Cassandra and ScyllaDB: Similarities and Differences

Chasing Cassandra
Since the initial release of our Cassandra-compatible database, ScyllaDB has been perceived as “chasing Cassandra,” working to achieve feature parity.
This meant that through 2020, we were playing catch up. However, with Scylla Open Source 4.0 we went beyond feature completeness. We suddenly had features Cassandra didn’t have at all. We also introduced features that were named similarly, but implemented differently — often radically so.
At the same time, Cassandra has and will keep adding commands, features and formats. For example, the SSTables formats changed once between 4.0 beta and release candidate 1 and then again in the final release.
This results in the following kind of buckets of features. Some core features of Cassandra, which Scylla has also implemented in its core — the same-same. Same configuration. Same command line inputs and outputs. Same wire protocol. And so on.
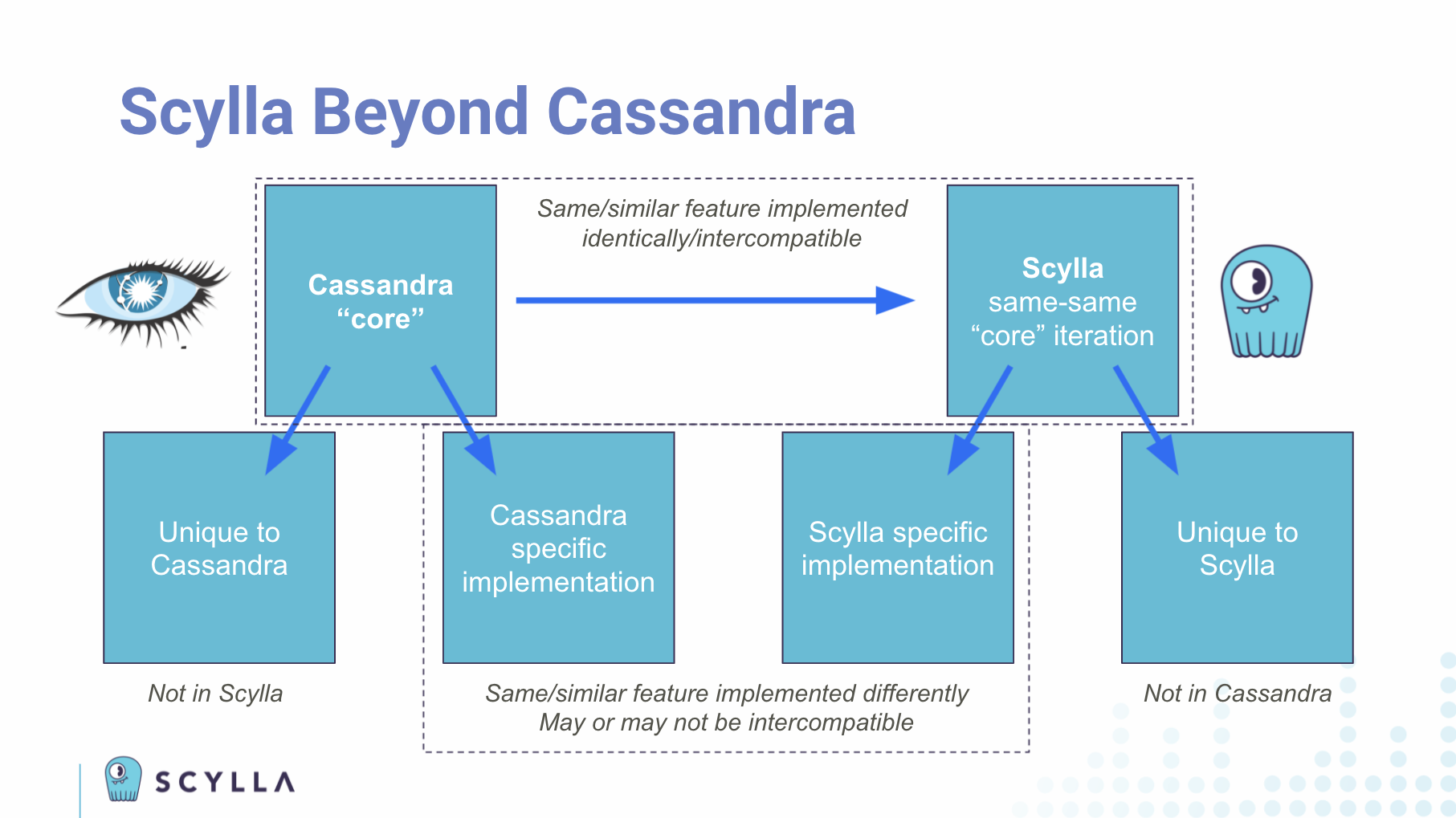
Then there are some things that are unique to Cassandra, such as the Cassandra 4.0 features. Some of these we plan to add in due time, such as the new SSTable formats. Some simply may not be appropriate to implement because of the very different infrastructure and design philosophies — even the code bases. For instance, since Scylla is implemented in C++, you won’t find Java-specific features like you would have in Cassandra. Inversely, you’ll have some features in Scylla that they just won’t implement in Cassandra.
