How Strava’s NoSQL Move Keeps Athletes Moving

Speed. Power. Efficiency. They’re all critical for Strava’s active user base as well as the company’s underlying databases. And they’re also fitting descriptors for Strava Senior Cloud Engineer Phani Teja Nallamothu’s recent ScyllaDB Summit keynote, “ScyllaDB at Strava.”
Browse ScyllaDB Summit On-Demand
Phani Teja kicked it off by introducing Strava, the largest sports community in the world. Strava’s platform enables 100M+ athletes across 195 countries to connect and compete by sharing data collected via 400+ types of devices throughout the day. As Phani Teja put it, “Strava is an integral part of every phase of an athlete’s life: indoor training, outdoor training, recovery, and even sleep.” In terms of the Strava platform, this involves segment tracking, matched runs & rides, performance metrics, route discovery, and heat maps for 30+ types of activities – and then tapping into all the data to orchestrate group challenges, clubs, and leaderboards.
The platform is architected as follows:
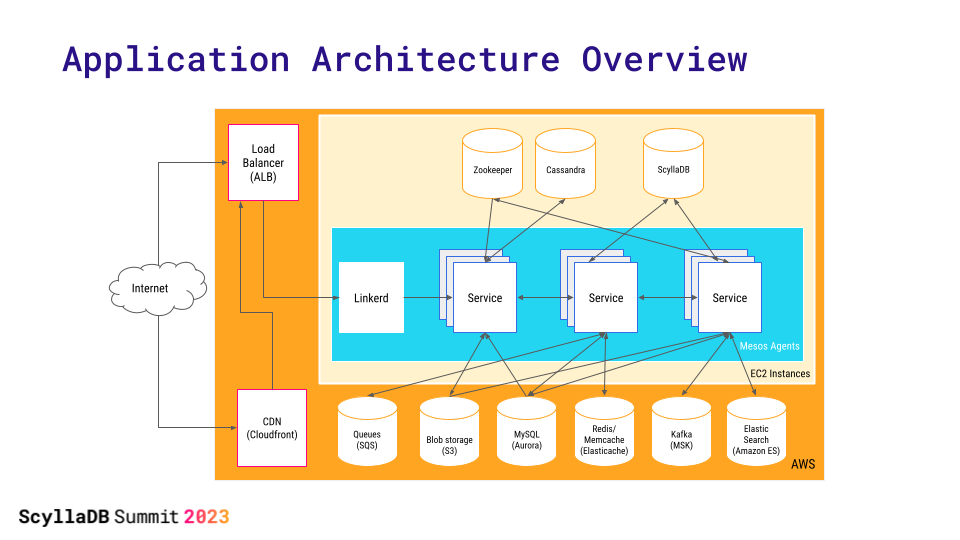
- Incoming internet requests either hit the load balancer directly (if data is not already cached) or arrive there via the Cloudfront CDN (if data has been cached, or needs to be cached for future requests).
- The load balancer routes requests to a Linkerd service mesh, which handles all the authentication, authorization, and request routing.
- From there, requests go to microservices, which – like Linkerd – are fully hosted on AWS EC2 instances. Apache Mesos is used to manage all the microservices containers.
- The next stop is (potentially) another microservice, then a data store. Strava uses a wide variety of data stores for different aspects of the platform; for example, Amazon RDS, MySQL, Redis, Memcached, (still) a few Cassandra clusters, and (now) many ScyllaDB clusters.
Phani Teja then zoomed in on a few of the use cases they recently moved from Cassandra to ScyllaDB. First up, “Horton”: a flexible scalar value store for activity data such as distance, max/avg speed, max/avg heart rate, bikeID, shoeID, and so on.
The sample schema for this use case looks like this:
![]()
This schema, with athlete_id as the clustering key, enables them to:
- Efficiently access all of a specific athlete’s activities from a single node
- Get all values for an activity with a single activity lookup
- Perform range lookups that aggregate metrics (such as distance, time, and elevation gain) across multiple activities
Phani Teja then offered a peek at two of Strava’s other ScyllaDB use cases:
- Segments: A write-heavy use case that stores athletes’ progress reports on segments and loads them into their feeds
- Neogeo: A read-heavy (with a fair volume of writes) use case that stores encoded map styles for static images
To conclude, Phani Teja shared why they started moving use cases from Cassandra to ScyllaDB, and how it’s helped them so far:

In Phani Teja’s words:
“We’ve observed an increase in throughput after migrating to ScyllaDB. We have experienced consistently low latencies in ScyllaDB clusters which were not possible with Cassandra. Whenever there is a Garbage Collection (GC) pause in Cassandra, all reads and writes have to wait until the GC is done. This caused significant performance issues. There are no GC pauses in ScyllaDB. We serve over 100 million athletes, so we want our platform to be highly available – all the time. ScyllaDB achieves that. We can also achieve the same performance with fewer nodes, thereby reducing the admin costs and the operational complexity.”
You can watch 25+ more tech talks by expert engineers from Epic Games, ShareChat, Discord, iFood, SecurityScorecard, Proxima Beta, ScyllaDB, and more at the ScyllaDB Summit on-demand site.