What’s Next on ScyllaDB’s Path to Strong Consistency
We explored the Raft capabilities introduced in ScyllaDB 5.2 in the blog ScyllaDB’s Path to Strong Consistency: A New Milestone. Now let’s talk about what’s coming next: Raft-based consistent and centralized topology management. Topology changes will be safe and fast: we won’t be bound by ring delay any longer, and operator mistakes won’t corrupt the cluster.
Limitations We Plan to Address
Right now, our documentation says that:
- You can’t perform more than one topology operation at a time, even when the cluster is empty
- A failure during a topology change may lead to lost writes
- Topology operations take time, even if streaming is quick
The topology change algorithm uses a sleep period configured in ring_delay to ensure that the old topology propagates through the cluster before it starts being used. During this period all reads and writes, which are based on the old topology, are expected to have quiesced. However, if this is not the case, the topology operation moves on, so it’s not impossible that a lost or resurrected write corrupts the database state.
Cassandra calls this approach “probabilistic propagation.” In most cases, by the end of ring delay the cluster is aware of the new state. Its key advantage is liveness – the algorithm operates within any subset of the original cluster. However, as discussed in the previous blog post, the price paid is the speed of information dissemination and consistency issues. And the extreme liveness characteristics are unnecessary anyway: given the scale ScyllaDB typically operates at, it’s OK to require a majority of nodes to be alive at any given time. Using Raft to propagate token ring information would permit establishing a global order of state change events, detect when concurrent operations intersect, and provide transactional semantics of topology changes.
I am very happy that the Cassandra community has also recognized the problem and there is Cassandra work addressing the same issues.
Moving Topology Data to Raft
Here’s what we achieve by moving topology data to Raft:
- Raft group includes all cluster members
- Token metadata is replicated using Raft
- No stale topology
Let’s explore in more detail.
The Centralized Coordinator
In our centralized topology implementation, we were able, to a significant extent, to address all of the above. The key change that allowed us to do the transition was a turnaround in the way topology operations are performed.
Before, the node that is joining the cluster would drive the topology change forward. If anything would happen to that node, the failure would need to be addressed by the DBA. In the new implementation, a centralized process (which we call the topology change coordinator) runs alongside the Raft cluster leader node and will drive all topology changes.
Before, the state of the topology, such as tokens, was propagated through gossip and eventually consistent. Now, the state is propagated through Raft, replicated to all nodes and is strongly consistent. A snapshot of this data is always available locally, so that starting nodes can quickly obtain the topology information without reaching out to the leader of the Raft group.
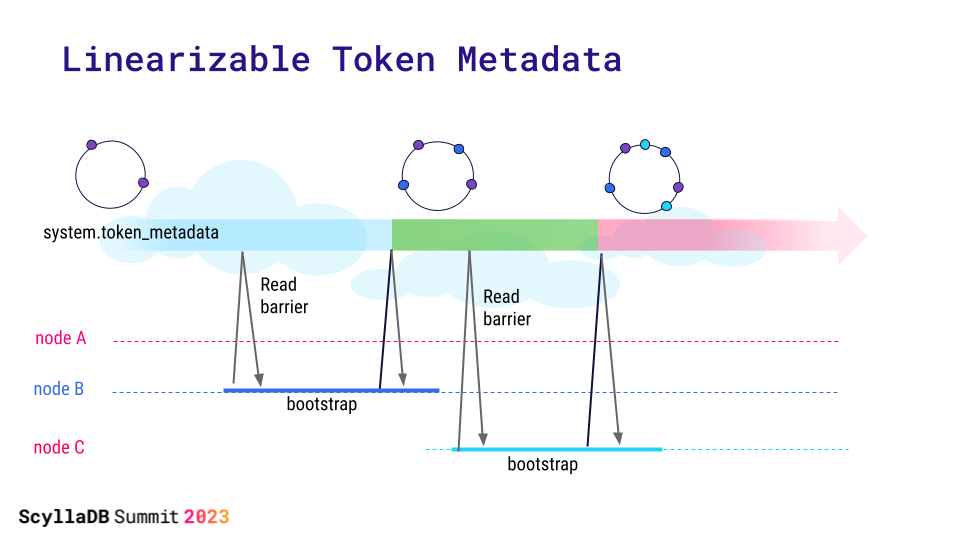
Linearizable Token Metadata
Even if nodes start concurrently, token metadata changes are now linearized. Also, the view of token metadata at each node is not dependent on the availability of the owner of the tokens. Node C is fully aware of node B tokens (even if node B is down) when it bootstraps.