Lastly, there is a mix of features that may be called by the same name, or may sound quite similar, but are actually implemented uniquely across Cassandra and Scylla.
All of these are points of divergence which could become showstoppers for migration if you depended on them in your use case. Or they may be specific reasons to migrate if they represent features or capabilities that you really need, but the other database just will never offer you.
So while Scylla began by chasing Cassandra, now many of our features are beyond Cassandra, and some of their features diverge from our implementation. While we remain committed to making our database as feature complete and compliant to Cassandra as possible and pragmatic, it will be quite interesting to watch as current points of departure between the two become narrowed or widened over the coming years.
What’s the Same Between Scylla & Cassandra?
Let’s start with the common ground. If you are familiar with Cassandra today, what can you expect to feel as comfortable and natural in Scylla?
A Common Heritage: Bigtable and Dynamo
First, the common ancestry. Many of the principles between Cassandra and Scylla are directly correlated. In many ways, you could call Cassandra the “mother” of Scylla in our little database mythological family tree.
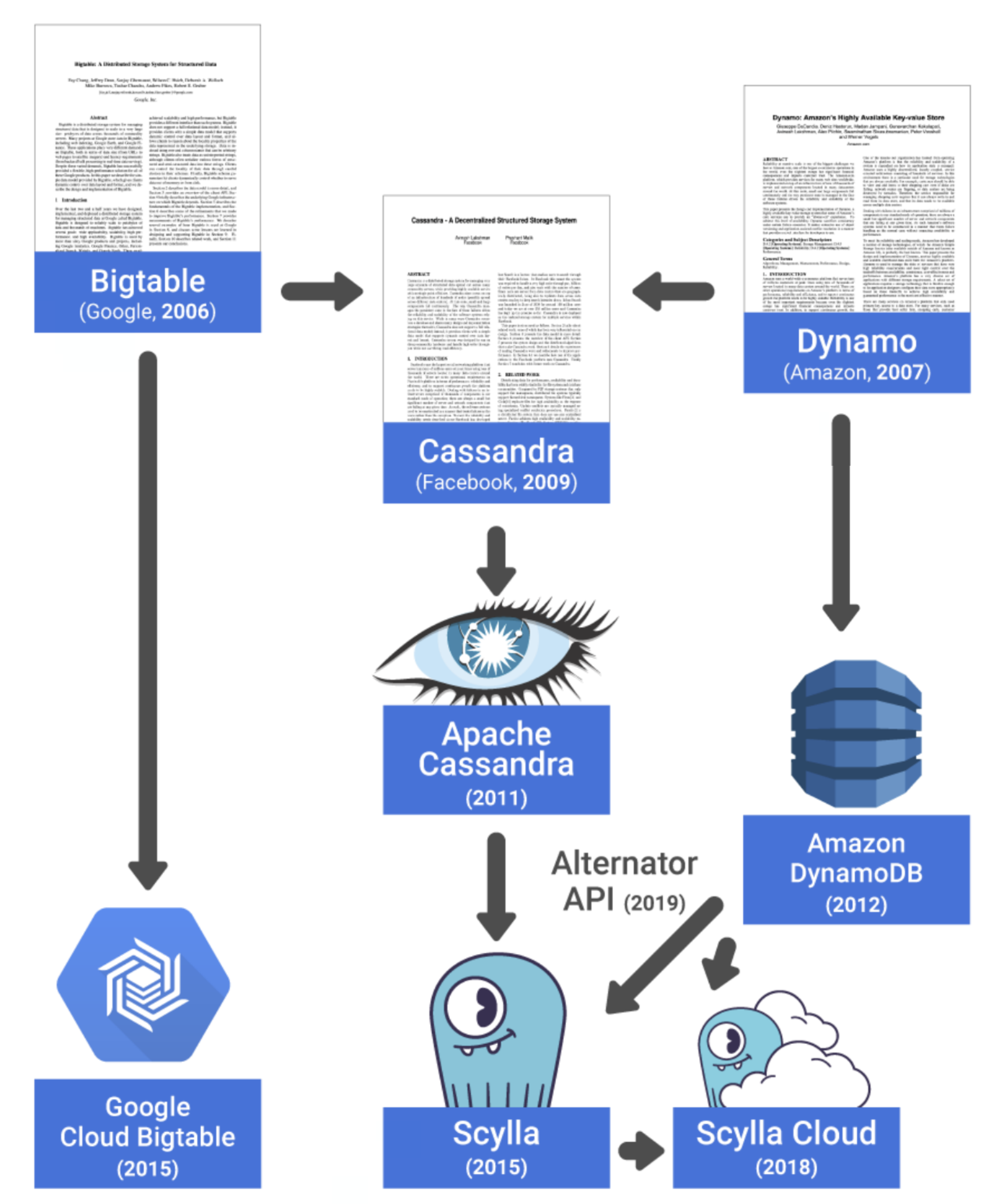
Both draw part of their ancestry from the original Google Bigtable and Amazon Dynamo whitepapers (note: Scylla also offers an Alternator interface for DynamoDB API compatibility; this pulls in additional DNA from Amazon DynamoDB).
