Why ScyllaDB is Moving to a New Replication Algorithm: Tablets
How moving from Vnode-based replication to tablets helps dynamically distribute data across the cluster, ultimately increasing ScyllaDB’s elasticity.
Like Apache Cassandra, ScyllaDB has historically decided on replica sets for each partition using Vnodes. The Vnode-based replication strategy tries to evenly distribute the global token space shared by all tables among nodes and shards. It’s very simplistic. Vnodes (token space split points) are chosen randomly, which may cause an imbalance in the actual load on each node. Also, the allocation happens only when adding nodes, and it involves moving large amounts of data, which limits its flexibility. Another problem is that the distribution is shared by all tables in a keyspace, which is not efficient for relatively small tables, whose token space is fragmented into many small chunks.
ScyllaDB now has initial support for a new replication algorithm: tablets. It’s currently in experimental mode.
Tablets allow each table to be laid out differently across the cluster. With tablets, we start from a different side. We divide the resources of the replica-shard into tablets, with a goal of having a fixed target tablet size, and then assign those tablets to serve fragments of tables (also called tablets). This will allow us to balance the load in a more flexible manner by moving individual tablets around. Also, unlike with Vnode ranges, tablet replicas live on a particular shard on a given node, which will allow us to bind Raft groups to tablets.
This new replication algorithm allows each table to make different choices about how it is replicated and for those choices to change dynamically as the table grows and shrinks. It separates the token ownership from servers – ultimately allowing ScyllaDB to scale faster and in parallel.
Tablets require strong consistency from the control plane; this is provided by Raft. We talked about this detail in the ScyllaDB Summit talk below (starting at 17:26).
Raft vs Lightweight Transactions for Strongly Consistent Tables
