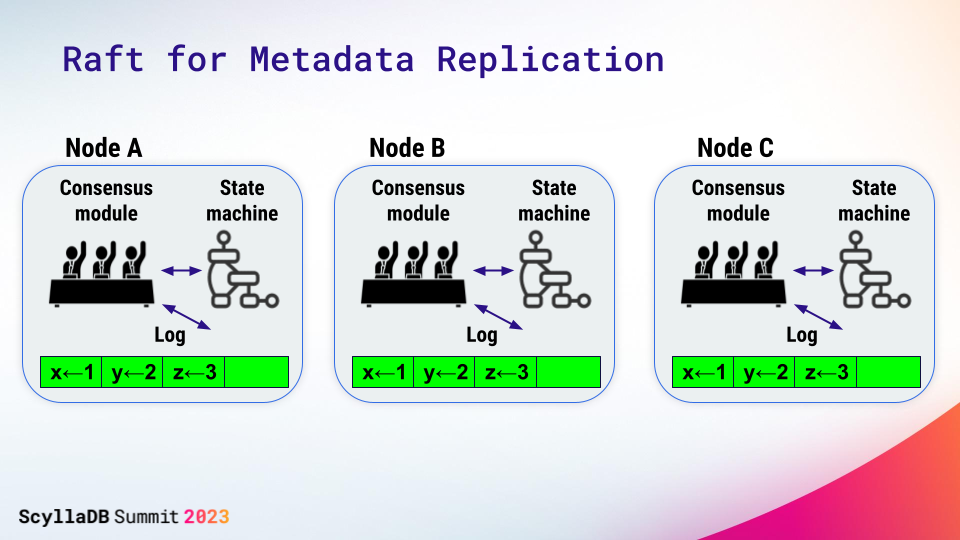
A client of the system that wants to execute a command passes it to one of these machines.
That command – let’s call it X – gets recorded in the log of the local machine, and it’s then passed to the other machines and recorded in their logs as well. Once the command has been safely replicated in the logs, it can be passed to the state machines for execution. And when one of the state machines is finished executing the command, the result can be returned back to the client program.
And you can see that as long as the logs on the state machines are identical, and the state machines execute the commands in the same order, we know they are going to produce the same results. So Raft is the algorithm that keeps the replicated log identical and in sync on all cluster members. Its consensus module ensures that the command is replicated and then passed to the state machine for execution.
The system makes progress as long as any majority of the servers are up and can communicate with each other. (2 out of 3, 3 out of 5).
Again – we strongly recommend that you watch the videos above if you want more details.
The Benefits of Raft in ScyllaDB 5.2
In ScyllaDB 5.2, our first use of Raft – for propagation of schema changes – is generally available (GA). This brings you:
- –consistent-cluster-management command line and a scylla.yaml option
- A procedure to recover a cluster after a loss of a majority
- IP address change support
Let’s review each in turn.
Consistent Cluster Management
We’ve branched off ScyllaDB 5.2 with the consistent_cluster_management feature enabled for new clusters. We also implemented an online upgrade procedure to Raft for existing clusters, and machinery to recover existing clusters from a disaster.
What are the benefits of –consistent-cluster-management in ScyllaDB 5.2?
- It is now safe to perform concurrent schema change statements. Change requests don’t conflict, get overridden by “competing” requests, or risk data loss. Schema propagation happens much faster since the leader of the cluster is actively pushing it to the nodes. You can expect the nodes to learn about new schema in a healthy cluster in under a few milliseconds (used to be a second or two).
- If a node is partitioned away from the cluster, it can’t perform schema changes. That’s the main difference, or limitation, from the pre-Raft clusters that you should keep in mind. You can still perform other operations with such nodes (such as reads and writes) so data availability is unaffected. We see results of the change not only in simple regression tests, but in our longevity tests which execute DDL. There are fewer errors in the log and the systems running on Raft are more stable when DDL is running.
Going GA means that this option is enabled by default in all new clusters. We achieve this by shipping a new default scylla.yaml with our installation.