Keyspaces, Tables, Basic Operations
With our Cassandra Query Language (CQL) interface, the basic methods of defining how the database is structured and how users interact with it remain the same:
CREATE KEYSPACECREATE TABLEALTER KEYSPACEALTER TABLEDROP KEYSPACEDROP TABLE
These are all standard Cassandra Query Language (CQL). The same thing with basic CRUD operations:
- Create [
INSERT] - Read [
SELECT] - Update [
UPDATE] - Delete [
DELETE]
Plus, there are other standard features across Scylla and Cassandra:
WHEREclauseALLOW FILTERINGTTLfunctions
All comfortable and familiar as a favorite sweater. Also, for database developers who have never used NoSQL before, the whole syntax of CQL is deceptively similar to SQL, at least at a cursory glance. But do not be lulled into a false sense of familiarity. For example, you won’t find JOIN operations supported in CQL!
High Availability
The high availability architecture that Cassandra is known for is likewise found in Scylla. Peer-to-peer leaderless topology. Replication factors and consistency levels set per request. Multi datacenter replication which allows you to be able to survive a full datacenter loss. All typical “AP”-mode database behavior.
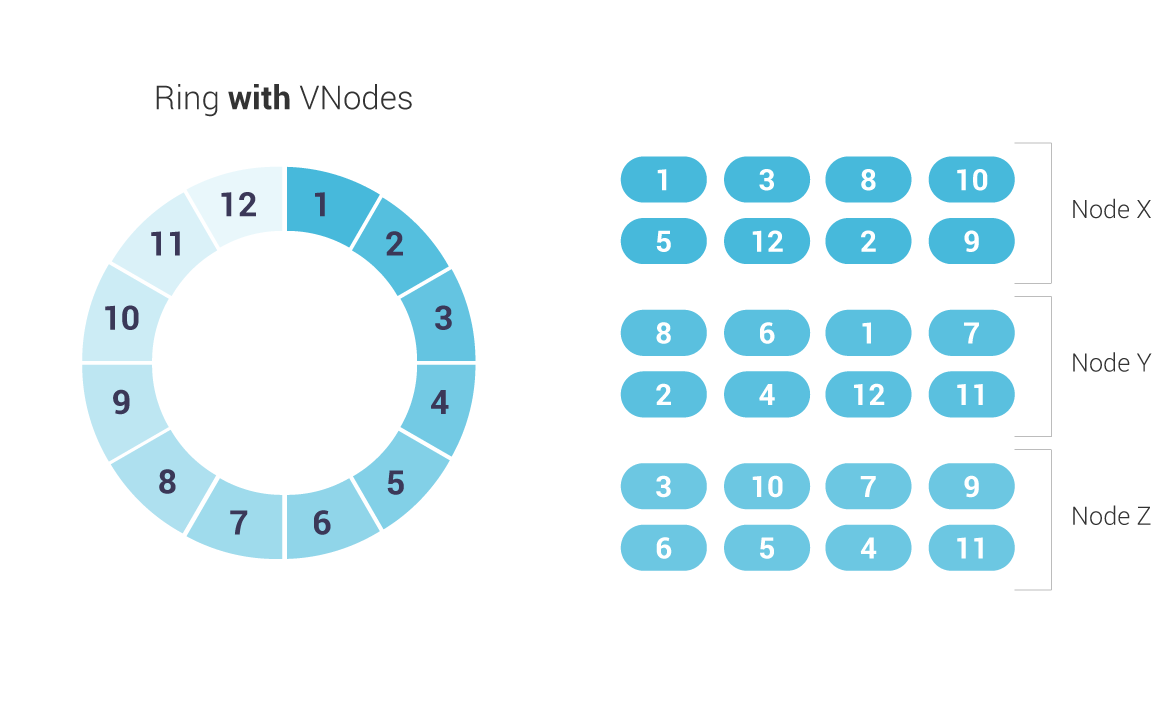
Ring Architecture
Next, you have the same underlying ring architecture. The key-key-value scheme of a wide column database: partition keys and clustering keys, then data columns.