ScyllaDB is in the process of bringing the technology of Raft to user tables and allows users to create strongly consistent tables which are based on Raft. We already provide strong consistency in the form of lightweight transactions, which are Paxos-based, but they have several drawbacks. Generally, lightweight transactions are slow. They require three rounds to replicas for every request and they have poor scaling if there are conflicts between transactions. If there are concurrent conflicting requests, the protocol will retry due to conflict. As a result, they may not be able to make progress. This will not scale well.
Raft doesn’t suffer from this issue. First and foremost, it requires only one round to replicas per-request when you’re on leader or less because it can batch multiple commands in a single request. It also supports pipelining, meaning that it can keep sending commands without waiting for previous commands to be acknowledged. The pipelining goes down to a single CPU on which every following state machine runs. This leads to high throughput.
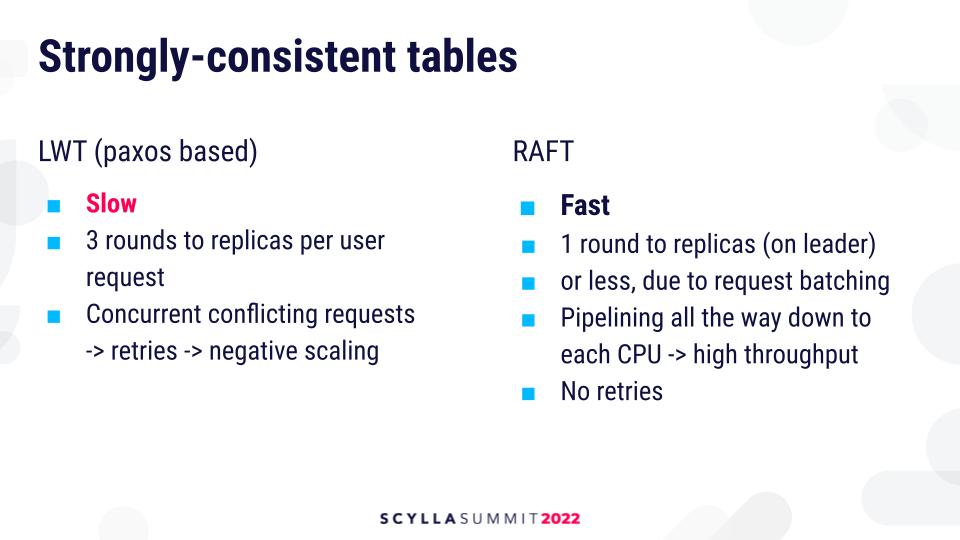
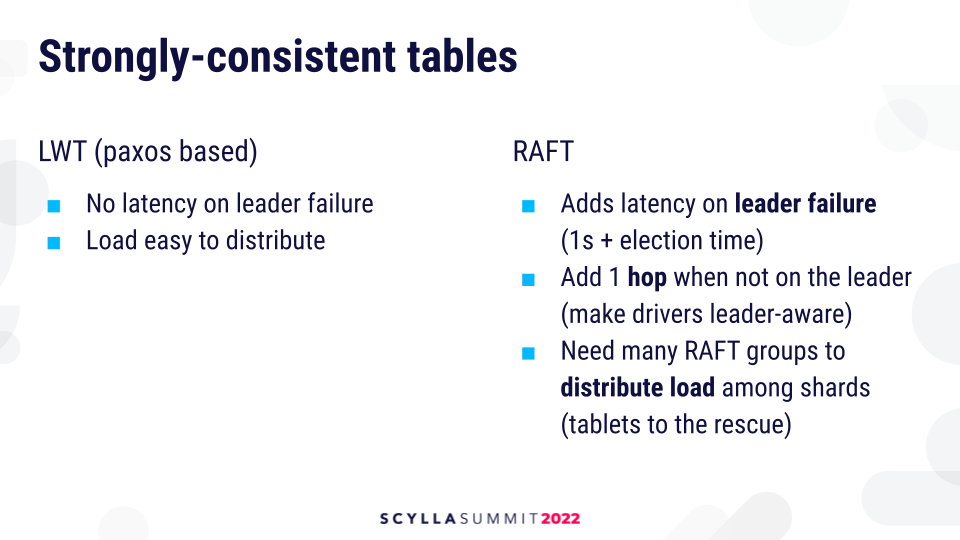
But, Raft also has drawbacks in this context. Because there is a single leader, Raft tables may experience latency when the leader dies because the leader has to undergo a failover. Most of the delay is actually due to detection latency because Raft doesn’t switch the leader back and forth so easily. It waits for 1 second until it decides to elect a new leader. Lightweight transactions don’t have this, so they are theoretically more highly available.
Another problem with Raft is that you have to have an extra hop to the leader when the request starts executing not on the leader. This can be remedied by improving drivers to make them leader-aware and route requests to the leader directly. Also, Raft tables require a lot of Raft groups to distribute load among shards evenly. That’s because every request has to go through a single CPU, the leader, and you have to have many such leaders in order to have even load. Lightweight transactions are much easier to distribute.
Balancing the Data Across the Cluster
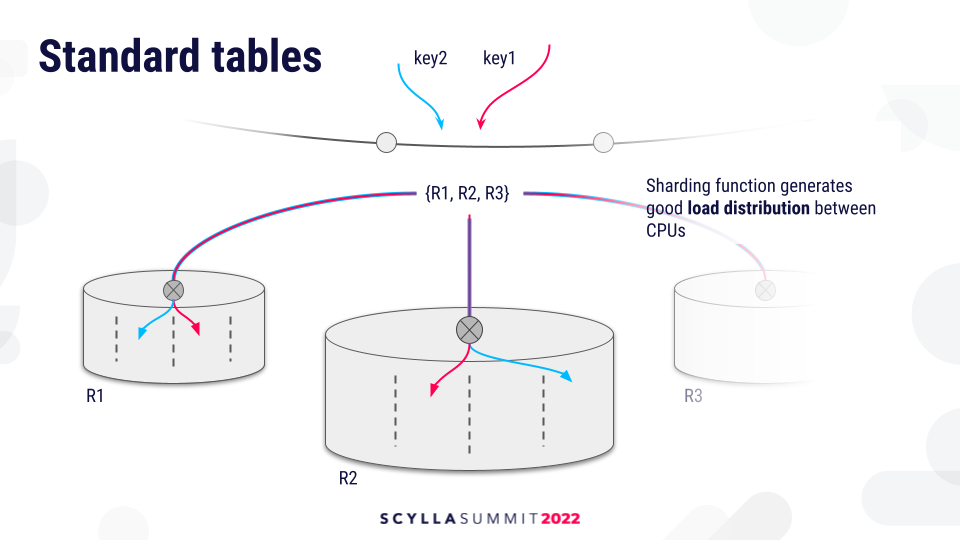
So let’s take a closer look at this problem. This is how load is distributed currently using our standard partitioning (the Vnode partitioning), which also applies to tables which use lightweight transactions.

