Contact Us
Contact Us
Read More
10 results found
Featured
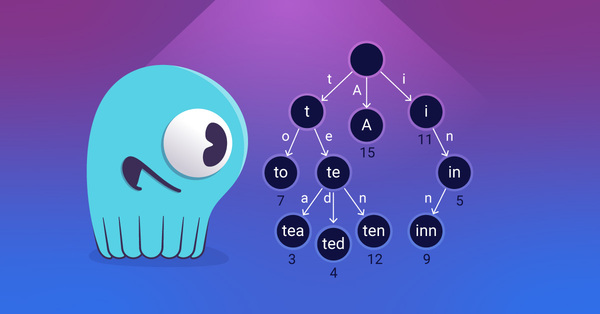
How ScyllaDB's Trie-Based Index Delivers Up to 3X More Throughput - ScyllaDB
Featured
Riding the Raft to Strong Consistency in ScyllaDB - ScyllaDB
Featured
Automate ScyllaDB X Cloud Clusters with Terraform - ScyllaDB
Featured
Cutting P99 Latency 1000X During Connection Storms by Hardening ScyllaDB Admission Control - ScyllaDB
Featured
“Key-Value” is Misleading. Access Patterns are Key. - ScyllaDB
Featured
Introducing ScyllaDB Agent Skills - ScyllaDB
Featured
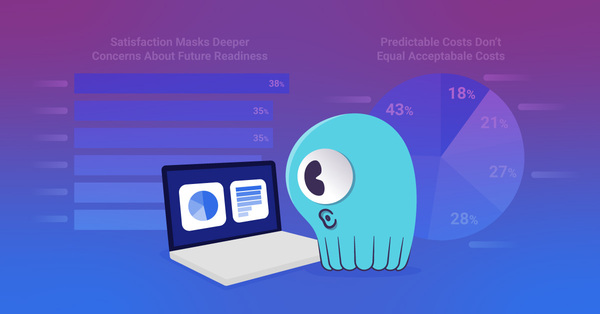
New Research on Cloud Database Trends: Technical Risks, Cost Pressures, and Migration Triggers - ScyllaDB
Featured
Native Vector Search for the DynamoDB API - ScyllaDB
Featured
ScyllaDB Elastic Scaling in Action [Demo] - ScyllaDB
Featured
ScyllaDB X Cloud: Your Questions Answered - ScyllaDB
Featured