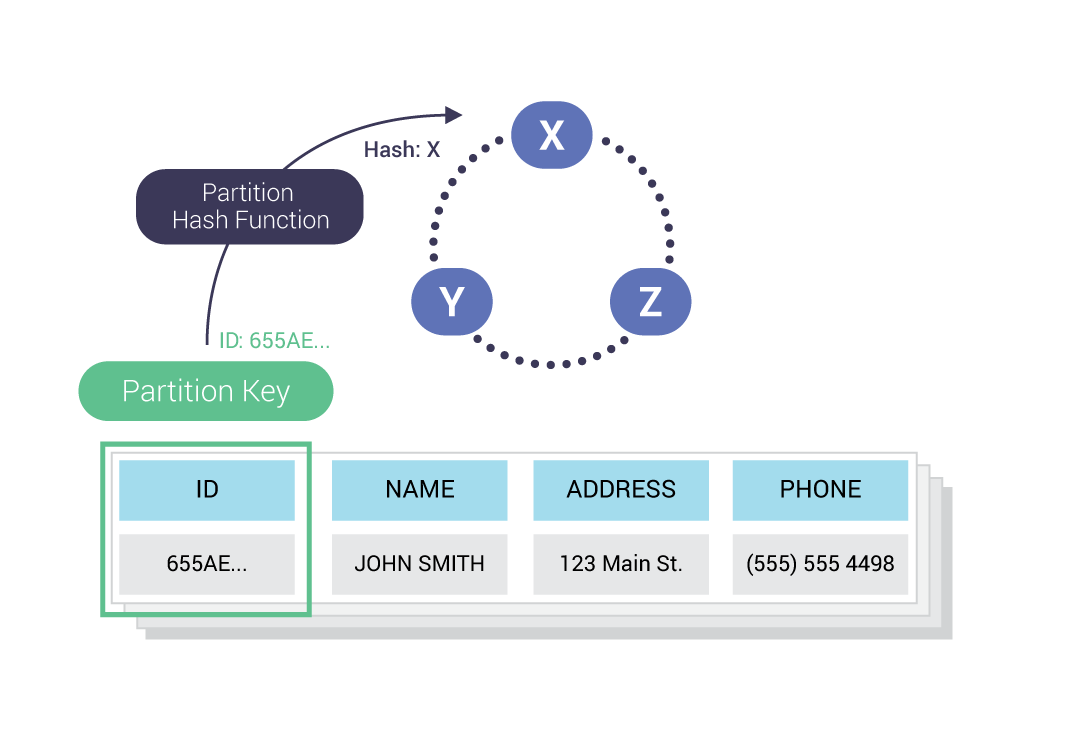
What else is the same? Nodes and vNodes, automatic sharding, token ranges, and the murmur3 partitioner. If you are familiar with managing Cassandra, all of this is all quite familiar. (Though if it’s not, you’re encouraged to take the Scylla Fundamentals course in Scylla University.)
What’s Similar But Not the Same?
While there are still more features that are alike, let’s not be exhaustive. Let’s move on to what seems similar between the two, but really are just not the same.
Cassandra Query Language (CQL)
That’s right. The Cassandra Query Language implementation itself is often subtly or not so subtly different. While the CQL wire protocol and most of the basic CQL commands are the same, you will note Scylla may have implemented some CQL commands that do not appear in Cassandra. Or vice versa.
There’s also version level completeness. For example, Cassandra’s CQL is, as of this writing, up to 3.4.5, while Scylla’s implementation is documented to only support 3.4.0.
What are the specific differences between them? I’ll let you scour the docs as a homework assignment. A careful eye might notice a few of the post-3.4.0 features have already been added to Scylla. For example, PER PARTITION LIMIT, a feature of CQL 3.4.2, was added to Scylla Open Source 3.1 and later.
Some of what you find may seem to be pretty trivial differences. But if you were migrating between the two databases, any unexpected discoveries might represent bumps in the road or unpleasant show-stoppers until Scylla finally reaches CQL parity and completeness again.
SSTables
Scylla is compatible with Cassandra 3.11’s latest “md” format. But did you spot the difference with Cassandra 4.0?
// na (4.0-rc1): uncompressed chunks, pending repair session, isTransient, checksummed sstable metadata file, new Bloomfilter format
// nb (4.0.0): originating host id
In the first release candidate of Cassandra 4.0 they snuck out the “na” format, which added a bunch of small changes. And then when 4.0 itself shipped, they added a way to store the originating hostID in “nb” format SSTable files.
We’ve opened up a Github issue (#8593) to make sure Scylla will have “na” and “nb” format compatibility in due time — but this is the sort of common, everyday feature chasing you’ll have whenever new releases of anything are spun, and everyone else needs to ensure compatibility. There’s always a little lag and gap time before implementation.