Replication metadata, which is per keyspace, determines the set of replicas for a given key. The request then is routed to every replica. On that replica there is a sharding function which picks the CPU in which the request is served, which owns the data for a given key. The sharding function makes sure that the keys are evenly distributed among CPUs, and this provides good load distribution.
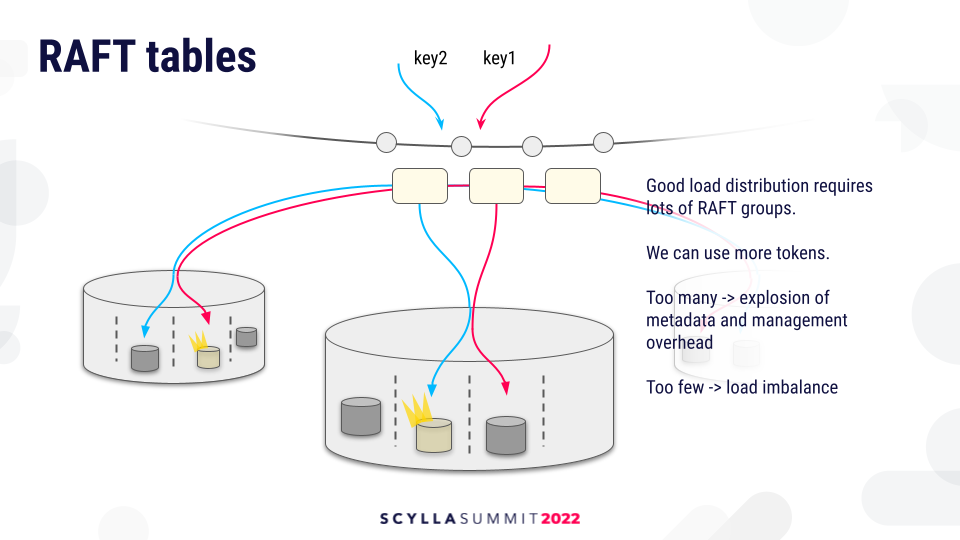
The story with Raft is a bit different because there is no sharding function which is applied on the replica. Every request which goes to a given Raft group will go to a fixed set of Raft state machines and Raft leader, and their location of CPUs is fixed.
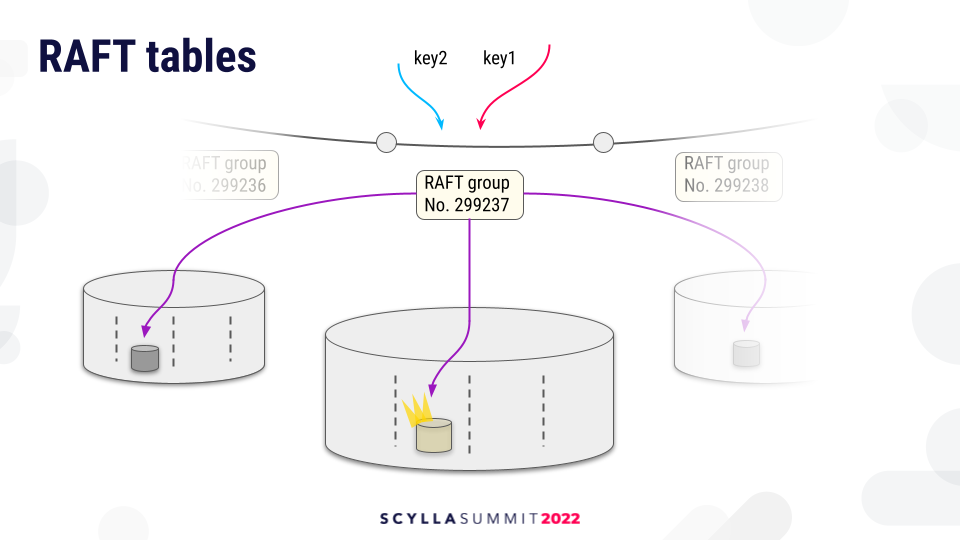
They have a fixed shard, so the load distribution is not as good as with the sharding function with standard tables.