Automatic Coordinator Failover
But what if the coordinator fails? Topology changes are multi-step sagas. If the coordinator dies, the saga could stall or the topology change would remain incomplete. Locks could be held blocking other topology changes. Automatic topology changes (e.g. load balancing) cannot wait for admin intervention. We need fault-toleranсe.
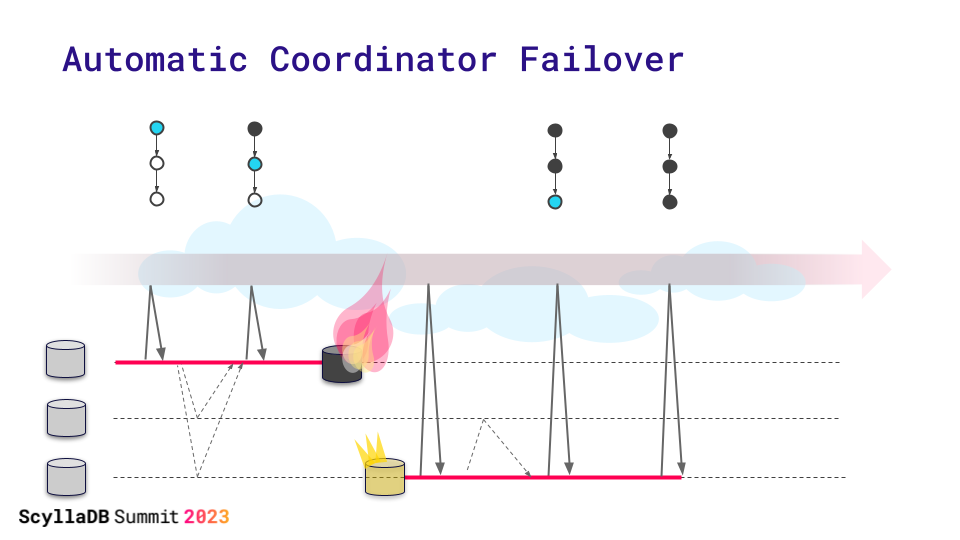
A new coordinator follows the Raft group0 leader and takes over from where the previous one left off. The state of the process is in a fault-tolerant linearizable storage. As long as a quorum is alive, we can make progress.
Change in the Data Plane
There’s also a new feature, which we call fencing, on the read/write path. Each read or write in ScyllaDB is now signed with the current topology version of the coordinator performing the read or write. If the replica has newer, incompatible topology information, it responds with an error, and the coordinator refreshes its ring and re-issues the query to new, correct replicas. If the replica has older information, which is incompatible with the coordinator’s version, it refreshes its topology state before serving the query.

We plan to extend the fencing all the way down to ScyllaDB drivers, which can now protect their queries with the most recent fencing token they know. This will make sure that drivers never perform writes based on an outdated topology, and, for schema changes, will make sure that a write into a newly created table never fails with “no such table” because the schema didn’t propagate yet.
With fencing in place, we are able to avoid waiting for ring delays during topology operations, making them quick, more testable, and more reliable. We also resolve consistency anomalies which are not impossible during topology changes.
Summary: What to Expect in Next
So let me summarize what we plan to deliver next:
- While you can’t perform multiple topology operations concurrently, *requesting* multiple operations will now also be safe. The centralized coordinator will queue the operations, if they are compatible.
- Incorrect operations, such as removing and replacing the same node at the same time, will be rejected.
- If a node that is joining the cluster dies, the coordinator will notice and abort the join automatically.
In a nutshell, our main achievement is that topology changes will be safe and fast: we won’t be bound by ring delay any longer, and operator mistakes won’t corrupt the cluster.