Cutting Recommendation Engine Latencies by Migrating from MongoDB & PostgreSQL
Learn how Pinhome Engineering achieved 60% cost reduction, with 97% lower latency and 90% storage savings
As Pinhome, (Indonesia’s largest property transaction platform) continues to grow rapidly, we’re committed to improving the user experience and staying ahead of the competition. To achieve this goal, we’re focusing on the importance of user engagement and simplifying the exploration process. One way we’re doing this is by implementing a recommendation engine in our application.
A recommendation engine allows us to analyze user behavior and provide tailored suggestions for products and services. By doing so, we can simplify the exploration process for our users and increase user interaction with our application, ultimately leading to greater user satisfaction.
Since we have limited resources and time, we’re focused on building a fast and reliable recommendation engine in an MVP way. We’re taking a strategic approach to development by decoupling several steps and workarounds into independent concurrent asynchronous jobs and events running in the background.
Our approach is based on solving key problem sets such as optimizing algorithms for generating recommendations, minimizing latency by using efficient data structures and caching techniques, and ensuring fault tolerance. By doing so, we can process large amounts of data efficiently, provide real-time personalized suggestions to users, and meet the core needs of our users in a cost-effective way. We focus on these problems set:
- Gathering data to be analyzed
- Processing and analyzing the data
- Serving a post processed data to be consumed
Despite the challenges that come with building a recommendation engine in an MVP way, we’re confident that our strategic approach will help us develop a recommendation engine that provides a competitive advantage for our company while ensuring a great user experience.
Problem
This simple diagram shows the big picture of our recommendation engine’s previous architecture. We used a relational database and a NoSQL document store database to store all data needed, the event data, processed recommendations data and so on. We used Postgresql within Google CloudSQL as the relational SQL database to store post-processed data, and we used MongoDB as a NoSQL document store for storing gathered event or activity data.
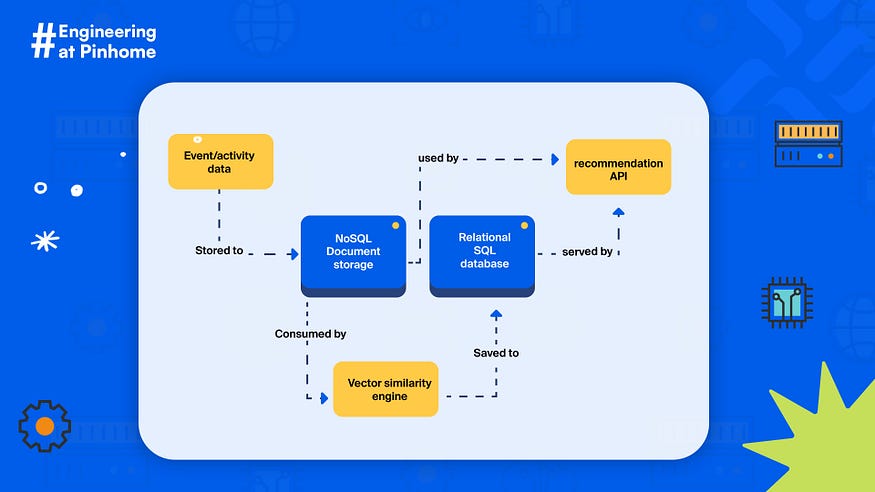
As our user base continues to grow rapidly, we see a significant increase in web traffic requests. Unfortunately, our previous technology stack struggled to keep up, and we experienced degraded performance with our recommendation engine. This led to service instability and inaccurate recommendation results. As a result, we explored new technologies to help us scale our platform and provide a better user experience.
Solution
After evaluating various options to replace MongoDB and PostgreSQL (cache storage) for the recommendation engine, we decided to switch to ScyllaDB. During the evaluation process, we found that ScyllaDB offered superior performance and scalability compared to the databases we used before, as well as compared to Cassandra (which we considered as another option). With ScyllaDB, we could handle a larger volume of data and requests while still maintaining fast response times. This not only improved the stability of our recommendation engine but also allowed us to provide more accurate recommendations to our users.
