Contact Us
Contact Us
Read More
10 results found
Featured
Scaling Freshworks’ AI Data Platform with ScyllaDB
Featured
We Built a Better Cassandra + ScyllaDB Driver for Node.js – with Rust
Featured
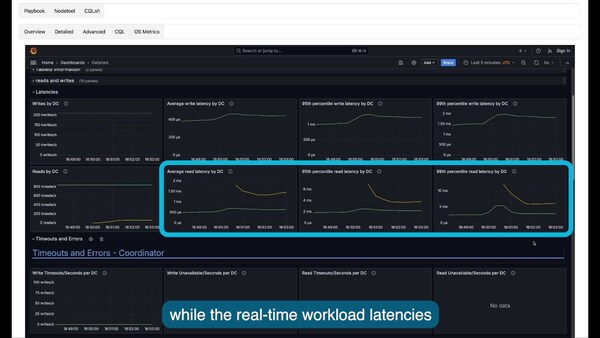
Scaling Performance Comparison: ScyllaDB Tablets vs Cassandra vNodes
Featured
How SAS and Freshworks Power Real-Time Personalization at Extreme Scale
Featured
Cassandra vs. ScyllaDB: Evolutionary Differences
Featured
Beyond Apache Cassandra
Featured
ScyllaDB vs Cassandra: 5 Minute Demo
Featured
Inside Freshworks’ Migration from Cassandra to ScyllaDB
Featured
ScyllaDB is No Longer “Just a Faster Cassandra”
Featured
Inside Tripadvisor’s Real-Time Personalization with ScyllaDB + AWS
Featured