If you’re upgrading an existing ScyllaDB installation, set consistent_cluster_management: true in all your scylla.yaml files, perform a rolling restart, and Raft will be enabled cluster-wide.
# Use Raft to consistently manage schema information in the cluster.
# Refer to https://docs.scylladb.com/master/architecture/raft.html for
# more details.
consistent_cluster_management: true
You can watch the progress of the upgrade operation in scylla log. Look for raft_upgrade markers, and as soon as the upgrade finishes, the system.scylla_local key for group0_upgrade_state starts saying “use_post_raft_procedures”:
cqlsh> SELECT * FROM system.scylla_local WHERE key IN ('group0_upgrade_state', 'raft_group0_id');
key | value
----------------------+--------------------------------------
group0_upgrade_state | use_post_raft_procedures
raft_group0_id | a5e9e860-cccf-11ed-a674-c759a640dbb0
(2 rows)
cqlsh>
Support for Majority Loss
The new Raft-based support for disaster recovery provides a way to salvage data when you permanently lose the majority of your cluster. As a preface, note that a majority loss is considered a rare event and that the Raft recovery procedure should be followed only when the affected nodes are absolutely unrecoverable. Otherwise, follow the applicable node restore process for your situation. Be sure to check the Raft manual recovery procedure for additional details.
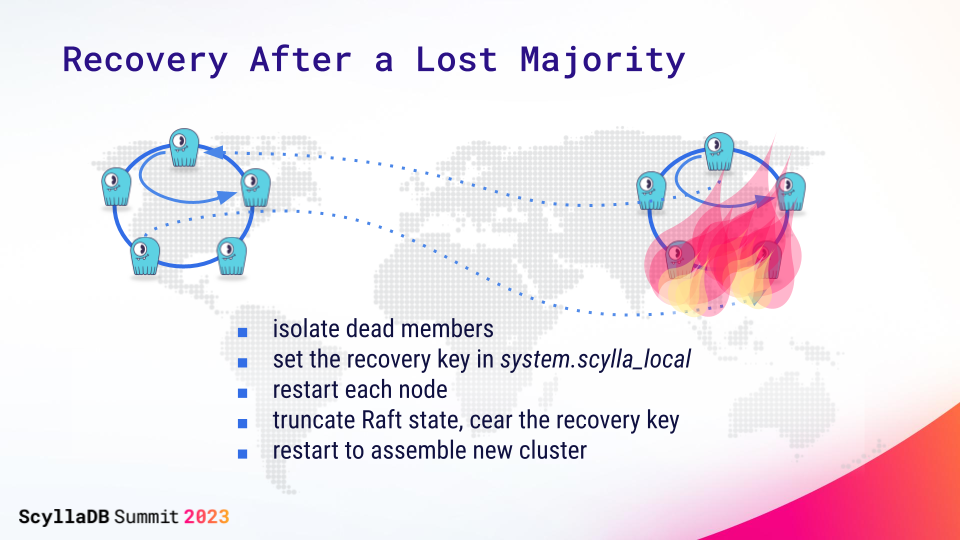
In a nutshell, we added a way to drop the state of consistent cluster management on each node and establish it from scratch in a new cluster. The key takeaway is that your Raft-based clusters, even though they don’t accept schema changes in a minority, are still usable even if your majority is permanently lost. We viewed this as a big concern for the users who are performing upgrades from their existing clusters. To help users see the current cluster configuration as recorded in Raft, we added a new system.raft_state table (it is actually a system-generated view) registering all the current members of the cluster:
cqlsh> SELECT * FROM system.raft_state ;
group_id | disposition | server_id | can_vote
--------------------------------------+-------------+--------------------------------------+----------
a5e9e860-cccf-11ed-a674-c759a640dbb0 | CURRENT | 44d1cfcf-26b3-40e9-bea9-99a2c639ed40 | True
a5e9e860-cccf-11ed-a674-c759a640dbb0 | CURRENT | 75c2f8c4-98fe-4b78-95fc-10fa29b0b5c5 | True
a5e9e860-cccf-11ed-a674-c759a640dbb0 | CURRENT | ad30c21d-805d-4e96-bb77-2588583160cc | True
(3 rows)
cqlsh>Changing IPs
Additionally, we added IP address change support. To operate seamlessly in Kubernetes environments, nodes need to be able to start with existing data directories but different IP addresses. We added support for that in Raft mode as well.
