Contact Us
Contact Us
Read More
10 results found
Featured
How Natura Uses ScyllaDB and ScyllaDB Connector to Create a Real-time Data Pipeline
Featured
Replacing RocksDB with ScyllaDB in Kafka Streams
Featured
How Supercell Handles Real-Time Persisted Events with ScyllaDB
Featured
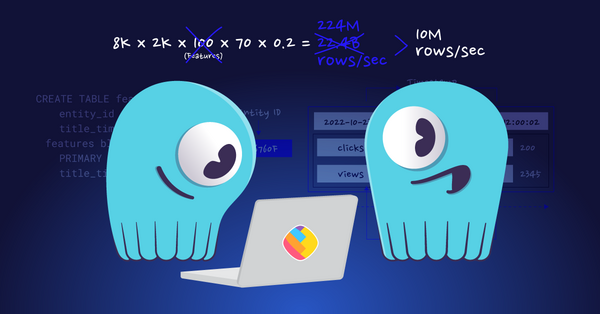
How ShareChat Scaled their ML Feature Store 1000X without Scaling the Database
Featured
How to Build a Real-Time CDC pipeline with ScyllaDB & Redpanda
Featured
Event-Driven Architectures Masterclass
Featured
Elasticity vs. State? A New Kafka Streams State Store
Featured
Cost-Efficient Stream Processing with RisingWave and ScyllaDB
Featured
Tracking Millions of Heartbeats on Zee’s OTT Platform
Featured
Real-Time Persisted Events at Supercell
Featured