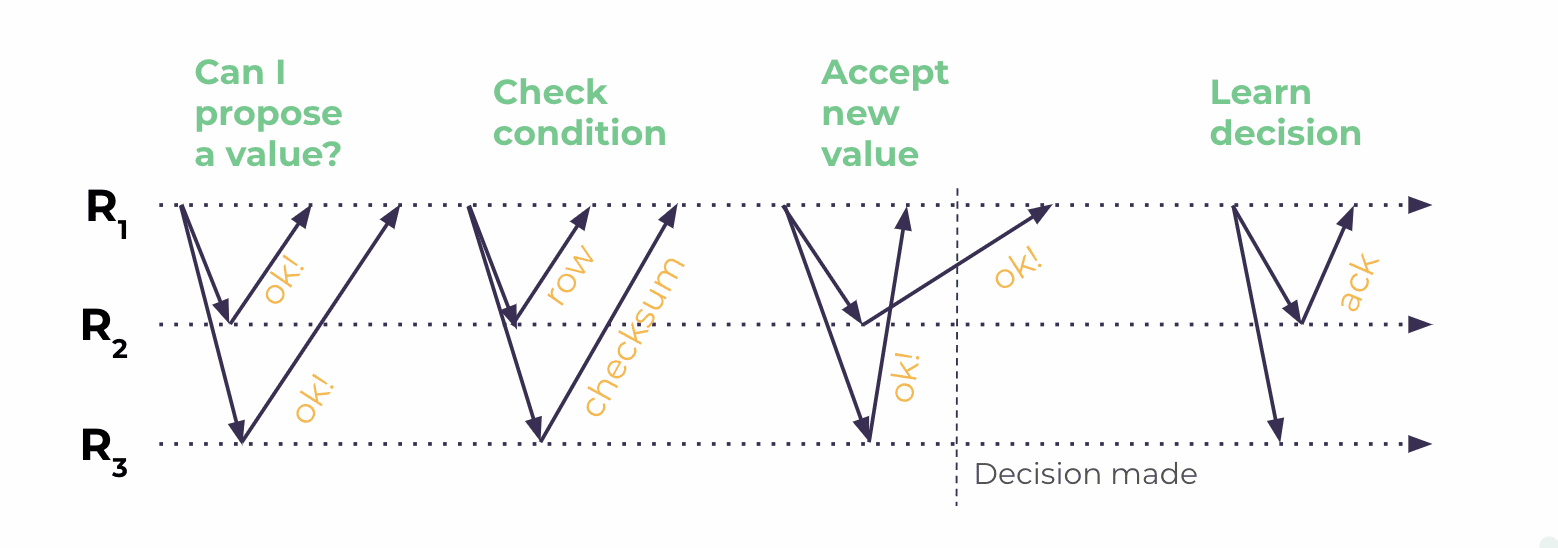
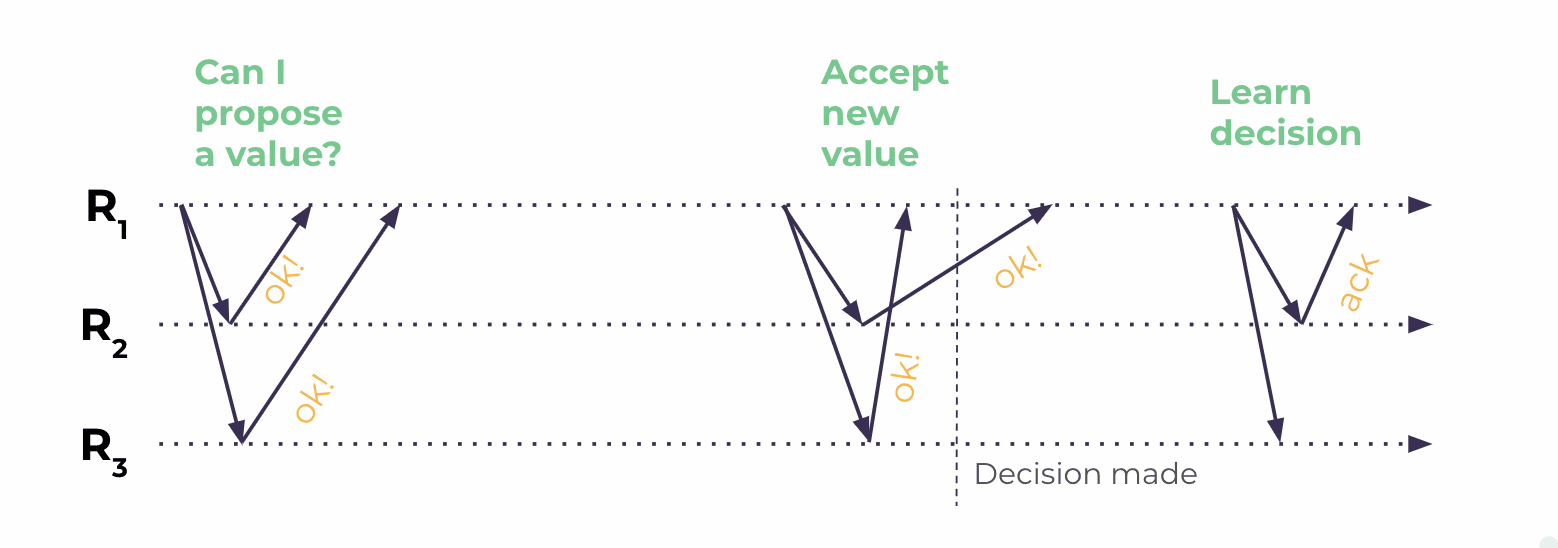
Lightweight Transactions
Lightweight Transactions, or LWTs, are pretty much the same sort of thing on both systems to do compare-and-set or conditional updates. But on Scylla they are simply more performant because instead of four round trips as with Cassandra, we only require three.
