ScyllaDB’s New IO Scheduler

As any other computational resource, disks are limited in the speed they can provide. This speed is typically measured as a 2-dimensional value measuring Input/Output Operations per Second (IOPS) and bytes per second (throughput). Of course these parameters are not cut in stone even for each particular disk, and the maximum number of requests or bytes greatly depends on the requests’ distribution, queuing and concurrency, buffering or caching, disk age, and many other factors.
So when performing IO a disk must always balance between two inefficiencies — overwhelming the disk with requests and underutilizing it.
Overwhelming the disk should be avoided, because when the disk is full of requests it cannot distinguish between the criticality of certain requests over others. All requests are of course, important, yet we care more about latency sensitive requests. For example, Scylla serves real time queries that need to be completed in single digit milliseconds or less and, in parallel, Scylla processes terabytes of data for compaction, streaming, decommission and so forth. The former have strong latency sensitivity. The latter are less so. The task of the I/O scheduler is to maximize the IO bandwidth while keeping latency as low as possible for latency sensitive tasks. The former IO scheduler design, implementation and priority classes are described here, in this blog we will cover the enhancements of the new scheduler to improve its performance in environments where IO is a bottleneck or work is unbalanced.
In case of Seastar the situation with not overwhelming the disk is additionally complicated by the fact, that Seastar doesn’t do IO directly with the disk, but instead it talks to an XFS filesystem with the help of the Linux AIO API. However the idea remains the same: Seastar tries hard to feed the disk with as many requests as it can handle, but not more than this. (We’ll put aside all the difficulties defining what “as much as it can” means for now.)
Seastar uses the “shared nothing” approach, which means that any decision made by CPU cores (called shards) are not synchronized with each other. In rare cases, when one shard needs the other shard’s help, they explicitly communicate with each other. Also keep in mind that Seastar schedules its tasks at the rate of ~0.5 ms, and in each “tick” a new request may pop up on the queue.
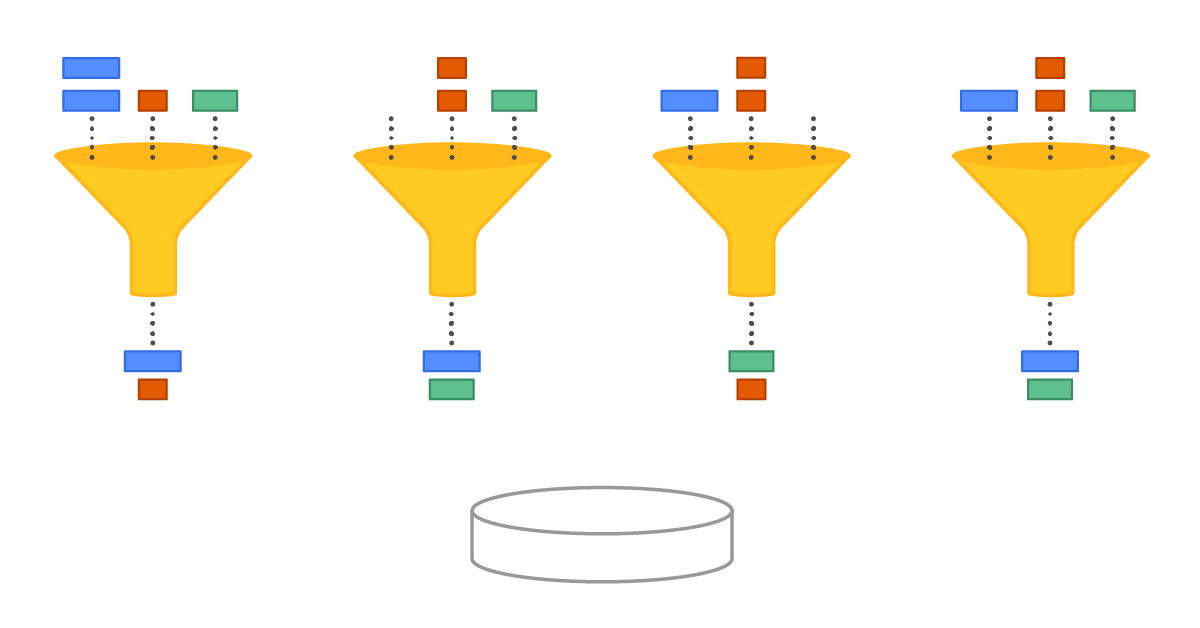
A conceptual model of Seastar’s original IO Scheduler. Different tasks are represented by different colors, rectangle length represents the IO block length
When a sharded architecture runs the show the attempt not to overwhelm the disk reveals itself at an interesting angle. Consider a 1GB/s disk on a 32-shard system. Since they do not communicate with each other, the best they can do in order not to overwhelm the disk, and make it ready to serve new requests within 0.5 ms time-frame is to submit requests that are not larger than 16k in size (the math is 1GB/s divided by 32 hards, multiplied by 0.5ms).