We could remedy the situation by creating more tokens inside the replication metadata so that we have more ranges and more narrow ranges. However, this creates a lot of Raft groups, which may lead to explosion of metadata and management overhead because of Raft groups.
The solution to this problem depends on another technology: tablet partitioning.
Tablet Partitioning
In tablet partitioning, replication metadata is not per keyspace. Every table has a separate replication metadata. For every table, the range of keys (as with Vnode partitioning) is divided into ranges, and those ranges are called tablets. Every tablet is replicated according to the replication strategy, and the replicas live on a particular shard on the owning node. Unlike with Vnodes, requests will not be routed to nodes which then independently decide on the assignment of the key to the shard, but will rather be routed to specific shards.
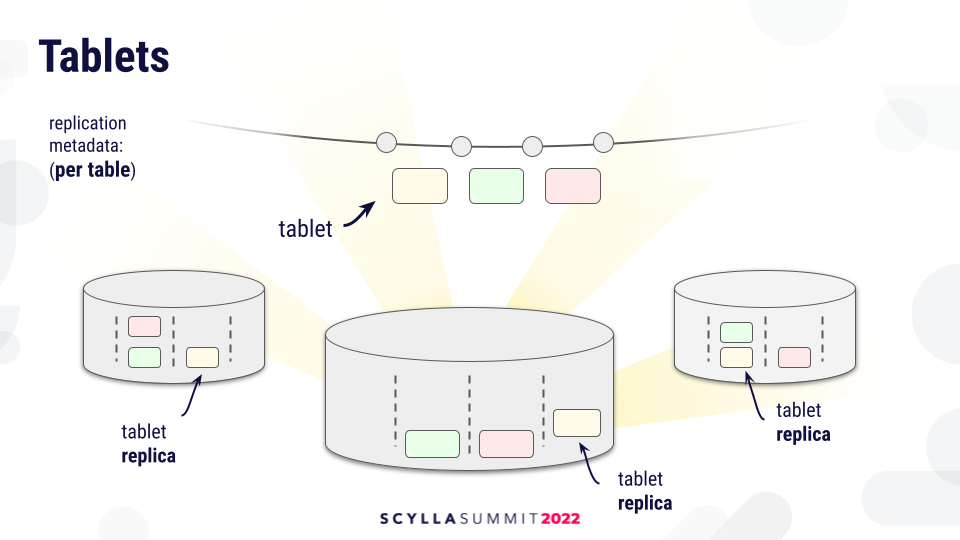
This will give us more control over where data lives, which is managed centrally. This gives us finer control over the distribution of data.
The system will aim to keep the tablets at a manageable size. With too many small tablets, there’s a lot of metadata overhead associated with having tablets. But with too few large tablets, it’s more difficult to balance the load by moving tablets around. A table will start with just a few tablets. For small tables, it may end there. This is a good thing, because unlike with the Vnode partitioning, the data will not be fragmented into many tiny fragments, which adds management overhead and also negatively impacts performance. Data will be localized in large chunks which are easy to process efficiently
As tables grow, as they accumulate data, eventually they will hit a threshold, and will have to be split. Or, the tablet becomes popular with requests hitting it, and it’s beneficial to split it and redistribute the two parts so that the load is more evenly distributed.