Result and Analysis
We’re excited to keep using ScyllaDB as we grow our business and enhance user experience. To make things simpler, we’ve decided to restructure our infrastructure, as illustrated in the diagram below:
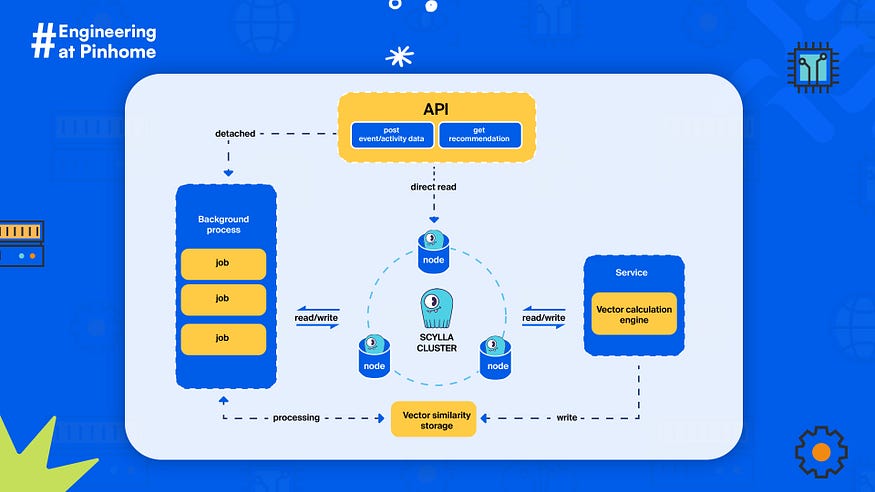
By consolidating our storage infrastructure and switching to ScyllaDB, we were able to achieve significant cost savings. We were pleasantly surprised to discover that for the same cost as our previous document-based NoSQL storage solution, we were able to deploy a node cluster with higher specifications for each node.
Our primary focus in this migration was to improve the performance of our recommendation engine, and the results exceeded our expectations. We have three endpoints that are responsible for serving and processing recommendations, and all of them have shown significant performance improvements since the switch to ScyllaDB.
Impact
On the codebase itself, we reduced code complexity on querying and storing user event data. After using ScyllaDB, we were able to design a bucket model through the document-based NoSQL storage, since it was modeled as a time-series data model.
The most important impact was seen on the performance level. We have 3 critical components as an API to handle most actions of the recommendation engine, such as pre-populating, constructing pre-calculated data and delivering a result. Previously, we had 2 APIs that had a high read throughput process and traffic, as can be seen in the graph below:
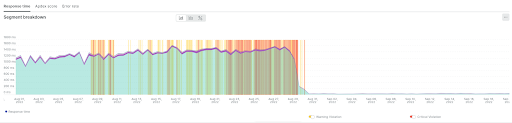
After switching to ScyllaDB, the API became 42x faster with 97%+ lower latency.
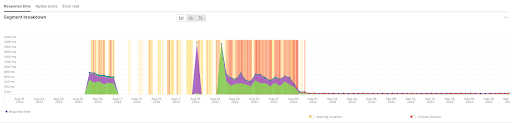
The API on the metric above became 23x faster with 95%+ lower latency.
Now let’s look at an API with high write throughput:

The API on the metric above became 9x faster with 89%+ lower latency.
Cost-wise, with the same cost average of document-based NoSQL storage that we previously used, we got almost 2x resource infrastructure specification increment and more than 40x faster performance with a 97%+ latency reduction.
Our new approach not only reduced the latency and increased the performance, it also eliminated a lot of problems that occurred previously. These problems are marked by the yellow and red lines shown on all of the graphs above. The occurrence of the yellow and red lines indicates the degradation of performance and user experience through the recommendation.
On the infrastructure side, we saved a lot of storage size by only storing the latest version of the user processed data AI model. This is convenient as previously we weren’t able to clean up or permanently delete data on PostgreSQL because it was not designed to have high Write-Delete execution due to its nature.
Summarizing the cost over optimization that we have, we can conclude that after using ScyllaDB, we achieved almost 60% cost reduction, with 97% decreased latency and 90% storage savings.

We were also pleasantly surprised to find that even several months after migrating to ScyllaDB, we have not experienced any issues with our cluster. Not a single CPU load spike, lack of memory, or performance degradation.