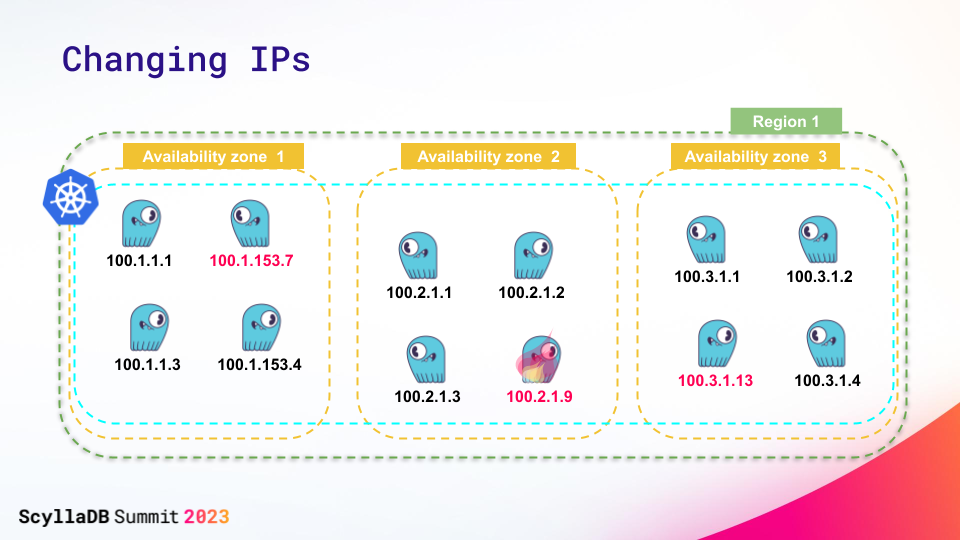
If just one or a few of your node’s IP addresses are changed, you can just restart these nodes with a new IP address and this will work. There’s no need to change the configuration files (e.g. seed lists).
You can even restart the cluster with all node IPs changed. Then, of course, you need to somehow prompt the existing nodes with the new IP addresses of each other. To do so, you should update the seeds: the relevant section of your scylla.yaml with new node IPs will be used to discover the new peers and the contents of system.peers will be updated automatically.
Moving to Raft-Based Cluster Management in ScyllaDB 5.2: What Users Need to Know
As mentioned above, all new clusters will be created with Raft enabled by default from 5.2 on. Upgrading from 5.1 will use Raft only if you explicitly enable it (see the upgrade docs). As soon as all nodes in the cluster opt-in to using Raft, the cluster will automatically migrate those subsystems to using Raft (you should validate that this is the case).
Once Raft is enabled, every cluster-level operation – like updating schema, adding and removing nodes, and adding and removing data centers – requires a quorum to be executed.
For example, in the following use cases, the cluster does not have a quorum and will not allow updating the schema:
- A cluster with 1 out of 3 nodes available
- A cluster with 2 out of 4 nodes available
- A cluster with two data centers (DCs), each with 3 nodes, where one of the DCs is not available
This is different from the behavior of a ScyllaDB cluster with Raft disabled.
Nodes might be unavailable due to network issues, node issues, or other reasons. To reduce the chance of quorum loss, it is recommended to have 3 or more nodes per DC, and 3 or more DCs for a multi-DCs cluster. Starting from 5.2, Scylla provides guidance on how to handle nodetool and topology change failures.
To recover from a quorum loss, it’s best to revive the failed nodes or fix the network partitioning. If this is impossible, see the Raft manual recovery procedure.
Common Questions
To close, let me publicly address a few questions we’ve heard quite often:
How and when will ScyllaDB support multi-key transactions?
We haven’t been planning on distributed transactions yet, but we’re watching the development of the Accord algorithm with interest and enthusiasm. It’s not impossible that ScyllaDB will add transaction support following Cassandra’s footsteps if their implementation is successful.