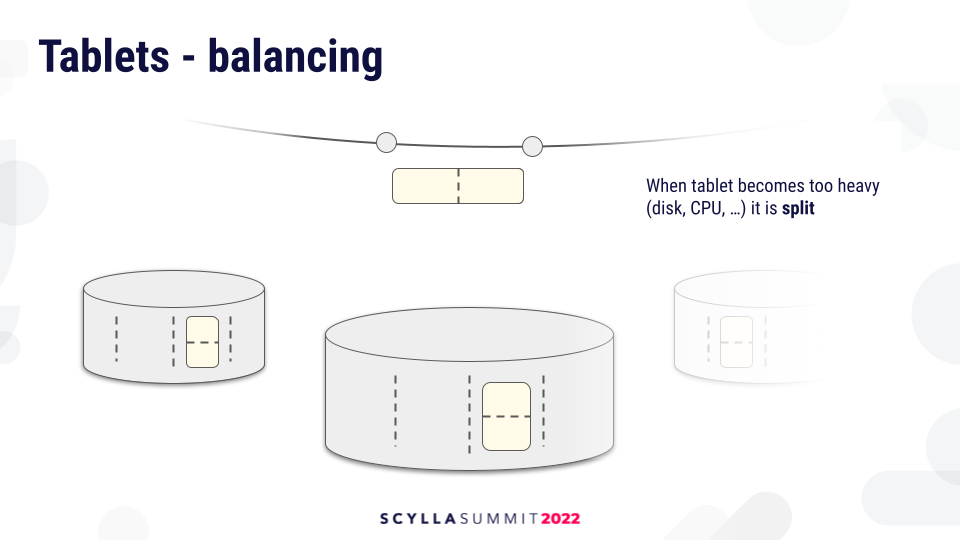
The tablet load balancer decides where to move the tablets, either within the same node to balance the shards or across the nodes to balance the global load in the cluster. This will help to relieve overloaded shards and balance utilization in the cluster, something which current Vnode partitioner cannot do.
This depends on fast, reliable, fault-tolerant topology changes because this process will be automatic. It works on small increments and can be happening more frequently than current node operations.
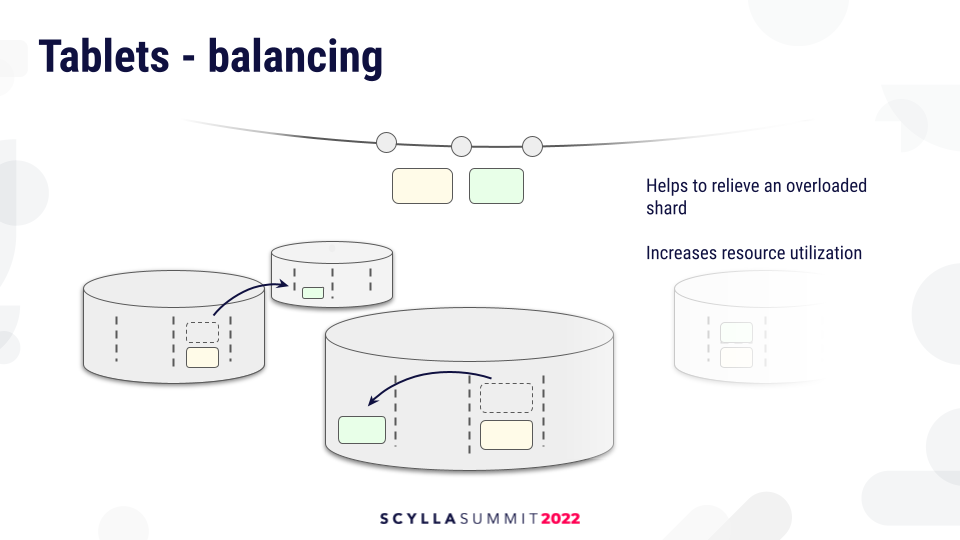
Tablets also help us implement Raft tables. Every Raft group will be associated with exactly one tablet, and the Raft servers will be associated with tablet replicas. Moving a tablet replica also moves the associated Raft server.