This sounds pretty decent, as the disk block is 512-4096 bytes, but in order to achieve the maximum disk throughput one ought to submit requests of 128k and larger. To keep requests big enough not to underutilize the disk but small enough not to overwhelm it, shards should communicate, and according to sharded design this was solved by teaching shards to forward their requests to other shards. On start some of them were allowed to do IO for real and were called “IO-coordinators”, while others sent their requests to these coordinators and waited for the completion to travel back from that shard. This solved the overwhelming, but led to several nasty problems.
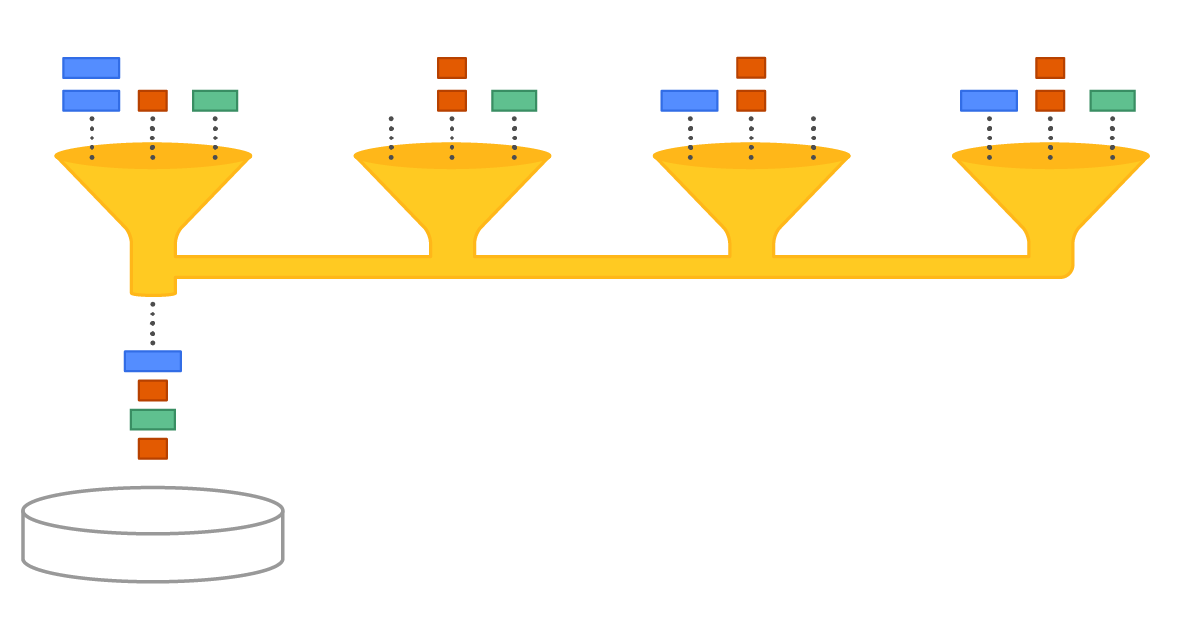
Visual representation of a CPU acting as an IO coordinator
As non-coordinator shards use the Seastar cross-shard message bus, they all get unavoidable latency tax roughly equal to the bus’ round-trip time. Since the reactor’s scheduling slice is 0.5ms, in the worst case this value is 1ms, which is well comparable with the 4k request latency on modern NVMe disks.