| Cassandra LWT Implementation | Scylla LWT Implementation |
 |
 |
What this has led to in practice is that some folks have tried LWT on Cassandra, only to back them out when performance tanked, or didn’t meet expectations. So if you experimented with LWTs in Cassandra, you might want to try them again with Scylla.
Materialized Views
Materialized Views, or MVs, are another case where Scylla put more polish into the apple. While Cassandra has had materialized views since 2017, they’ve been problematic since first introduced.
At Distributed Data Summit 2018 Cassandra PMC Chair Nate McCall told the audience that “If you have them, take them out.” I remember sitting in the audience absorbing the varied reactions as Nate spoke frankly and honestly about the shortcomings of the implementation.
Meanwhile, the following year Scylla introduced its own implementation of production-ready materialized views in Scylla Open Source 3.0. They served as the foundation for other features, such as secondary indexes.
While MVs in Scylla can still get out of sync from the base table, it is not as likely or easy to do. ScyllaDB engineers have poured a lot of effort over the past few years to get materialized views “right, ” and we consider the feature ready for production.
Secondary Indexes
Speaking of secondary indexes, while you have them in Cassandra, they are only local secondary indexes — limited to the same base partition. They are efficient but they don’t scale.
Global secondary indexes, which are only present in Scylla, allow you to index across your entire dataset, but can be more complicated and lead to unpredictable performance. That means you want to be more judicious about how and when you implement them.
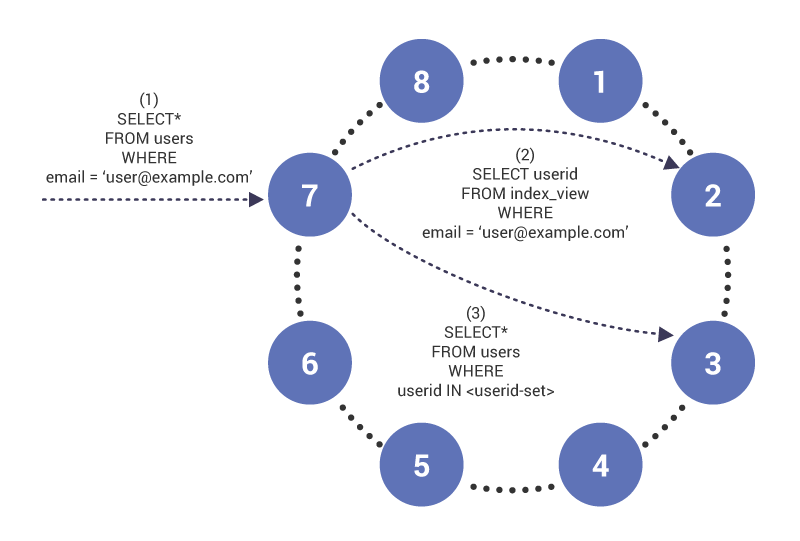
The good news is Scylla supports both local and global secondary indexes. You can apply both on a column to run your queries as narrow or as broad as you wish.
Change Data Capture
Change Data Capture, or CDC, is one of the most dramatic differences between Cassandra and Scylla. Cassandra implements CDC as a commitlog-like structure. Each node gets a CDC log, and then, when you want to query them, you have to take these structures off-box, combine them and dedupe them.
Think about the design decisions that went into Scylla’s CDC implementation. First, it uses a CDC table that resides on the same node as the base table data, shadowing any changes to those partitions. Those CDC tables are then queryable using standard CQL.
This means the results you get are already going to be deduped for you. There’s no log merges necessary. You get a stream of data, whether that includes the diffs, the pre-images, and/or the post-images. You can consume it however you want.
We also have a TTL set on the CDC tables so they don’t grow unbounded over time.

This made it very easy for us to implement a Kafka CDC Source Connector based on Debezium. It simply consumes the data from the CDC tables using CQL and pumps it out to Kafka topics. This makes it very easy to integrate Scylla into your event streaming architecture. No muss, no fuss. You can also read more about how we built our CDC Kafka connector using Debezium.
Zero Copy Streaming vs. Row-level Repair
Here’s another example of a point of departure. Cassandra historically had problems with streaming SSTables. This can be important when you are doing topology changes and you need to bring up or down nodes and rebalance your cluster. Zero copy streaming means you can take a whole SSTable — all of its partitions — and copy it over to another node without breaking an SSTable into objects, which creates unnecessary garbage that then needs to be collected. It also avoids bringing data into userspace on the transmitting and receiving nodes. Ideally this was to get you closer to hardware IO bounds.
