AWS Graviton2: Arm Brings Better Price-Performance than Intel
Since the last time we took a look at Scylla’s performance on Arm, its expansion into the desktop and server space has continued: Apple introduced its M1 CPUs, Oracle Cloud added Ampere Altra-based instances to its offerings, and AWS expanded its selection of Graviton2-based machines. So now’s a perfect time to test Arm again — this time with SSDs.
Summary
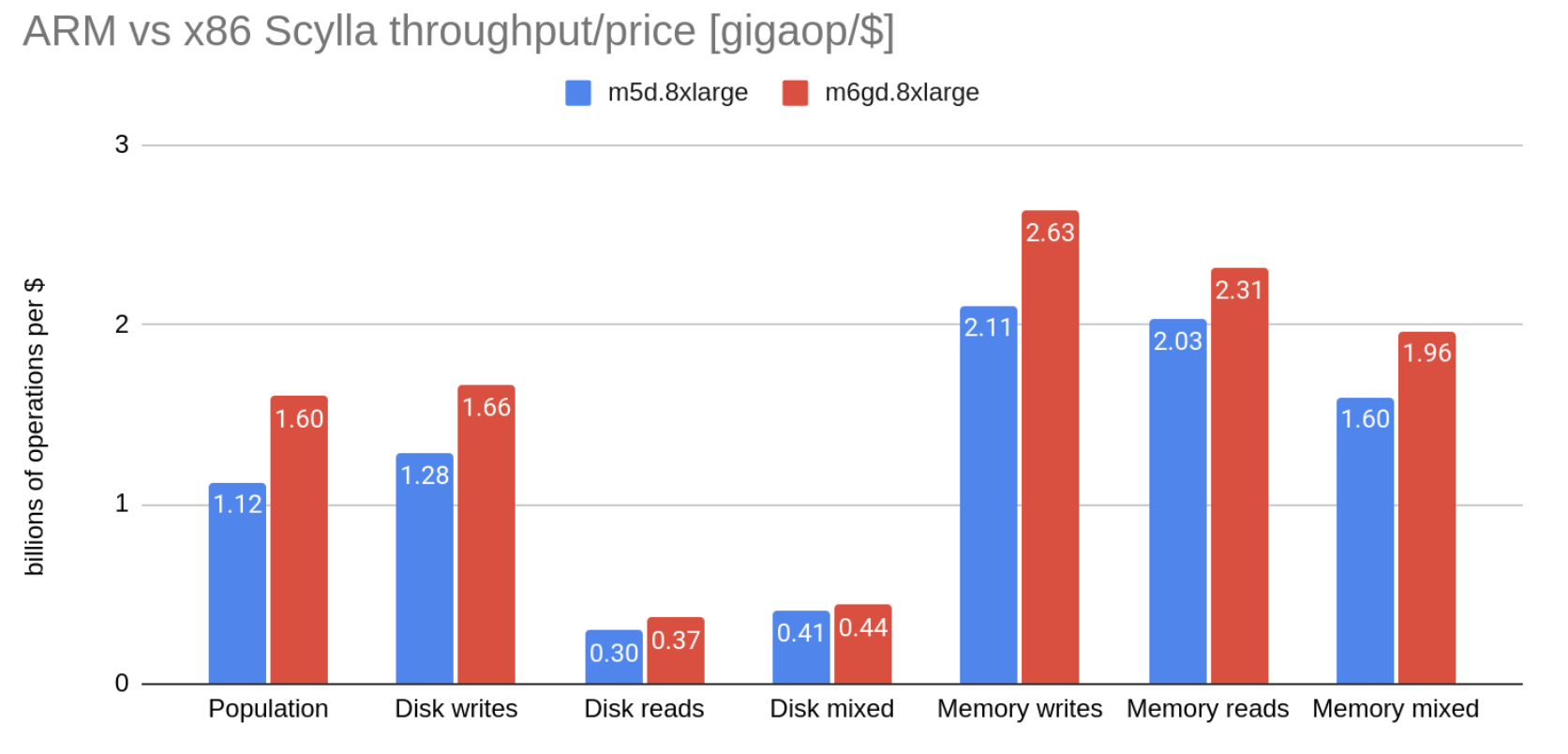
We compared Scylla’s performance on m5d (x86) and m6gd (Arm) instances of AWS. We found that Arm instances provide 15%-25% better price-performance, both for CPU-bound and disk-bound workloads, with similar latencies.
Compared machines
For the comparison we picked m5d.8xlarge and m6gd instances, because they are directly comparable, and other than the CPU they have very similar specs:
| Intel (x86-Based) Server | Graviton2 (Arm-based) Server | |
| Instance type | m5d.8xlarge | m6gd.8xlarge |
| CPUs | Intel Xeon Platinum 8175M (16 cores / 32 threads) |
AWS Graviton2 (32 cores) |
| RAM | 128 GB | 128 GB |
| Storage (NVMe SSD) | 2 x 600 GB (1,200 GB Total) | 1 x 1,900 GB |
| Network bandwidth | 10 Gbps | 10 Gbps |
| Price/Hour (us-east-1) | $1.808 | $1.4464 |
For m5d, both disks were used as one via a software RAID0.