Also, with several IO coordinators configured the disk becomes statically partitioned. So if one shard is trying to do IO-intensive work, while others are idling, the disk will not work at its full speed, even if large requests are in use. This, in turn, can be solved by always configuring a single IO coordinator regardless of anything, but this raises the next problem to its extreme.
When a coordinator shard is loaded with offloaded IO from other shards, in the worst case the shard can spend the notable amount of its time doing IO thus slowing down its other regular activities. When there’s only one CPU acting as an IO coordinator, this problem reveals itself at its best (or maybe worst).
The goal of the new scheduler is to kill two birds with one stone — to let all shards do their own IO work without burdening one CPU with it predominantly, and at the same time keep the disk loaded according to the golden rule of IO dispatching: “as much as it can, but not more than this.” (A variant of Einstein’s apocryphal expression.) Effectively this means that shards still need to communicate with each other, but using some other technique, rather than sending Seastar messages to each other.
Here Come the IO Groups
An IO group is an object shared between several shards and where these shards keep track of the capacity of a disk. There can be more than one group in the system, but more on this later. When a shard needs to dispatch a request it first grabs the needed fraction of the capacity from the group. If the capacity requirement is satisfied, the shard dispatches, if not, it waits until the capacity is released back to the group, which in turn happens when a previously submitted request completes.
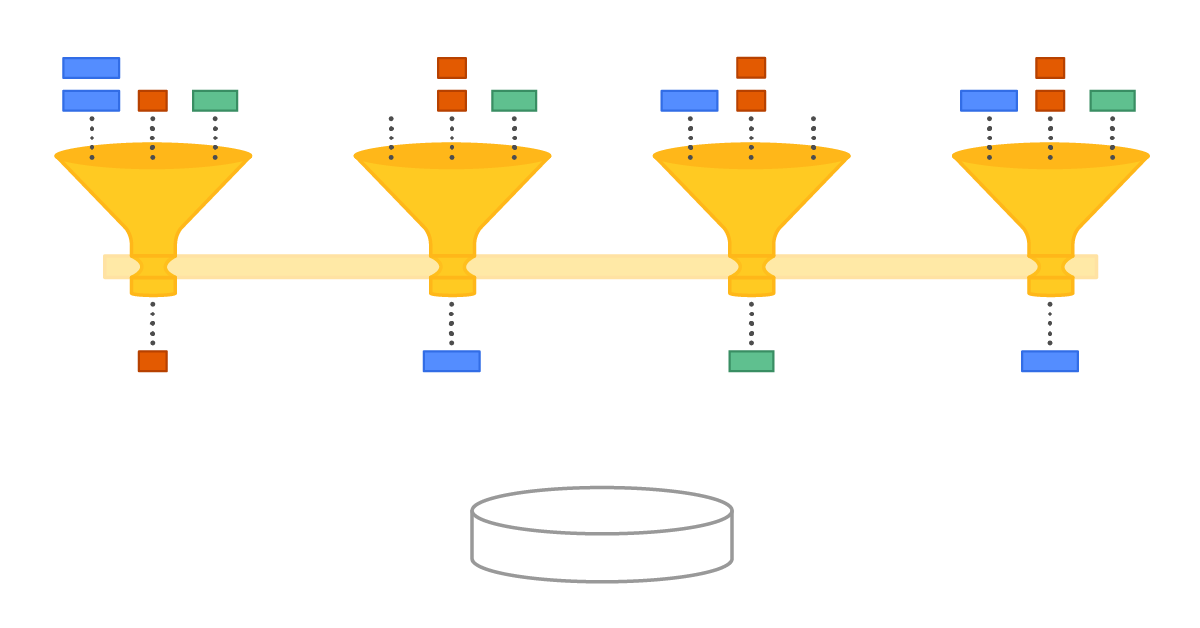
IO groups ensure no one CPU is burdened with all IO coordination. The different CPUs intercommunicate to negotiate their use of the same shared disk
An important option of the new algorithm is “fairness”, which means that all shards should have equal chances to get the capacity they need. This sounds trivial, but simple algorithms fail short on this property, for example early versions of Linux had a simple implementation of a spinlock, which suffered from being unfair in the above sense, so the community had to re-implement it in a form of a ticket-lock.
