The Data Modeling Behind Social Media “Likes”
Did you ever wonder how Instagram, Twitter, Facebook, and other social media platforms track who liked your posts? This post explains how to do it with ScyllaDB NoSQL.
Recently, I was invited to speak at an event called “CityJS.” But here’s the thing: I’m the PHP guy. I don’t do JS at all, but I accepted the challenge. To pull it off, I needed to find a good example to show how a highly scalable and low latency database works.
So, I asked one of my coworkers for examples. He told me to look for high numbers inside any platform, like counters or something like that. At that point, I realized that any type of metrics can fit this example. Likes, views, comments, follows, etc. could be queried as counters. Here’s what I learned about how do proper data modeling for these using ScyllaDB.
First things first, right? After deciding what to cover in my talk, I needed to understand how to build this data model.
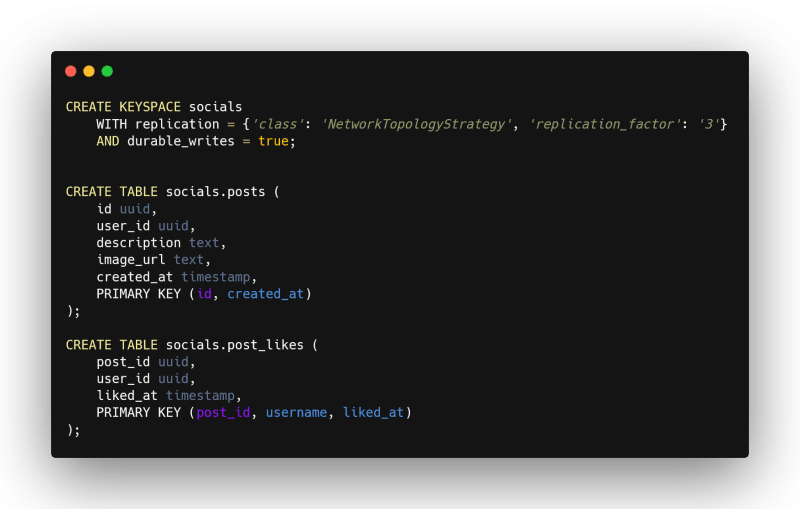
We’ll need a posts table and also a post_likes table that relates who liked each post. So far, it seems enough to do our likes counter.
My first bet for a query to count all likes was something like:
Ok and if I just do a query with
SELECT count(*) FROM social.post_likesit can work, right?
Well, it worked but it was not as performant as expected when I did a test with a couple thousands of likes in a post. As the number of likes grows, the query becomes slower and slower…
“But ScyllaDB can handle thousands of rows easily… why isn’t it performant?” That’s probably what you’re wondering right now.
ScyllaDB – even as a cool database with cool features – will not solve the problem of bad data modeling. We need to think about how to make things faster.
Researching Data Types
Ok, let’s think straight: the data needs to be stored and we need the relation between who liked our post, but we can’t use it for count. So what if I create a new row as integer in the posts table and increment/decrement it every time?

Well, that seems like a good idea, but there’s a problem: we need to keep track of every change on the posts table and if we start to INSERT or UPDATE data there, we’ll probably create a bunch of nonsense records in our database.
Using ScyllaDB, every time that you need to update something, you actually create new data.
You will have to track everything that changes in your data. So, for each increase, there will be one more row unless you don’t change your clustering keys or don’t care about timestamps (a really bad idea).
After that, I went into the ScyllaDB docs and found out that there’s a type called counter that fit our needs and is also ATOMIC!
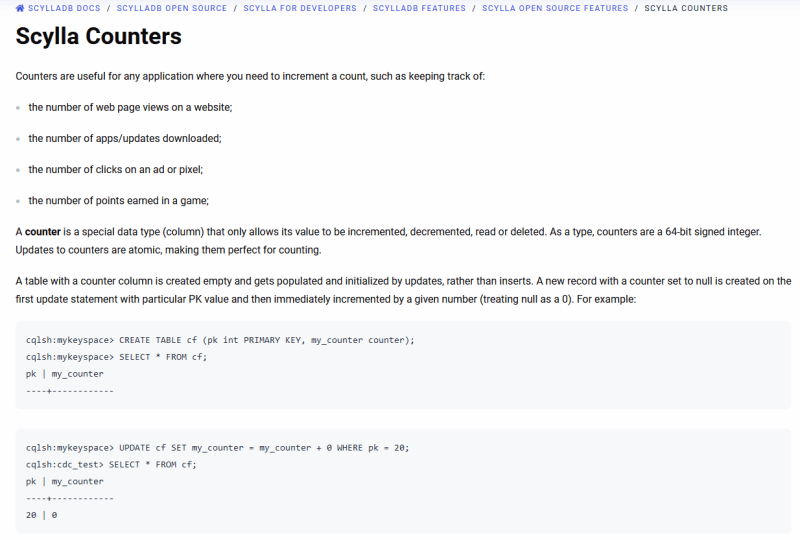
Ok, it fit our needs but not our data modeling. To use this type, we have to follow a few rules but let’s focus on the ones that are causing trouble for us right now:
- The only other columns in a table with a counter column can be columns of the primary key (which cannot be updated).
- No other kinds of columns can be included.
- You need to use UPDATE queries to handle tables that own a counter data type.
- You only can INCREMENT or DECREMENT values, setting a specific value is not permitted.
This limitation safeguards correct handling of counter and non-counter updates by not allowing them in the same operation.
So, we can use this counter but not on the posts table… Ok then, it seems that we’re finding a way to get it done.
Proper Data Modeling
With the information that counter type should not be “mixed” with other data types in a table, the only option that is left to us is create a NEW TABLE and store this type of data.
So, I made a new table called post_analytics that will hold only counter types. For the moment, let’s work with only likes since we have a Many to Many relation (post_likes) created already.

These next queries are what you probably will run for this example that we created:
Now you might have new unanswered questions in your mind like: “So every time that I need a new counter related to some data, I’ll need a new table?” Well, it depends on your use case. In the social media case, if you want to store who saw the post, you will probably need a post_viewers table with session_id and a bunch of other stuff.
Having these simple queries that can be done without joins can be way faster than having count(*) queries.

Me on the CityJS stage talking about data modeling using Typescript