Scylla, however, has already radically changed how it was going to do internode copying. We used row-level repairs instead of standard streaming methodology. This was more robust, allowing mid-point stops and restarts of transfers, was more granular — meaning you were only sending the needed rows instead of the entire table — and more efficient overall.
So these are fundamentally different ways to solve a problem. You can read how these different designs impacted topology change performance in our comparison of Cassandra 4.0 vs. Scylla 4.4.
--Async Messaging: Netty vs. AIO
Netty Async Messaging, new in Cassandra 4.0, is a good thing. Any way to avoid blocking and bottlenecking operations is awesome. Also, the way it does thread pools meant you weren’t setting a fixed number of threads per peer, which could mismatch actual real-world requirements.
Scylla has always believed in non-blocking IO. It is famous for its “async everywhere” C++ architecture. Plus, the shard-per-core design meant that you were minimizing inter-core communications as much as possible in the first place.
Again, these were good things. But for Cassandra async design was an evolutionary realization they wove into their existing design, whereas for Scylla it was a Day One design decision, which we’ve improved upon a lot since. You can read more about what we’ve learned over six years of IO scheduling.
In summation, both databases are sort of doing the same thing, but in very different ways.
Kubernetes
Cassandra now has a range of options for Kubernetes, from DataStax’ K8ssandra (which replaces the now-deprecated cass-operator), to KassCop by Orange, to Bitnami Charts.
For Scylla, we have our own Scylla Operator.
So yes, Kubernetes is available for both. But each operator is purpose-built for each respective database.
What’s Just Totally Different?
Now let’s look at things that are just simply… different. From fundamental design decisions to implementation philosophies to even the vision of what these database platforms are and can do.
Shard-per-Core Design
A critical Day One decision for Scylla was to build a highly distributed database upon a shared-nothing, shard-per-core architecture — the Seastar framework.
![]()
Scale it up, or scale it out, or both. Scylla is a “greedy system,” and is designed to make maximum utilization out of all the hardware you can throw at it.
Because of this, Scylla can take advantage of any size server. 100 cores per server? Sure. 1,000 cores? Don’t laugh. I know of a company working on a 2,000 core system. Such hyperscale servers will be available before you know it.
In comparison, Cassandra shards per node. Not per core. It also gets relatively low utilization out of the system it’s running in. That’s just the nature of a JVM — it doesn’t permit you knowledge of or control over the underlying hardware. This is why people seek to run multi-tenant in the box — to utilize all those cycles that Cassandra can’t harness.
As an aside, this is why attempts to often do an “apples-to-apples” comparison of Scylla to Cassandra on the same base hardware may often be skewed. Cassandra prefers running on low-density boxes, because it isn’t really capable of taking advantage of large scale multicore servers. However, Scylla hits its stride on denser nodes that Cassandra will fail to fully utilize. You can see this density partiality reflected on our “4 vs. 40” benchmark published earlier this year.