When will we be able to do concurrent topology changes?
Concurrent topology changes is a broad term; here, I will try to break it up.
First, it implies being able to bootstrap all nodes in a fresh cluster concurrently and quickly assemble such a cluster. This is what we plan to achieve in 5.3, at least in experimental mode.
Second, it implies being able to concurrently stream data from/to multiple nodes in the cluster, including dynamic streaming data for the purposes of load balancing. This is part of our tablets effort, and it is coming after 5.3.
Finally, it’s being able to add (or remove) multiple nodes at a time. Hopefully, with the previous features in place, that won’t be necessary. You will be able to start two nodes concurrently, and they will be added to the cluster quickly and safely but serially. Later, the dynamic load balancing will take care of populating them with data concurrently.
Will Raft eventually replace Gossip?
To a large extent, but not completely.
Gossip is an epidemic communication protocol. The word “epidemic” means that a node does not communicate with its peers directly, but instead chooses one or a few peers to talk to at a given time – and it exchanges the full body of information it possesses with those peers. The information is versioned, so whenever a peer receives an incoming ping, it updates each key with a newer revision. The peers will use the updated data for its own pings, and this is how the information spreads quickly across all nodes, in an “epidemic” fashion.
The main advantage of Gossip is that it issues linear ( O(CLUSTER_SIZE) ) number of messages per round rather than quadratic ( O(CLUSTER_SIZE^2) ) which would be needed if each node would try to reach out to all other nodes at once. As a downside, Gossip takes more time to disseminate information. Typically, the new information reaches all members in logarithmic (O(log(CLUSTER_SIZE))) number of rounds.
In pre-Raft ScyllaDB, Gossip was used to disseminate information about node liveness; for example, node UP/DOWN state and the so-called application state: different node properties, such as:
- Its IP address
- The product version and supported features on that node
- The current schema version on that node
- The tokens the node owns
- CDC generations (keys used by CDC clients to fetch the latest updates)
…
Thanks to its low overhead, Gossip is excellent for propagation of infrequently changed data (e.g., node liveness). Most of the time, all nodes are alive, so having to ping every node from every other node every second is excessive. Yet this is exactly what Gossip started doing in ScyllaDB 5.0. At some point, it was decided that epidemic failure detection, taking log(CLUSTER_SIZE) rounds on average to detect a node failure is too slow (Gossip sends its pings every second; for a large cluster, the failure detection could take several seconds). So, direct failure detection was used: every node started to ping every other node every second. To exchange the application state, Gossip still used the epidemic algorithm.
To summarize, at some point we started living in the worst of all worlds: paying the price of quadratic (O(N^2) ) number of messages for failure detection, and still having slow propagation of key application data, such as database schema.
Even worse, Raft requires its own kind of failure detection – so in 5.2, another direct failure detector was implemented in addition to Gossip. It also sends O(N^2) pings every 100 ms.
Then, the journey of moving things out of application state to Raft began. In 5.2 we started with the schema version. For 5.3, we have moved out the tokens, and are working on CDC generations and cluster features.
Hopefully, eventually almost no application data will be propagated through Gossip. But will it allow us to get rid of the Gossip subsystem altogether?
The part of Gossip that pings other nodes and checks their liveness is used by Raft itself, so it will stay. The part that disseminates some of the most basic node information, such as its IP address and supported features, may also have to stay in Gossip. We would like to be able to exchange this data even before the node joins the cluster and Raft becomes available. Gossip is one of the first subsystems initialized at node start and, as such, it is fundamental to bootstrap. Our goal here at ScyllaDB is to make sure it is used efficiently and doesn’t stand in the way of fast cluster assembly.
Is there any API/tooling/nodetool command to infer and manage Raft, such as discovering which node is the active leader, which nodes are unreachable or managing Raft state?
Raft is internal to ScyllaDB and does not need to be explicitly managed. All the existing nodetool commands continue to work and should be used for topology operations. We currently do not expose the active leader. With tablets, each one will have its own Raft leader. The state of the failure detection is available as before in nodetool status. For detailed procedure nodetool failure handling, I recommend looking at our manual.