A Side Note
The simplest way to implement the shared capacity is to have a variable on the group object that’s initialized with a value equal to the disk capacity. When a shard needs to grab the capacity it decrements the value. When it returns the capacity back it increments it back. When the counter becomes negative, this denotes the disk is over dispatched and the shard needs to wait. This naive approach, however, cannot be fair.
Let’s imagine a group with the capacity of 3 units and three shards all trying to submit requests with weights of 2 units each. Apparently, these requests cannot be submitted altogether so one shards wins the race and dispatches, while two other shards have to wait.
Now how would this “wait” look like? If both shards should poll the capacity counter until it becomes at least 2, they can do it forever. Likely the shards need to “reserve” the capacity they need, but again, with a plain counter this won’t just work. Even if we allow this counter to go negative, denoting the capacity starvation, from the example above, if both subtract 2 from the counter, it will never become larger than -1 and the whole dispatching will get stuck. We’ll refer to this as the increment/decrement (“inc/dec”) waiting problem.
Capacity Rovers
The algorithm that worked for us is called “capacity rovers” and it resembles the way TCP controls the congestion with the help of a sliding window algorithm. A group maintains two values called tail rover and head rover. They are initialized with respectively zero and the “disk capacity” values. When a shard needs to dispatch a request it increments the tail rover and, if it’s still less than the head, dispatches. When the request finishes it increments the head rover. All increments, of course, happen with the help of atomic instructions.
The interesting part of the algorithm is what a shard does if after incrementing the tail rover value happens to be larger than the head one, in the code it’s called “ahead of”. In this case the disk current usage vs capacity doesn’t allow for more requests and the shard should wait and that’s where the naive inc/dec waiting problem is solved.
First of all, a shard will be allowed to dispatch when the disk capacity will allow for it, i.e. when the head counter will be again ahead of the tail. Note, that it can be ahead by any value, since the capacity demand had already been accounted for by incrementing the tail rover. Also, since all shards only increment the tail rover, and never decrement it, they implicitly form a queue — the shard that incremented the tail counter first may also dispatch first. The waiting finishes once the head rover gets ahead of the tail rover value that a shard saw when incrementing it. The latter calls for increment-and-get operation for an integer, but it’s available on all platforms.
One may have noticed that both tail and head rovers never decrement and thus must overflow sometime. That’s true and there is no attempt to avoid the overflow; it is welcomed instead. To safely compare wrapping rovers signed arithmetics are used. Having a Linux kernel development background I cannot find a better example of it as Linux jiffies. Of course this wrapping comparison only works if all shards check the rovers not more rarely than they overflow. At current rates this means the shard should poll its IO queues every 15 minutes or more often, which is a reasonable assumption.
Also note the shared rovers require each shard to alter two variables in memory with the help of atomic instructions, and if some shard is more lucky accessing the memory cells than another it may get the capacity more easily. That’s also true and the primary reason for such asymmetry is NUMA machines — if there’s only one IO group for the whole system, then shards sitting in the same NUMA node as the group object’s memory is allocated on will enjoy faster rovers operations and, likely, more disk capacity devoted to them.
To mitigate this, IO groups are allocated per NUMA node which, of course, results in static disk partitioning again, but this time the partitioning comes at larger chunks.
As a result, we now have a scheduler that allows all shards to dispatch requests on their own and use more disk capacity than they could if the system was partitioned statically. This improves the performance for imbalanced workloads and opens up a possibility for another interesting feature called “IO cancellation,” but that’s the topic for another post.
From a performance perspective, it will take some effort so see the benefits. For direct experiments with an IO scheduler there’s a tool called io_tester that lives in a Seastar repository.
The most apparent test to run is to compare the throughput one shard can achieve on a multi-shard system. The old scheduler statically caps the per-shard throughput to 1/Nth of the disk, while the new one allows a single shard to consume all the capacity.
Another test to run is to compare the behavior of the uniform 4-k workload on both the old scheduler with 1 coordinator (achieved with the –num-io-queues option) and the new one with the help. If checking the latency distributions, it can be noted that the new scheduler results in more uniform values.
Now Available
You can immediately start to benefit from our new IO Scheduler, which was released in Scylla Open Source 4.4. If you’d like to ask more questions about the IO Scheduler, or using Scylla in general, feel free to contact us directly, or join our user community in Slack.