Shard-Aware CQL Drivers
While most of our focus has been on the core database itself, we also have a series of shard-aware drivers that provide you an additional performance boost. For example, check out our articles on our shard-aware Python driver — Part 1 discusses the design, and Part 2 the implementation and the performance improvements — as well as our Rust driver update and benchmarks.
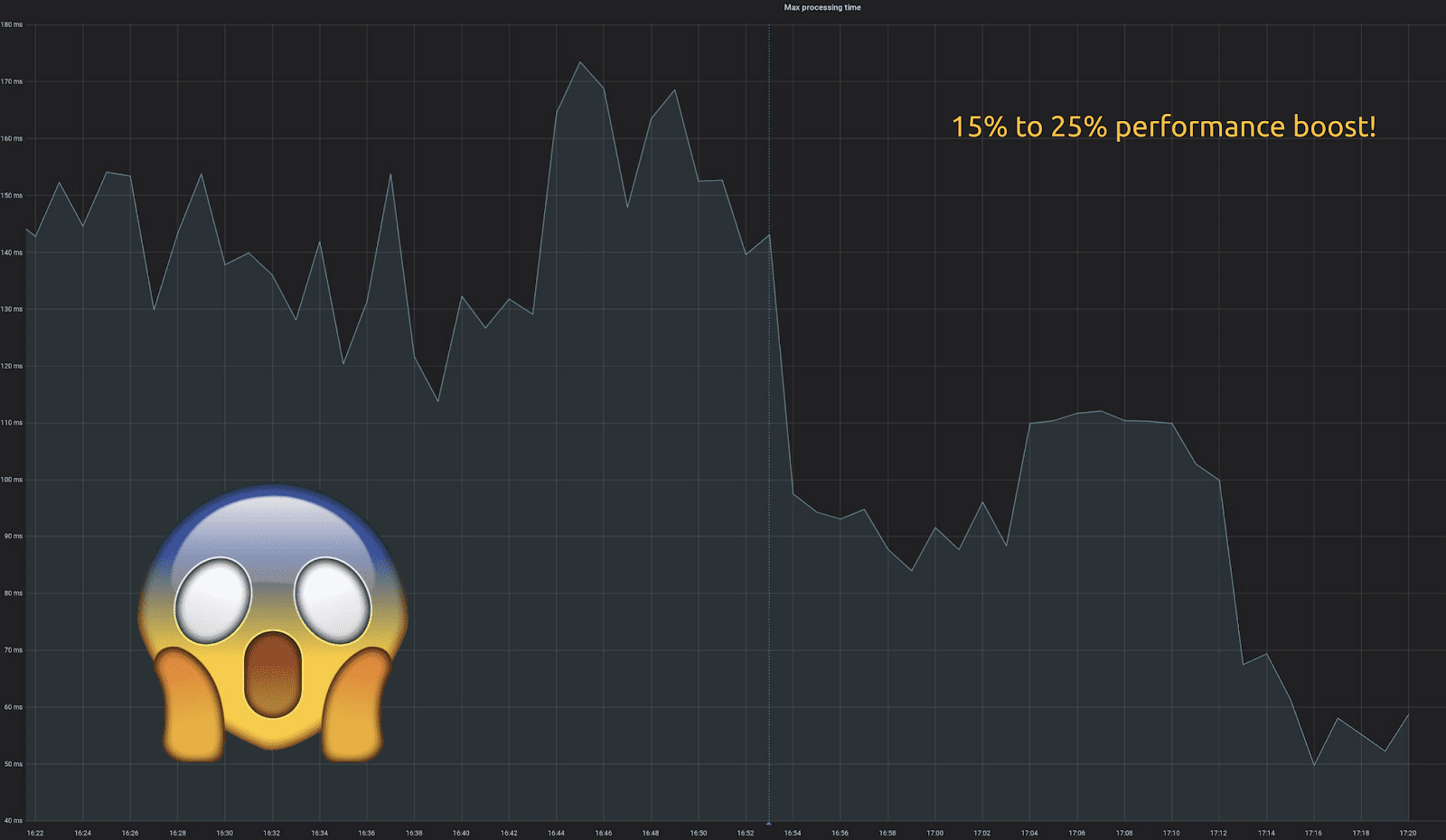
Scylla’s drivers are still backward compatible with Apache Cassandra. But when they are utilized with Scylla, they provide additional performance benefits — by as much as 15% to 25%.
Alternator: Scylla’s DynamoDB-compatible API
Alternator. It’s our name for the Amazon DynamoDB-compatible API we’ve built into Scylla. This means you now have freedom. You can still run your workloads on AWS, but you might find that you get a better TCO out of our implementation running on our Scylla Cloud Database-as-a-Service instead. Or you might use it to migrate your workload to Google Cloud, or Azure, or even put in on-premises.
An interesting example of the latter is AWS Outposts. These are cages with AWS servers installed in your own premises. These servers act as an on-premises extension of AWS.
Because we were capable of being deployed anywhere, Scylla Cloud was chosen as AWS’ service ready method to deploy your DynamoDB workloads directly into an AWS Outposts environment.
Using our CDC feature as the underlying infrastructure, we also support DynamoDB Streams. Plus, we have a load balancer to round out the same-same expectations of existing DynamoDB users. Lastly, our Scylla Spark Migrator makes it easy to take those DynamoDB workloads and place them wherever you desire.
Seedless Gossip
There are many, many other things I could have picked out, but I just wanted to show this as one more example of a “quality of life” feature for the database administrators.
Seedless gossip. There’s been a lot of pain and suffering if you lost a seed node. It requires manual assignment. Seed nodes won’t just bootstrap themselves. It can cause a lot of real-world, real-time frustrations when your cluster is at its most temperamental.

That’s why one of our engineers came up with the brilliant idea of just … getting rid of seed nodes entirely. We reworked the way gossip is implemented to be more symmetric and seamless. I hope you have a chance to read this article on how it was done; I promise…it’s pretty juicy!
Discover ScyllaDB for Yourself
This is just a cursory overview and a point-in-time glimpse of how Scylla 4.5 and Cassandra 4.0 are often feature-by-feature the same to maintain the greatest practical level of compatibility, how they sometimes differ slightly due to the logistics of keeping two different open source projects in sync or due to design or implementation decisions, and to point out explicitly how and when they sometimes diverge radically.
Yet however ScyllaDB engineers may have purposefully differed from Cassandra in design or implementation, it was always done with the hope that any changes we’ve made are in your favor, as the user, and not simply done as change for change’s sake.
If you have any questions on Scylla and Cassandra compatibility please contact us directly, or feel free to join our user Slack to ask your questions in our open source community.