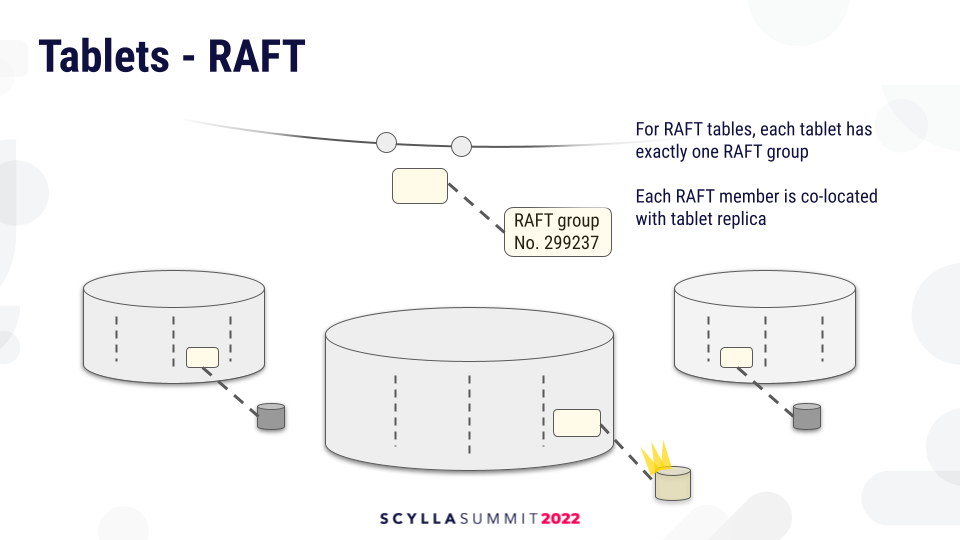
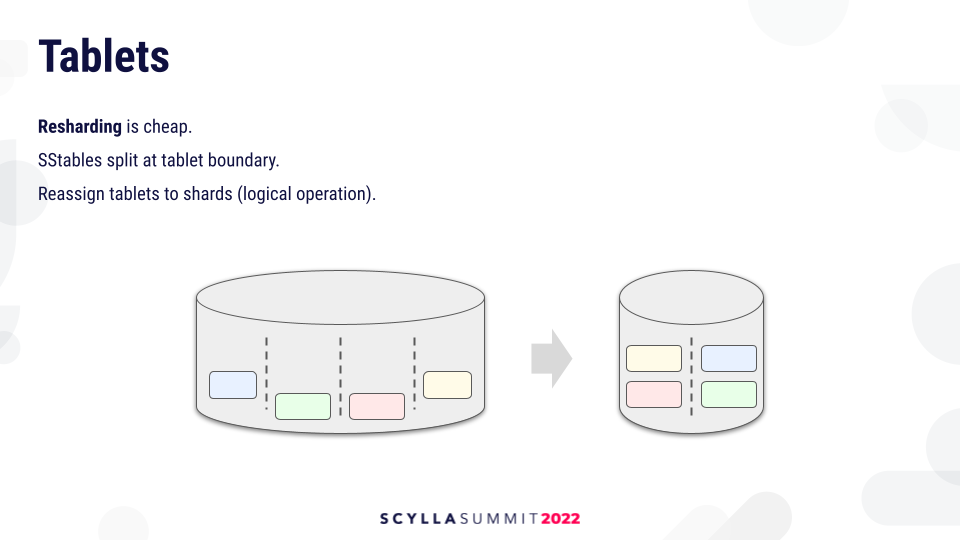
Additional Benefits: Resharding and Cleanup
Turns out the tablets will also help with other things. For example, resharding will be very cheap. SSTables are split at the tablet boundary, so resharding is only a logical operation which reassigns tablets to shards.
Cleanup is also cheap because cleaning up all data after a topology change is just about deleting the SSTable – there’s no need to rewrite them.
More from ScyllaDB Engineering
Want to learn more about what ScyllaDB engineers have been doing with Raft, Rust,and IO scheduling and more – plus what they’re working on next – take a look at our library of engineering tech talks and blog.