Scylla’s setup scripts benchmarked the following stats for the disks:
| m5d.8xlarge read_iops: 514 k/s read_bandwidth: 2.502 GiB/s write_iops: 252 k/s write_bandwidth: 1.066 GiB/s |
m6d.8xlarge read_iops: 445 k/s read_bandwidth: 2.532 GiB/s write_iops: 196 k/s write_bandwidth: 1.063 GiB/s |
Their throughput was almost identical, while the two disks on m5d provided moderately higher IOPS.
Note: “m” class (General Purpose) instances are not the typical host for Scylla. Usually, “I3” or “I3en” (Storage Optimized) instances, which offer a lower cost per GB of disk, would be chosen. However there are no Arm-based “i”-series instances available yet.
While this blog was being created, AWS released a new series of x86-based instances — the m6i — which boasts up to 15% improved price performance over m5. However, they don’t yet have SSD-based variants, so would not be a platform recommended for use with a low latency persistent database system like Scylla.
Benchmark Details
For both instance types, the setup consisted of a single Scylla node, 5 client nodes (c5.4xlarge) and 1 Scylla Monitoring node (c5.large), all in the same AWS availability zone.
Scylla was launched on 30 shards with 2GiB of RAM per shard. The remaining CPUs (2 cores for m6gd, 1 core with 2 threads for m5d) were dedicated to networking. Other than that, Scylla AMI’s default configuration was used.
The benchmark test we used was cassandra-stress, with a Scylla shard-aware driver. This version of cassandra-stress is distributed with Scylla. The default schema of cassandra-stress was used.
The benchmark consisted of six phases:
- Populating the cluster with freshly generated data.
- Writes (updates) randomly distributed over the whole dataset.
- Reads randomly distributed over the whole dataset.
- Writes and reads (mixed in 1:1 proportions) randomly distributed over the whole dataset.
- Writes randomly distributed over a small subset of the dataset.
- Reads randomly distributed over a small subset of the dataset.
- Writes and reads (mixed in 1:1 proportions) randomly distributed over a small subset of the dataset.
Phase 1 was running for as long as needed to populate the dataset, phase 2 was running for 30 minutes, and other phases were running for 15 minutes. There was a break after each write phase to wait for compactions to end.
The size of the dataset was chosen to be a few times larger than RAM, while the “small subset” was chosen small enough to fit entirely in RAM. Thus phases 1-4 test the more expensive (disk-touching) code paths, while phases 5-7 stress the cheaper (in-memory) paths.
Note that phases 3 and 4 are heavily bottlenecked by disk IOPS, not by the CPU, so their throughput is not very interesting for the general ARM vs x86 discussion. Phase 2, however, is bottlenecked by the CPU. Scylla is a log-structured merge-tree database, so even “random writes” are fairly cheap IO-wise.
Results
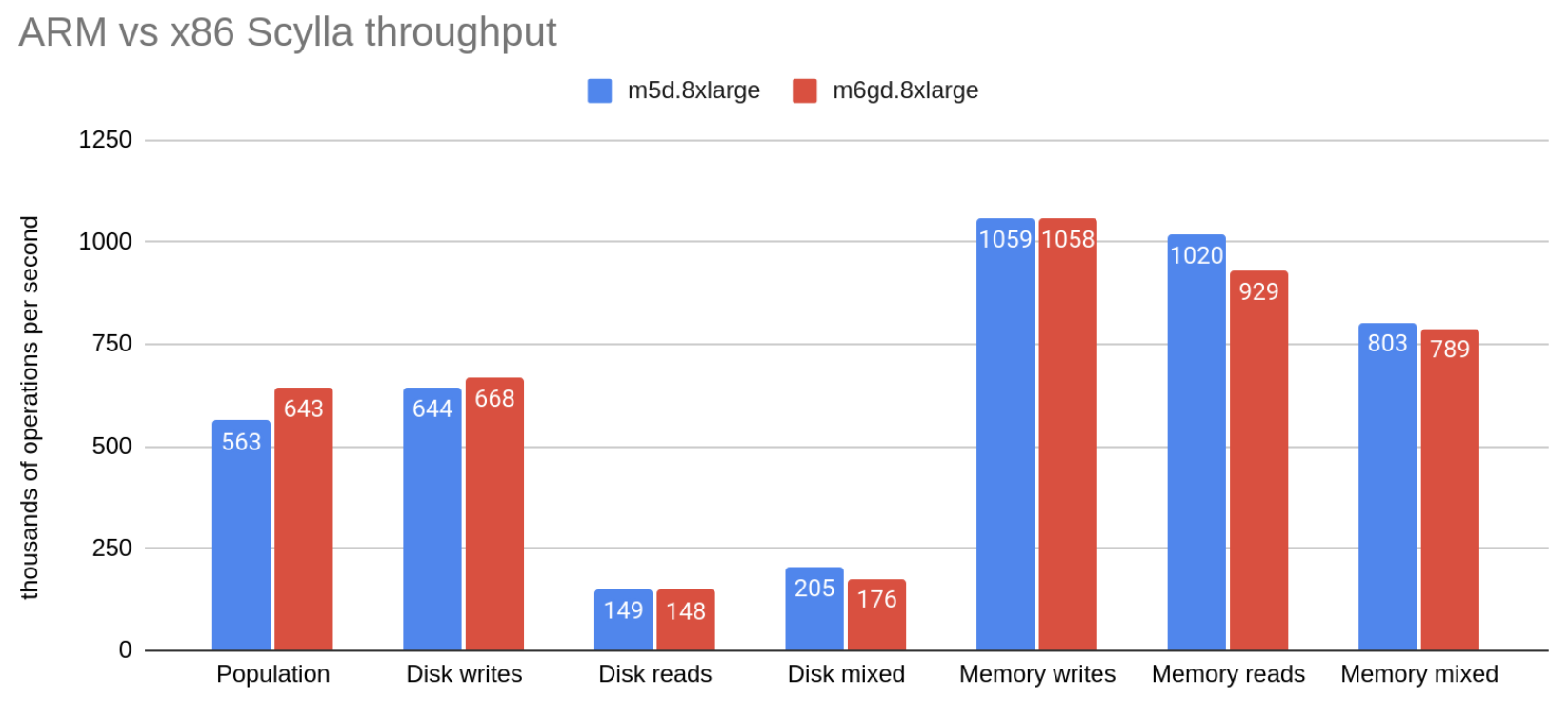
| Phase | m5d.8xlarge kop/s | m6gd.8xlarge kop/s | difference in throughput | difference in throughput/price |
| 1. Population | 563 | 643 | 14.21% | 42.76% |
| 2. Disk writes | 644 | 668 | 3.73% | 29.66% |
| 3. Disk reads | 149 | 148 | -0.67% | 24.16% |
| 4. Disk mixed | 205 | 176 | -14.15% | 7.32% |
| 5. Memory writes | 1059 | 1058 | -0.09% | 24.88% |
| 6. Memory reads | 1046 | 929 | -8.92% | 13.85% |
| 7. Memory mixed | 803 | 789 | -1.74% | 22.82% |
We see roughly even performance across both servers, but because of the different pricing, this results in a ~20% price-performance advantage overall for m6gd. Curiously, random mixed read-writes are significantly slower on m6gd, even though both random writes and random reads are on par with m5d.
Service Times
The service times below were measured on a separate run, where cassandra-stress was fixed at 75% of the maximum throughput.
| m5d p90 | m5d p99 | m5d p999 | m5d p9999 | m6gd p90 | m6gd p99 | m6gd p999 | m6gd p9999 | |
| Disk writes | 1.38 | 2.26 | 9.2 | 19.5 | 1.24 | 2.04 | 9.5 | 20.1 |
| Disk reads | 1.2 | 2.67 | 4.28 | 19.2 | 1.34 | 2.32 | 4.53 | 19.1 |
| Disk mixed (write latency) |
2.87 | 3.9 | 6.48 | 20.4 | 2.78 | 3.58 | 7.97 | 32.6 |
| Disk mixed (read latency) |
0.883 | 1.18 | 4.33 | 13.9 | 0.806 | 1.11 | 4.05 | 13.7 |
| Memory writes | 1.43 | 2.61 | 11.7 | 23.7 | 1.23 | 2.8 | 13.2 | 25.7 |
| Memory reads | 1.09 | 2.48 | 11.6 | 24.6 | 0.995 | 2.32 | 11 | 24.4 |
| Memory mixed (read latency) |
1.01 | 2.22 | 10.4 | 24 | 1.12 | 2.42 | 10.8 | 24.2 |
| Memory mixed (write latency) |
0.995 | 2.19 | 10.3 | 23.8 | 1.1 | 2.37 | 10.7 | 24.1 |
No abnormalities. The values for both machines are within 10% of each other, with the one notable exception of the 99.99% quantile of “disk mixed.”
Conclusion
AWS’ Graviton2 ARM-based servers are already on par with x86 or better, especially for price-performance, and continue to improve generation-after-generation.
By the way, Scylla doesn’t have official releases for Arm instances yet, but stay tuned. Their day is inevitably drawing near. If you have any questions about running Scylla in your own environment, please contact us via our website, or reach out to us via our Slack community.